[A.I.] 統計モデルと学習の数理
人工知能学会誌 Vol.19 No.6(2004-11) の特集。統計モデルの意味論というか、オントロジーとの関連を知りたいなあと思う。統計データからの知識を抽出する方法という観点からは、文書における単語頻度も意味があるが、単語の有無の組み合わせで判定する従来の検索手法との違いがどの程度あるのかということになる。単語頻度をカウントするスコープの問題もあるだろうと思われる。文書全体を数えるのか、章か、節か、項か、段落か、文か、文節か。文の類似性を計算する方法が必要ではないかという気もする。単語の並びも重要ということになる。既に単語連鎖について言語的特徴としての統計的な研究はある。
GETAは使わせてもらって、いろいろと経験を積みたいと思う。まずは WAM library module for perl を研究しよう。
[A.I.] 健やかな知能
養老孟司先生の特別講演のタイトル。第18回人工知能学会全国大会で95分ビデオ収録されたものがストリーミング配信されている。人工知能学会会員しか見れないが、大変興味深いものであった。
実世界のリンゴは the apple であり、脳の中にあるリンゴは an apple である。実世界のリンゴは一つとして同じものはない。概念としてのリンゴは共通のものである。理解するとは共通了解である。
個性を伸ばそうとかいうのはおかしい。個性は身体に元々備わっているものである。脳にあるもの、心には個性がない。心は共通了解であり、共感である。まねをする教育が重要である。まねをしていくとまねができないところで違いがわかり、等々。池田満寿夫の「模倣と創造」が頭に浮かんだ。引っ張り出して読み返すと、辞書の定義の「・・・意味を総合すると、・・・、模倣は自然の摂理であり」、「すべての創造は模倣から出発する」とあった。
大変おもしろい話が続く。ふーむ、なるほど、話としては明確に出なかったが、共通了解の基盤に言語がある。英語の冠詞の役割を果たすのは、日本語では助詞である。
だいぶ以前に2003/05/06: 視覚化の自動化で紹介したGraphvizをLinuxマシンにインストールして、パッチを当てて日本語を使えるようにしようと思って調べだしたら、WinGraphvizを見つけてしまった。SJISが使える。Linuxマシンへのインストールは中止して、こちらをWindowsマシンにインストールしてみた。
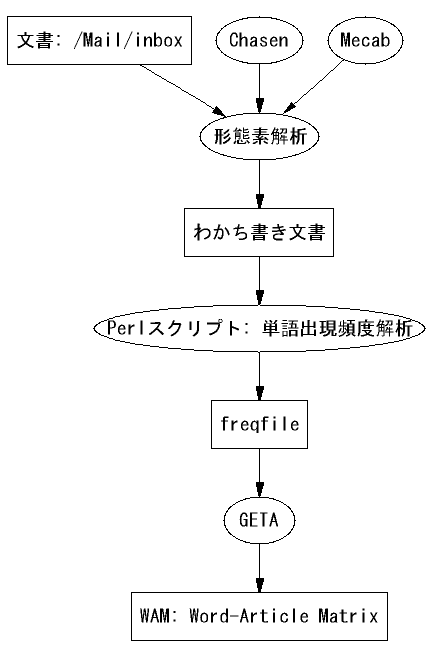 WinGraphviz出力例
WinGraphviz出力例
Perlなどを使ってPNGファイルなどとして出力可能である。素晴らしいものだ。ビジュアル化のための強力なツールが手に入ったことになる。CGIにも当然使えるので、利用範囲は広いだろう。上記の図の例は、次のようなスクリプトを使った。デフォルトのフォントは「MS ゴシック」だ。fontname属性で他のフォントも選択可能である。WinGraphvizの実体はWinGraphViz.dllで、WINDOWS\SYSTEM32のフォルダにインストールされる。cabファイルでインストールした場合は自分でレジストリに登録する必要がある。
use Win32::OLE;
$objDOT = new Win32::OLE "WinGraphviz.DOT";
$strCMD = "digraph G {1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7;
8 -> 2;
9 -> 2;
1 [label=\"文書: /Mail/inbox\",shape=polygon,sides=4];
2 [label=\"形態素解析\"];
3 [label=\"わかち書き文書\",shape=polygon,sides=4];
4 [label=\"Perlスクリプト: 単語出現頻度解析\"];
5 [label=\"freqfile\",shape=polygon,sides=4];
6 [label=\"GETA\"];
7 [label=\"WAM: Word-Article Matrix\",shape=polygon,sides=4];
8 [label=\"Chasen\"];
9 [label=\"Mecab\"];
}";
$objPNG = $objDOT->ToPNG($strCMD);
$objPNG->Save("geta.png");
[Computing] Graphvizのフォントサイズの変更
字がどうも大き過ぎる。文字サイズの制御はどうするのか。fontsize=10 とした場合の出力。
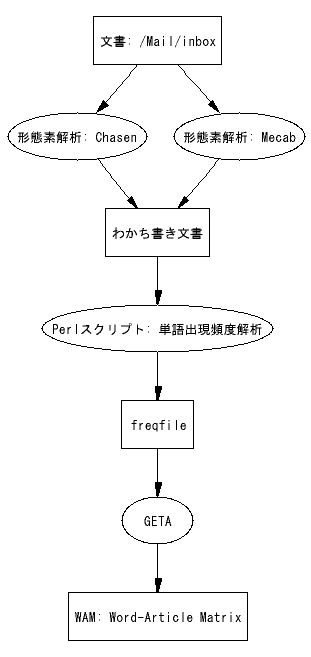
fontsize=10のWinGraphviz出力例 [Modified: 2004-11-09]
一応、スクリプトも載せておこう。ロジックもおかしいので変更。subgraphを使おうと思ったが、思ったように動かない・・・[Added: 2004-11-09]
use Win32::OLE;
$objDOT = new Win32::OLE "WinGraphviz.DOT";
$strCMD = "digraph G {
1 -> 8 -> 3;
1 -> 9 -> 3;
3 -> 4 -> 5 -> 6 -> 7;
1 [label=\"文書: /Mail/inbox\",fontsize=10,shape=polygon,sides=4];
3 [label=\"わかち書き文書\",fontsize=10,shape=polygon,sides=4];
4 [label=\"Perlスクリプト: 単語出現頻度解析\",fontsize=10];
5 [label=\"freqfile\",fontsize=10,shape=polygon,sides=4];
6 [label=\"GETA\",fontsize=10];
7 [label=\"WAM: Word-Article Matrix\",fontsize=10,shape=polygon,sides=4];
8 [label=\"形態素解析: Chasen\",fontsize=10];
9 [label=\"形態素解析: Mecab\",fontsize=10];
}";
$objPNG = $objDOT->ToPNG($strCMD);
$objPNG->Save("geta2.png");
[Computing] Graphvizのsubgraph
ようやく意図どおりに動いた。結局、subgraph clusterA には矢が引けないみたい。
GraphvizはUMLを記述したり、他のグラフ言語をグラフ化して表示するのに使えるはず。
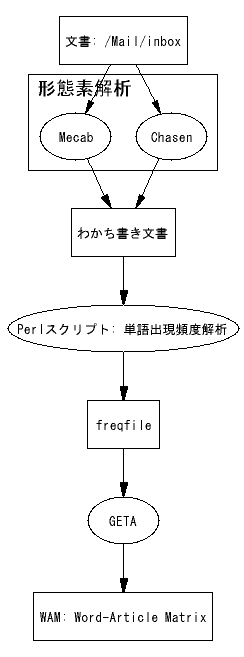
subgraphを含むグラフの出力例
use Win32::OLE;
$objDOT = new Win32::OLE "WinGraphviz.DOT";
$strCMD = "digraph G {
1 [label=\"文書: /Mail/inbox\",fontsize=10,shape=polygon,sides=4];
subgraph clusterA {
label=\"形態素解析\";
8 [label=\"Chasen\",fontsize=10];
9 [label=\"Mecab\",fontsize=10];
}
3 [label=\"わかち書き文書\",fontsize=10,shape=polygon,sides=4];
4 [label=\"Perlスクリプト: 単語出現頻度解析\",fontsize=10];
5 [label=\"freqfile\",fontsize=10,shape=polygon,sides=4];
6 [label=\"GETA\",fontsize=10];
7 [label=\"WAM: Word-Article Matrix\",fontsize=10,shape=polygon,sides=4];
1 -> 8 -> 3;
1 -> 9 -> 3;
3 -> 4 -> 5 -> 6 -> 7;
}";
$objPNG = $objDOT->ToPNG($strCMD);
$objPNG->Save("geta3.png");
[Computing] 知識循環型データベース
知識循環型データベースは橋田浩一さんのアイデアで、作成者と利用者が一致しているようなデータベースを意味する。自らデータベースを育てながら、使い込むにしたがってより便利になるようなものだ。この更新日記もそのようなものであるし、実践実用Perlで開発した「メモる」システムもそのようなものである。パーソナルではあるけれども。
更新日記検索と「メモる」システムの連動を考えて、renewal_r.cgiとmemol_edit.cgiをバージョンアップしている。これらのCGIはデスクトップで動作し、Web上の更新日記を検索して、検索結果を「メモる」システムのメモ作成CGIとリンクさせて表示する。必要であれば検索結果についてのメモが半自動で作成できる。
更新日記-「メモる」システムの問題は外部の目に晒される更新日記はある程度まじめに書くが、メモのほうはおざなりになることである。もう一つの問題は、現システムでは時系列が基本にあるために体系的な記述に弱いことだ。Wiki的なシステムを組み込めばよいのかもしれない。さらにもう一つの問題はすべてをHTMLで保持する仕組みにあるかもしれない。HTMLでは意味的な構造を多様化させる方向に発展させにくいかもしれない。dml/memolでHTML化を支援する仕組みだけでは物足りなくなってきた。次のステップを考えよう。AdenineかN3記法か、GDAか。GDA(Global Document Annotation: 大域文書修飾)も橋田さんのところのプロジェクトだ。GDAのアノテーションは相当細かいから、形態素解析をして自動的にある程度のタグ付けをする必要があるだろう。「アノテーションによる知的生産支援」というppt資料は刺激的な内容である。GDAタグをどのように利用するのかは問題ではあるので、GDAについてはよく考えてからかも。
[Computing] カメレオン的変態ブラウザ
マイクロソフト、Avalonのコミュニティプレビューを開発者に公開を読んで。
インターネットにアクセスするのは、Webブラウザか、OSアプリケーションかということになるのだが。「データを作り出すものはOfficeなどのOSアプリケーションになり、データにアクセスし表示するものはWebブラウザになる」というのが現在の流れである。マイクロソフトのやろうとしていることは、Webとデスクトップの融合である。マイクロソフトはXAMLを使ってデスクトップ上でカスタマイズしたWebブラウジング環境を作り出せるようにしようとしているらしい。MozillaはXULを使って、Webブラウザ上でデスクトップの機能を拡張して融合を進めている。Webブラウザ上で融合させるか、デスクトップで融合させるかの違いがある。
私は、Webブラウザ側で統合するほうがスマートだと思う。一々、特定のものを見るためにアプリケーションを別に立ち上げるのは面倒だからだ。URLを変えるだけで、ブラウザ自身がカメレオンのように変態するというのが今後の方向性だろう。そして、見せる側と見る側の両方から、それぞれ見せ方、見方をコントロールできるようになるのが便利だろう。無論、見る側が最終的な見方の決定権を持つということになる。
[Computing] Graphvizの束縛ランクを持つグラフ
dotユーザーズマニュアルの図9-10を元にして、文書の引用関係をグラフ化する実験を行った。大変おもしろくて素晴らしい。引用関係のグラフ化は文書のグループ分けや内容の変遷の把握に有効な手法である。データのフォーマットを考えれば、Graphvizのdotスクリプトを自動的に生成することも可能だ。
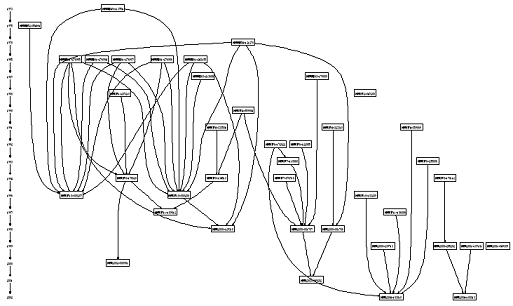
WinGraphviz with constrained ranks
[日記] GETA: freqfileの生成
200通ぐらいのメールの変換過程を表示させてみると、一応freqfileらしきものが作れているようだ。検証が不十分だが。
#!/usr/local/bin/jperl
use Env;
use Jcode;
$temp = "tempmail.txt";
opendir(MAIL,"$HOME/Mail/inbox");
@mails = grep(/^\d+$/,readdir(MAIL));
closedir(MAIL);
foreach $file (sort {$a <=> $b} @mails){
$filepath = "$HOME/Mail/inbox/$file";
open(IN,"$filepath");
open(OUT,"> $temp");
while(<IN>){
if(/^$/){
$vacant++;
}
if($vacant < 1){
$str .= $_;
}elsif($vacant == 1){
$str .= $_;
print OUT jcode($str)->mime_decode->euc;
$str = "";
$bodysw = 1;
next;
}
if($bodysw == 1){
print OUT jcode($_)->euc;
}
}
close(IN);
close(OUT);
$bodysw = 0;$vacant = 0;
print "\@Mail/inbox/$file\n";
open(TEMP,"/usr/local/bin/mecab -Owakati < $temp |");
while(<TEMP>){
@words = split(/\s+/,$_);
foreach $word (@words){
$count{$word}++;
}
}
foreach $word (sort keys %count){
print $count{$word}," ",$word,"\n";
}
%count = ();
close(TEMP);
}
[日記] Spinning the World's Web
Business Week November 8, 2004号の過去75年の偉大な革新者シリーズにTimothy J. Berners-Leeが出ている。Webが登場して10年以上経過した現在でもWebの発明は依然として革新的である。その潜在的可能性のまだ端緒に辿りついたばかりである。W3Cは次々とSementic Webのコンセプトの基盤となるDraftやRecommendationを生み出し続けている。Webはまだそれを表現できるまでに至っていない。しばらくW3Cの後をもたもたと追いかけ続ける状態が続くだろう。Semantic Webはオントロジーなどの哲学、言語学や知識表現、プログラミング言語、人工知能などの分野の先端の成果を統合しつつあるようにも見える。
[日記] Redefining Smart
ビジネスウィークネタその2。Jeff HawkinsのOn Intelligence、How a New Understanding if the Brain Will Lead to the Creation of Truly Intelligent Machinesという本の書評。「記憶にアクセスすることが知能への鍵である。」
GETAなど、文書の類似度や分類などを判定する仕組みの根底にあるのは、単語の出現頻度である。有用な場合はあるにせよ、文書理解には程遠く、あまりにも粗雑な近似であるということもできる。意味のあるものにするためにはかなりのノウハウと経験が必要なのではと思う。それもデータに相当依存するはずである。得られた結果が十分なものかどうかの判定は困難だろう。もっと脳に蓄えられた記憶の仕組みを知るべきなのかもしれない。
[日記] GETA: メールの単語頻度ファイル生成スクリプトの組み込み
増井さんのMakefileに自作のスクリプトを組み込ませてもらって、GETAのmkwでWAM(Word-Article Matrix)を生成してみる。WAMが使えるかどうか動作確認のために、コンパイルできたsearchを使って、Makefileのtestを参考に検索シェルスクリプトを書いた。見事に動く。引数を持つシェルスクリプトの書き方をお勉強。検索文字列はパイプで渡さないとsearchは受け取れない。
#!/bin/bash
GETAROOT=`pwd`
export GETAROOT
echo $1 | bin/search
これで一応の基盤ができたわけで、後は応用問題だ。更新日記をWAM化して検索できるようにしたり、メモをWAM化するなどいろいろ使えるはずだ。GETAが今のところUnixでしか動かないので、現環境ではWindowsとUnixの2台のマシンを統合連携して運用する問題がある。何を使うかな。HTTPを使うのが一番簡単そうだが。うまく動きそうな気はするけど。
[日記] THE POLAR EXPRESS
IMAXからThe Polar Expressの宣伝メールが届いた。一見、銀河鉄道999をアメリカナイズしたイメージ。孤独孤高な夢がカーニバルになってしまう。登場人物もCGで描写される。リアルさは相当のものだが、まだ、本物には見えない。
[日記] ピーちゃんの死とお墓参り
縦書きモード(2004/07/17: 縦書きHTML)、IE only。IE以外は、横書きで表示されるはず。正確には、navigator.appNameの最初の文字が"M"の場合にだけ(出典: KENT著、「Webページ製作テクニック逆引き大全500の極意」、秀和システムのQ.321)、縦書きで表示される。FireFoxで試したら、横書きで正常に表示された。昨日は11月3日のこと。[Modified: 2004-11-07]
昨日の朝
とうとうセキセイインコのピーちゃんが死んだ
前日の夜は触っても体に力がなく
くちばしで手をつつくことなく目を細めた
子供たちが夕方埋葬した
昨日の昼
呉の長浜にある墓地にお参り
台風の爪痕が海際の道路に残っている
前は道路際にある畑だった場所に車を乗り入れ
墓地に登った
高台から眺めるこの付近の海は量感があり
深くて広い
呉が昔、軍港になった理由も海にあるのかもしれないと思った
打ち寄せる波は容赦ない
風が強い日だった
[日記] 禅的生活
玄侑宗久著、「禅的生活」、ちくま新書 445、2003年12月10日第1刷、237ページ、720円。公式サイトはこちら。
女房から、「なぜそんな本買ったきたの。あなたの生活は既に禅的生活みたいな」と言われて、まんざらでもないような。裏表紙の玄侑師の写真を見ると以前NHK教育で瀬戸内寂聴との対談が放映されていたのを思い出した。ああ、あの人か、へーっ小説家でもあるわけだ。ざーっと通して速読してみた。結構読みやすい。一番おもしろかったのはブリゴジンの散逸構造が風流に通じるという話。ゆらぎのある構造が世界を形作る。ゆらぎこそが風流なのである。「ゆらぎ」を楽しむ能力こそ人間の最高度な楽しみなのだそうである。ふらふらとあちこちを彷徨いながら楽しむ。不足さえも楽しめる。次はあれをなんとかしよう。次はこれと・・・
[日記] 更新日記検索とメモるシステムの連動
実践実用Perlサポートページに情報をかなり追加した。サイトをどのようにデザインしていくかが問題だが、まずは1ページが長くなる方向である(^^;)更新日記検索とメモ作成用CGIをバージョンアップした。更新日記検索結果からリンクと日付とタイトルをメモに取得して追記等をすることができるようになる。実は、更新日記の検索データをメモとして取得して、更新日記に再利用するのが当面の目的なのだが、更新日記の編集に直接的に反映させるような仕組みができればもっと面白いかもしれない。
[日記] オライリーのRSSが全滅
なぜか、購読していたO'Reillyの五つのRSSが今日は読めない。RSSのURLをブラウザに入力すると MEERKAT: AN OPEN WIRE SERVICE のページにつながる。システムを変更するならなんらかのアナウンスが欲しいね。何かおかしい。
[日記] SPIDERING HACKS
今日は午後から弥生会館でワーキンググループの最終会議に出席。懇親会を終えて、かなり疲れていたが、エリエール10階のジュンク堂へ。「実践実用Perl」が二冊並んでいた。背表紙が明るい配色なので目立つ。編集者の林さんとデザイナーに感謝しつつ、オライリーの書籍コーナーへ(^^;)
EXCEL HACKSを手に取る。オライリーがEXCELを料理するとどんな具合になるか気になっていたからね。しかし、ExcelはExcelに過ぎない。XMLが読み込めるというのとExcelからWebサービスを使うという情報ぐらいが目新しい話。SpreadsheetMLっていうのがあるらしい。Office 2003 XML Reference Schemasあたりを調べよう。
次に目に止まったのが、SPIDERING HACKS。最後に訳者補として、Perl5.8をShiftJISエンコーディングで使う方法が書いてあるのだが、モジュールにパッチを当てたり、いろいろとノウハウが書いてある。苦労することは間違いないと思うのだが。Perl5.8はUTF-8文字コードでUTF-8が標準の入出力環境で使わないとメリットがないだろう。そうでないと、ありとあらゆる入出力でエンコーディングを意識する必要がある。モジュールを使う場合は、基本的にUTF-8でデータを渡す必要もあるし。とは言え、訳者は村上雅章さんだし、内容的にはAwakening Projectなので、購入。チェックしてみよう。
村上さんは一代前のFAIのシスオペだったのだが、Javaの出始めのFAIのJava講座は最先端にあった。村上さんは、日本で最初のJava本、「かんたんJava」(Hooked on Java, 1996)の訳者でもある。最近FAIを覗くと、村田FAIはとうとうこの九月で閉鎖。Webに進出もなさそうだし、残念。最小二乗法も一種の学習だと村田さんに教わったのは新鮮だった。FAIには長い間お世話になった。FGALsはFGALDCだけがまだ動いている。FGALTSの元?シスオペである私もAirCraftを動かすのは1ヶ月に一度あるかないか。TSNETは200名を越えるメンバー数まで成長したが・・・TSNETはスクリプト言語関連で様々な興味を持つ方が集まっている。そこでみんなで協力して特定の何かを開発するわけではない。情報交換の場である。困ったことがあれば相談できる。興味のある方はご参加を。まあ、それほど活発とはいえないがマイペースが守れるコミュニティである。
あっ、オライリーは回復したみたい。
[日記] 「実践実用Perl」の初書評
BookReview/483991415X、極悪さんのTSNET書評。
ねこ丸さんから極悪さんの書評が出ているとメールをもらった。極めて詳細に評価してもらってうれしい。この本で言いたかった重要な部分は感じ取ってもらえたと思う。rss2html.cgi のミスも見つけてもらった(^^;)トータルのスクリプトとしては問題は出ないはずだが、修正版を作ろうかな。でも一行を移動するだけだし。
# マークアップ記号の実体参照エンコード
sub entities_encode{
my($str) = @_;
$str =~ s/&/&/g;
$str =~ s/</</g;
$str =~ s/>/>/g;
$str =~ s/'/'/g;
$str =~ s/"/"/g;
return $str;
}
上記のように $str =~ s/&/&/g; の行をサブルーチンの最初のほうにもってくるだけ。しかし、今気が付いたけど、'という名前実体参照はないね(^^;)変換されない。あっても害はないが・・・いずれ正誤表を出さないと(^^;)
この本の第7章「統合ポータルの実現」で言いたいのは、Webとローカル(デスクトップ)の情報を同時に取り扱えるのが、ローカルで CGI を動かす最大のメリットであるということである。このような機能を持つ CGI を私は Desktop CGI と呼んでいる。「実践実用Perl」サポートページに置いている「Webとデスクトップの融合」はこのコンセプトを図解したものである。
[日記] 気温の記録
12℃。この秋の最低気温かな。冬が近づく。
[日記] 新プロジェクトに向けて
最近印刷した文献を積み重ねると20-30cmにはなる。本当に読みきれるのかどうかはあやういものだ。Bayesian Network(Koller)、Ontology、GraphViz、TopicMaps、GETA、GDA、PRISM(記号的統計モデル言語、東工大佐藤研)等。Ontologyは哲学から知識表現、Ontology Mapping、OWLまで幅広い内容だ。GETAとGDAは利用技術の検討を進めよう。OntologyはProtegeの利用から実際に使ってみよう。ProtegeはUMLやOWLのプラグインもある。Bayesian NetworkやPRISMについては統計・確率に関する数式表現について勉強が必要だなあ。統計・確率の応用範囲が広がっている。
オリジナルプロジェクトとしては、CGI設定自動化とBBSブラウザについて、XMLの応用を考える予定。
[日記] 17年前の馬鹿の壁
「バカの壁」(2003年)よりだいぶ以前、「脳の中の過程」(哲学書房、1986年)という本に「哲学と理解-馬鹿の壁」という章節がある。この本はちくま文庫に「脳の見方」という題名で1993年に再出版されている。私が読んだのはこちらだ。馬鹿の壁の定義は、「ものが理解できない状態」である。もう20年近く前から「バカの壁」はあったわけだ。養老先生の講演を聴いた後、「バカの壁」を引っ張り出して見ながら気が付いたのは、なあんだ、あの講演は「バカの壁」そのものじゃないということ。実は新潮新書が出るというので、買った本が「バカの壁」なんだけど、あまのじゃくだから読んでいなかったんだよね。
「哲学と理解-馬鹿の壁」の次の章節が、「剽窃と現場」というタイトルである。池田満寿夫の「模倣と創造」に模倣の同義語として出てくるのが、影響と剽窃だったものだから、つい続けて読みふける。剽窃は模倣であり、ここにも「模倣」と「創造」について書いてある。「模倣は動物界ではたいへん一般的な習性である」が、主体が違えば思わぬところで違いが出てくるという話は、個性の話につながっている。
[自然言語処理] 意味解析
自然言語処理には言語依存性が当然のことながらあるので、言語ごとに処理方法が変わってくるので大変。パーソナルなデスクトップにおける応用でも、実用的には、少なくとも日本語と英語の二通りを考える必要があるだろう。日本語の処理について、ChasenやMecabの形態素解析の結果を利用して単語出現数をカウントすることが容易にできることは、GETAのWAM生成用のスクリプト(2004/11/01: GETA: freqfileの生成)で見たとおりだ。これをベースにして、デスクトップやWebの検索システムを実装することは容易だろう。
しかし、文書に出現する単語の数をカウントするだけでは、統計的に処理しようがどうしようが言語理解に到達することは原理的に不可能であると考えてよいだろう。これを単純に追いかけても得るものは少ない。GETAを利用したものとしては、既にBluesilkがある。無論、中身の仕掛けがどうなっているかは知らない。それが、検索結果の理解に障害になるのは問題ではあるが。次のステップにとって、自然言語処理の最先端がどのような状況になっているのかを調べてみることが重要であることは間違いない。
GDA(Global Document Annotation)の仕様を見て、タグをどこまで自動的に付けられるかは興味のある問題である。品詞については、形態素解析の出力を利用することが可能である。Cabochaの係り受け解析を利用すれば、依存関係のタグの付与も可能になるだろう。その他、文書構造の段落や文につけるタグ、値を持つタグなども自動的に付与することは可能だろう。意味に基づく情報検索にあるように、文書をGDAでタグ付けして、情報検索に利用する研究が進められている。意味的情報検索をキーにしてググッてみると参考になる文献が見つかるだろう。少し自然言語の意味解析について勉強してみよう。
[Ontology] オントロジーのお勉強(2) The Protege Ontology Editor and Knowledge Acquisition System
Protegeというスタンフォード大学で開発されているオントロジーエディタ・知識獲得システムがある。オントロジーエディタは以前からいろいろ触っているのだが、Protegeはソフトウェアとして本格的な感じ。これを使うことに決めて、使い始めた。オントロジーの領域には、「デスクトップCGI」を置いて、関係する知識を整理していく。最終的にはデスクトップCGIシステムの構成自動化を目標とする。
クラスブラウザ画面部分: デスクトップCGIのオントロジーの検討
クラス名等、データに日本語が使える。Javaのアプリケーションの国際化は進んでいる。やはり、Javaも無視できないかな(^^;)Protegeはかなりいかしたアプリケーションだ。
[Perl] Parrot On Win32
http://www.jwcs.net/developers/perl/pow/。Windows上で動くParrotがついに出たというか、Perl 6 の週間サマリーで初めて言及があった。WindowsXPでperl t/harnessのテストをした結果。
Failed Test Stat Wstat Total Fail Failed List of Failed
-------------------------------------------------------------------------------
imcc/t/imcpasm/cfg.t 3 768 3 3 100.00% 1-3
imcc/t/imcpasm/opt0.t 6 1536 6 6 100.00% 1-6
imcc/t/imcpasm/opt1.t 47 12032 49 47 95.92% 1-47
imcc/t/imcpasm/pcc.t 1 256 11 1 9.09% 1
imcc/t/imcpasm/sub.t 2 512 2 2 100.00% 1-2
t/library/streams.t 2 512 21 2 9.52% 14 18
t/pmc/nci.t 6 1536 46 6 13.04% 33 35-37 42-43
t/pmc/perlnum.t 1 256 43 1 2.33% 36
t/pmc/sub.t 255 65280 76 28 36.84% 63-76
6 tests and 54 subtests skipped.
Failed 9/111 test scripts, 91.89% okay. 82/1859 subtests failed, 95.59% okay.
最初はmsvcrtd.dllが見つからないというエラーが出た。http://www.dll-files.com/dllindex/dll-files.shtml?msvcrtdからダウンロードして、systemフォルダにコピー(DLL FILEに2$寄付した)。PerlはActivePerl 5.8.4。
[Perl] Firefox用ブックマーク検索CGIスクリプト、RSSフィードリストCGIスクリプト
「お気に入り」検索CGIスクリプトとRSSフィードリストCGIスクリプト(「お気に入り」のRSSフォルダに格納したRSS関連のURLファイルのタイトルデータにRSSリーダーCGIスクリプトをリンクさせたリストを出力する)を、Firefoxのブックマークに対応するようにした。「実践実用Perl」サポートページにアップした。
[Perl] 実践実用Perlの「お気に入り」関連CGIをFirefoxブックマーク対応のCGIスクリプトに移植完了
システム起動用HTMLもFirefox用に移植し、ファイル名を変えたものをアップしたので、FirefoxとInternet Explorerを交互に切り替えて使えるようになった。今のところ、一長一短あるので、交互に使えないと不便だ。
[Perl] SPIDERING HACKS HACK#9 (jperlでHACKする #1)
村上さんの訳者補にあるPerl5.8を使う場合の注意事項は大変参考になる。特にエラーメッセージをshiftjisで出力する方法と山カッコ演算子による入力に関する注意事項はへーっなるほどと思った。もう一つ付け加えるとすれば、環境変数の問題である。shiftjis文字列の環境変数は単純には読めない。shiftjisファイルを読むのと同様にEncodeモジュールを使ってdecodeする必要がある。
スクリプト的には完全にJperlと互換性がなくなっているので、移行はそれほど簡単ではない。それでなくても常に文字コードを意識する必要のあるインターネットプログラミングは大変である。Jperlの楽なスクリプティングに慣れているとつい億劫になってしまう。5.0で使えない、どうしても使いたいモジュールが出てこなければ、このままJperlを使っていくのが楽そうだが・・・CGIなら、拡張子を変えて使い分けも可能だから、必要に応じて導入すればよい。そのうち(2年ぐらいはかかるだろうけど)、Perl 6が出てくれば、どっちにしてもスクリプトの互換性はなくなるわけだし、パフォーマンスも相当上がるはずだ。その時点では、移行する動機付けがかなり高まるだろう。
試しに、最初に出てくるスクリプトHACK#9をJperlに移植してみた。尤もJperlに不要な5行を削っただけだが、Jperlで正常に動作する。使っているモジュールがLWP::Simpleだけだし、対象のサイトがshiftjisとわかっているので、問題がないのは当然だ。スクリプトがshiftjisで書いてあるので試すのは簡単である。今日から、SPIDERING HACKSを使って、Perl5.8の必要性を一つ一つ検証していこう。それがJperlからPerl5.8へ移行するためのテストケースになるはずだ。
[Perl] SPIDERING HACKS HACK#10 (jperlでHACKする #2)
うむ。LWPモジュールのバージョンに制限があり、5.64以上が必要である。
jperl -MLWP -e "print $LWP::VERSION"
とすると、5.45。LWP::UserAgentにgetメソッドがないので動かないというエラーになる。ppmで調べても新しいものはない。仕方ないので、Perl5.8のライブラリを流用。ActivePerl 5.8.4(Build 810)のLWPバージョンは5.79である。
jperl -IC:/Perl5.8/site/lib mofa_anzen.pl
とすると、Error: Runtime exception のエラーになる。早くも土俵際に追い詰められた(@_@;)
5.45のLWPのドキュメントを読んでなんとか動くように改造。HACK #10 を土俵際でうっちゃり。さて、どこまで倒れずに進めるか。
しかし、この本は買いである。まず、丁寧に作ってある。日本語版にするために相当な労力が割いてある。それから、なぜ、LWPモジュールが存在するのか、ようやく理解できた(^^;)理解の浅さに冷や汗・・・でも勉強になる。
[Perl] SPIDERING HACKS HACK#12 hakusho.pl (jperlでHACKする #3)
LWPとURIモジュールを使うスクリプトだが、URI::query_formルーチンには日本語パッチが当たっている。URLエンコーディングには「実践実用Perl」で開発したJperl用ルーチンを使い、EncodeモジュールのかわりにUnicode::Japaneseモジュールを使って全面的に書き直した。第3面クリア。スクリプトに元の形はほとんど残っていないので載せておこう。
use LWP;
use Unicode::Japanese;
$s = Unicode::Japanese->new();
my $browser = LWP::UserAgent->new;
my $url = 'http://www.env.go.jp/search/search.cgi';
# キー/値のペア
%query_form = (
'query' => &juri_encode('白書'), # トップページは
'submit' => &juri_encode('検索'), # シフトJIS
'whence' => '0',
'lang' => 'ja',
);
while(($key,$val) = each %query_form){
push(@array, "$key=$val");
}
$url .= "?" . join("&", @array);
my $req = new HTTP::Request GET => $url;
my $res = $browser->request($req);
print $s->set($res->content, 'euc')->sjis; # 検索結果ページはEUC-JP
# Jperl 用 URL エンコーディング
sub juri_encode{
my($str) = @_;
$str =~ s/([^a-z0-9\-_.!*'\(\)~ ])/length($1) == 2 ? sprintf "%%%1s%1s%%%1s%1s", split("",unpack("H4", $1)) : sprintf "%%%02X", ord($1)/egi;
$str =~ tr/ /+/;
return $str;
}
[Semantic Web] セマンティック「メモる」システム
現行の「メモる」システムはHTMLでメモを保持する。スクリプトを書いてHTML等のテキストを処理することを前提に考えると、HTMLを書いたり見たりすることが通常の状態であっても構わないという立場である。memol言語は標準化されたものではないから、中間言語的取り扱いに止めている。Wikiでは、中間言語のまま、テキストでデータが保存され、表示するときにHTMLに変換される。このシステムの良いところは可読性が高いところだが、変換を伴うために大きなデータを表示する場合には重くなるのが欠点である。メモのようにテキストが小さな場合には変換負荷の問題はほとんどないだろう。中間言語を採用するのもありだが・・・
次世代「メモる」システムでは、データをXML(RDF、OWL、N3、Adenine)で保持して、XSLTで表示させるのがスマートかなと思ったりしている。タグはフォームで隠してしまう方法が考えられる。来年度の課題ということにしておこう。テキストはいかようにでも変換して取り扱えるので、両方式並立、段階的移行も可能な話ではある。ぼちぼちテストしていこう。
[知的生産の技術] 「超」整理手帳と「メモる」システムの連動
来年は「超」整理手帳を使ってみようかなと、手帳をバンドルした「超」時間管理法 2005 というアスコム・ムックを購入した。これはA4サイズの紙を使う。コンピュータのプリンタ出力がA4になるので相性が良いというのが大きな理由だ。「メモる」システムではスケジュール管理がメモを通じてできる。いずれ、年間スケジュールテキストから一括して「メモる」システム形式メモを生成するスクリプトを作ろう。追加するスケジュールはメモカレンダーを通じてスケジュールカテゴリのメモを書けばよい。メモ検索でスケジュールを検索して、スケジュールリストを得ることは簡単だ。メモも期間を限定して検索できるようなインターフェースを作る必要がある。「超」整理手帳対応の印刷出力も考えよう。はて・・・うむ、やるべきことが多過ぎる(^^;)
[知的生産の技術] 京大式カードとA7リングメモ
B6の京大式カードも使い始めた。リングメモとの連動を考える。リングメモがA6だとカードに貼り付けてコメントするには少し大きすぎるし、横にして書く必要がある。今日イオンで少し大き目?のA7のリングメモを見つけたこれが最適だ。50枚で46円、安い。
[知的生産の技術] デスクトップのカード
40件ぐらいの文書のつながりを調べた。まとめた数枚のカードをコンピュータに入力する段になって、これを自動化できないものかと思案する。カードに手書きで整理するのはよいが、コンピュータで簡単には取り扱えない。文書はコンピュータにも存在するが、イメージデータのものもあるから、すべてがテキストとして存在するわけではない。あきらめて、検索結果のテキストから、スクリプトでリストすべきデータだけ切り出し、エディタにタブ区切りで追加データの入力を始める。Excelに読み込んで取り敢えず表にまとめた。
コンピュータ上で文書の持つ必要な属性だけを表示させながら、関連付けをする作業ができればなあと思う。小さなメモをデスクトップに並べて作業するイメージのソフトウェアがないかなあ。それをまとめて一つの表として出力したりとか。Tcl/Tkで作るか・・・ArrangeNoteを活用する手もあったか・・・
文書の関係の表示にはWinGraphvizを検討してみよう。
Vectorでデスクトップにカードを並べて関連付けることができるフリーソフトウェアを見つけた。IdeaFragment2。なかなかおもしろい。KJ法を想定している。IFDという拡張子のデータファイルはテキストである。Graphvizと相互変換が可能かもしれない。ねこみみの世を忍ぶ仮のホームページへ。
ねこみみの世を忍ぶ仮のホームページからエディタQXのaraken のホームページへ移動。辞書引きの機能に引かれてダウンロード。自作のテキスト辞書を引けるようになる。Rakucopyに続いて有用なフリーソフトウェアの世界を久方ぶりに本格的に散策する。
[知的生産の技術] 発想定着型データベース
「実践実用Perl」サポートページに「インターネット時代の『知的生産の技術』」の一文を草した。「実践実用Perl」にはボリュームが大きくなりすぎて50ページ分ぐらい削除した部分がある。その一部であるが、重要なコンセプト部分である。例によって知識先行・概念先行でわかりにくかったので削除したのだが、小題を付けて、だいぶ筆を入れてみた。なんとかマニフェストになったかな。
その中で、読み返していて、そうだこれだと思って、造語を作った。「発想定着型データベース」也。思考を記録し、発展させることができるデータベースが必要だ。そのための枠組みが「メモる」システムであるようにしたいものだが・・・