[A.I.] 脳の情報システム
更新日記では、自己組織化マップやモンターギュ文法など、いろいろと齧ってみては噛み砕けずに棚上げということになる。大体において、論文を山ほど集めても(今やインターネットのおかげで可能になった)、実際にプログラムに書き下せるところまで到達し、しかも意味のあるものにするのは大変敷居が高い。運良くなにか書けそうだというところにきても、実用的な意味がありそうもないなあというところで止まってしまう。高い敷居が二つある。
アキバ系!電脳空間カウボーイズのケイス淀橋氏から洩れた「中野馨」先生と「アソシアトロン」の言葉から辿り、中野馨著、「脳の情報処理」、昭晃堂、1997年2月27日第1版第1刷、166ページ、3000円、ISBN4-7856-3101-5を先日購入。本だけじゃ何もできないよなと考えながらページを捲ると、「Cでつくる脳の情報システム」(近代科学社、1995年)が先にあることがわかって、アマゾンのマーケットプレイスで手に入れた。問題は、プログラムがPC9800用のTurbo C++で書かれていて、プログラムを収録したフロッピーが添付されていることだ。フロッピーは封が切られてないと書いてあるし、経時変化は大丈夫だろう。なんとかなるさと購入を決断したのだが、もう我が懐かしの愛機PC9801BX2は影も形もない。マーケットプレイスからの購入でも新品同様の鮮やかな色彩の本の封を切ってフロッピーを取り出す。Dell1(DIMENSION XPS H266)機のWindows98では、98のフロッピーが読めたような気が・・・Vista機からディスプレイをはずしてDell1機につなぎ替えて起動。おそるおそるフロッピーを入れて、エクスプローラのドライブをクリックするとあっさり表示された。次はネットワーク経由でコピーと思ったが、なかなかネットワークから見えない。デュアル起動のWindows 2000に切り替えて起動するとあっさりつながって、メイン機のDell3にコピー完了。やったー、教訓「古いマシンは保存するべし」(^^)v
この最後のサンプルが、「アソシアトロンの応用」となっていて、なんと「言語発生ロボット」とタイトルがついている。すごいな。やるなら、これが狙い目だろうけど・・・・・・夏休み工作の課題が決まったかな(^^;)
[Application] 「ソフトウェアの日用品化」というよりは「ソフトウェア作成の日常化」
Googleはソフトウェアをオープンにすることが自社のビジネスを発展させることにつながるという新しいビジネスモデルを生み出しつつある。Open Tech Press | JavaWorld DAY 2006:Googleのキーマンが語る「オープンソースとソフトウェアの未来」ネタ。
ソフトウェアは正に日用品化しつつある。だれでも文章を書くようにソフトウェアを簡単に作れるようになる。そのような時代が近づいている。その先鞭を切るのがスクリプト言語ではないかなと思ったりしている。まさにオープンソースそのものである。
僕がrss2html.cgiを書き始めた頃、glucoseというRSSリーダーの出始めのデザインを見ていいなあと思ったのだが、今日最新版をダウンロードして動かしてみた。更新日記のAtom配信をいくつかの代表的なリーダーでチェックするためである。他には、Windows Vista Beta 2のIE 7とFirefoxのpluginのSage(賢人)である。いずれも優れたものだが、機能を変更したり、追加したり、他のアプリケーションと連携させるというようなことができない。そのようなことを実現するためには、自分で作るしかない。そして、それを共有して発展させるためには、スクリプト言語が適している。
データは今やテキストとなり、そのテキストを変形したり、必要な部分を切り出したり、合成したり、加えたりして、新しい情報を生み出す。机の上で様々な資料を読んで引用部分を切り貼りしたり、自分の考えた結果を加えたりして、新しい文章を生み出すのとさして変わらない。ソフトウェアによるテキストの操作は日常生活で行っていることと変わらないほど単純化されてきている。
「RSSリーダーからパーソナル情報プラットフォームへ」というglucoseのコンセプトは、「Webとデスクトップの融合」を唱えるデスクトップCGIの考え方と似た部分がある。glucose2では、やはりローカルHTTPサーバーが動作している。それに加えて興味深いのは、Pythonが動作していることである。ヘルプのバージョン情報を参照すると、Pythonを含めて様様なものを組み合わせて構築されていることがわかる。
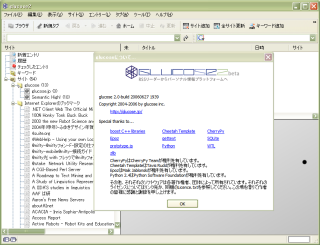
glucose2のバージョン情報
デスクトップCGIが今後どのように変貌していくのかはまだよくわからないのだが、データベースを加えてみようと考えている。データベースに実用的な意味が与えられるのかどうかが、まだ漠然としていて、本当に必要なものになるのかどうかがよく見えない。日記という時系列情報システムの見通しをよくする役割を担えるはずだと考えているが、どう使うのかが具体的になっていないのである。その前にMicroformatsを使って、日記を書くシステムを構築する。これによって日記がデータベース化されるはずである。日記は多種多様なMicroformatsの集合として表現されるようになる。
更新: 2006-07-03T00:13:27+09:00
[アート] 明日の神話
昨晩、鳴り物入りで公開された岡本太郎の「明日の神話」(1969)。前段の盛り上げも不要な感じがしたし、画面がライトで白く光ってしまって、今ひとつだった。久し振りに山下洋介のピアノは聴けたが・・・
実は、もう4月だったか、5月の連休中のことだったと思うが、広島市現代美術館で、修復前の原寸大の写真が展示された。大型のインクジェットプリンタで印刷して張り合わせたもので、補修中の足場も写っていた。大阪万博の「太陽の塔」(1970)と同時期に製作された壁画である。太陽の塔にどのような意味があるのか聞いたとき、岡本太郎は「意味なんかあるはずがない」と嘯いたそうで、絵などの芸術に過剰に意味を求めるのは無駄なことである。あるがままを見て感じるだけである。岡本太郎の作品は個人で所有するものはなく、作品は完成すれば公共のものという考えだったのだそうだ。「明日の神話」は広島に誘致する構想もあるそうだが、よい設置場所のアイデアを出してもらいたい。

「明日の神話」のパンフレットと4枚に折りたたまれた絵葉書
岡本太郎 誇らかなメッセージ"明日の神話"完成への道展 2006.4.15.sat→5.28.sun 広島市現代美術館
[本] 歴史へ
ミシェル・フーコーから、同時代のフランスの小説家たちへのつながりが浮かびあがる。モーリス・ナドー著、篠田浩一郎訳、「現代フランス小説史」みすず書房、1976年3月30日、新版第1刷(初版第1刷: 1966年1月30日)、原著: LE ROMAN FRANÇAIS DEPUIS LA GUERRE(Ëditions Gallimard, 1963, 1970)、323ページ、2600円は、第二次大戦前ぐらいからのフランス20世紀文学のガイドとして詳しい。第二次大戦の戦死者ポール・ニザンから、僕の好きな、当時はまだ若かったJ・M・G・ル・クレジオまでが取り上げられている。
北朝鮮のミサイル発射のニュースを聞きながら、戦争はなぜ起こるのかも考えさせられる。第二の波の発生時点までか、ニュートンやカントまで遡る以前に、20世紀についても思いを寄せる必要がある。
[本] モーリス・ブランショ
モーリス・ブランショについて、少しメモを書こう。
最後の作家、最後の人 ミシェル・フーコーはブランショを「最後の作家」と呼んだ。ブランショこそは、いかなる日常的空間にも還元できないあの「文学空間」を、西洋文学のすべての大作品(とりわけ十九、二十世紀の作品)について比類なくみごとに語ることを通じて、決定的に位置づけた人であるというのだ。その意味で、ブランショが西洋文学の歴史に対してはたしている役割は、西洋のメタフィジックの歴史においてヘーゲルがはたしたそれにあたると。
しかし、とフーコーは言う、ヘーゲルが記憶によって世界史のすべてを内在化、再現在化することを彼の哲学の原理としたのに対し、ブランショはその対蹠点にある。文学作品の言語、そして一般に言というものが、語る主体の<外>であるということ、パロールをして語らしめるもの、いわばその原理なき原理が忘却にほかならないということをブランショは執拗に、鮮烈に示しているのだ。
(モーリス・ブランショ著、豊崎光一訳、「最後の人/期待 忘却」、1971年、白水社: 289ページ、訳者あとがき)
訳者の豊崎光一氏はだいぶ前に亡くなられたのだなあ。ル・クレジオの訳者として親しみがあったのだが。スモールワールドを経由して内田樹先生の研究室に入る。フランス文学つながりで、いや、豊崎光一で検索して、話が別のところに来てしまった。来年がブランショ生誕100年なのか。RSS/Atomをマークして、次を考える。それで、ヘーゲルはどう位置づけるのか。
書かれたテキストに内在している小さな折り畳み空間は次々に開かれていく。連想が空間の扉を開くのだ。連想とは、すなわち惹起された記憶である。テキストが意味を持つのは、意識-記憶と相互作用する過程においてであり、書かれているそのものが意味を持つのではない。意味はテキストを読む人の意識-記憶の中に生成するのである。
「言(パロール)というものが、語る主体の外である」ということはそのような意味にも思えるが、何か確信を持って言えるレベルではないような気がする。なぜ、「パロールをして語らしめるもの、いわばその原理なき原理が忘却にほかならない」のか。もう少しいろいろと読んでみよう。ヘーゲル的な話は直感的によくわかる話であり、「人間世界の透視図」的世界観は類似したものだろう。ブランショは、オントロジー的発想で世界が把握できるはずだという楽観的な見方に対して、異議を唱えていると言えるかもしれない。
「現代フランス小説史」から少し引用しておこう。
言語は、それが名づけるものを否定する。「私が、この女、と言いうるためには、いずれかのやり方で、私がこの女からその骨と肉の現実を奪い去り、結局この女を現実に存在しないものとし、この女を抹殺しなければならない。たしかに語は私に存在をあたえる。しかし語は私に、現実的な存在性を奪われたものとしての存在をあたえるにすぎないのだ。だから、存在とは、この存在の非在そのもの、その存在の虚無、この存在が真の実在性を欠いたときにそこに残るものにすぎない。言いかえれば、存在がないという唯一の事実にほかならないのである。」だから言語とは否定であり、破壊である。これが言語の機能の第一段階である。しかし、つぎの段階として、言語は言語として実存し、言語の実存のみをつうじて、言語は肯定する。これが第二段階である。言語が到達する第三段階は、そのさいごのものだが、否定するこの肯定(実存)と、肯定するこの否定(存在)とを結合する。まさしくこれこそは、言語のもつ根本的な二義性であり、言語が文学のうちにもちこむ《ひとつに還元できない二重の意味》であり、つまり作家を蝕む苦悩の根元なのである。ブランショは文学の実践のなかに、死に到達することが不可能なかぎり、存在に到達することが不可能だという事実を自覚しようとする働きを見ている。「死は」と彼は書いている。「人間の可能性であり、人間の持つチャンスである。われわれは、すでに完結してしまった世界の未来が残されているのは、死をつうじてだ。死は、人間たちの最大の希望であり、人間たちに残された唯一の希望である。」(モーリス・ナドー著、篠田浩一郎訳、「現代フランス小説史」、みすず書房、1976年: 157ページ、疑問符を打たれた小説、モーリス・ブランショ)
読めば読むだけ、新たな疑問を生むが、テキストを理解することは、そんなに簡単なものではない。オントロジーの困難性はここにある。小説の場合は、特に虚構であることが前提なので、原理的に問題を抱えていると言えるが、ノンフィクションという前提があったとしても、事実をあるがままに言語に定着できるかというと、それは同様の原理で裏切られるだろう。
ここで、人間世界の透視図を得る試みは、無論、人間世界の知識の地図を得ようという野望であり、最終的には知識の共有化、その表現としてのRDF/XMLを極めようという実験に結び付けたいと考えている。タグ付け、あるいはオントロジー的検討は、語、あるいは連語、文節、あるいは文、あるいは段落、あるいは小節、章、書かれたもの全体に対して行われるだろう。しかし、なぜタグ付けを行う必要があるのか。元々、Machine-readableにするという現実的な目的がある。どのように使うのか、何を実現したいのかによって、タグの付けかたは変わってくるだろう。
今のところ、Webにおける知識表現における革新的なアイデアは、HTMLによるハイパーテキストだけである。電子的な引用によって原文をたちどころに表示させたり、註を呼び出すことが可能になる。RSS/Atomのような記事の構成要素とデータベース化を意識したid要素などのタグの付与は、テキストをデータベース化する作業に他ならない。おそらく統合的なテキストのデータベースは多層あるいはモザイクの構造を持つものになると予想される。
完全に定義されたデータを取り扱うなら従来のデータベース技術を使えばよいのではと思う。問題は単にRDF/XMLとデータベースの相互変換のような技術に帰着する。メリットは規格化されたデータの相互利用ということになる。ここで考えようとしているのはもっと別の次元の話で、例えば、テキストフォーマッタからの連想であり、テキストを章立てして読みやすいように整形したり、インデックスや目次を自動的に生成したりするだけでなく、テキストの構成要素さえもデータベース化し、さらには、読者独自の解釈・感想・註・栞、例えば、セイゴーマーキング的なものさえもデータベース化し、コンピュータ上で表現できないかということである。プログラミング言語やマークアップ言語を通じて、自然言語は変容する時代に入ったように思える。フーコー(ミシェル・フーコー - Wikipedia)がインターネットを知っていたらどのように歴史的に位置づけていたろうと思う。
書きながら、調べ、調べながら、書く。書いているうちに、一度書いたことが最初の意図とは変化して、最初と大幅に違う意味になって生まれ変わることもある。そのようにして、この日記の記事は書いているから、更新された記事の意味が変わっていることもあるはずである。書いた各バージョンも保存していくのも意味があるかもしれない。Atomではid要素が同じentry要素がある場合には、updated要素を変えておけばよいことになっている。
更新: 2006-07-17T10:42:11+09:00
[本] 歴史の書き方について
ミシェル・フーコー著、小林康夫/石田英敬/松浦寿輝編、石田英敬/松浦寿輝他訳、「フーコー・コレクション 3 言説・表象」、筑摩書房、ちくま学芸文庫フ 12 4、2006年7月10日第1版第1刷(DITS ET ECRITS, Editions Gallimard, 1994)、460ページ、1400円、ISBN4-480-08993-4。
「ピカソ・モディリアーニの時代」を見た帰りに、久し振りにそごう6Fの紀伊国屋書店に寄る。出たことは知っていたから、結局、購入。少し、最近の話題に関連する重要部分をピックアップしておこう。
---しかし、この五十年以上前から、記述という仕事が歴史学、民俗学、言語学のような領域では本質的なものとなってきた、ということは知られています。いずれにしても、ガリレオとニュートン以来、数学的言語は、自然の説明としてではなく、プロセスの記述として機能しているのです。歴史学のような形式化されていない学問に対して、記述の基本的な任務を行おうとする権利を認めないというのは理解できない。
---その基本的な任務というのは、方法的にはどのような方向をもつものだとお考えですか?
---第一に、もし、わたしが言ったことが正しければ、わたしが扱わなかった諸テクストも、必要な変形を加えつつ、同じ図式にしたがって正確に説明・分析できるはずだということ。
第二に、わたしが言及した諸テクストとわたしが取り扱った素材自体に対しても、ちがった時代設定を持ち、別のレヴェルに位置するような記述ができることになります。例えば、歴史学的知の考古学を行おうとするなら、当然、言語活動についての諸テクストを新たに用いなければならないでしょうし、それらを、解釈や源泉批判の一連のテクニックや、そして聖書と歴史的伝承にかかわるすべての知と関係づけなければならないでしょう。その時、言語活動についての諸テクストの記述は違ったものになるでしょう。しかし、それらの記述は、それが正確なものであれば、ある記述から別の記述へと移行することを可能にしてくれる変形を定義することができるようなものであるはずなのです。
ある意味で、記述はしたがって無限ですが、また別の意味では、研究対象となる諸言説のあいだに存在する諸関係を説明することのできる理論的モデルを確立しようとする限りにおいて、記述は閉じられてもいるわけです。(ミシェル・フーコー著、「フーコー・コレクション 3 言説・表象」、筑摩書房、2006年: 86ページ、「3 歴史の書き方について」、R・ベルールとの対談、1967年)
この部分は、Closed world machineがどのように成立するかを明確に述べているが、このように意識的にテクストを読むのは大変だろうと思う。自然言語テクストをプログラムのコードを辿るように読むという体験をしてみるのも興味深いかもしれない。対談は「言葉と物」について行われている。やはり「言葉と物」を読まねば話にならない。
ミシェル・フーコーは次のようにも言っている。もう、それから40年が経過しようとしているのだが・・・
・・・とくに論理学者の側、ラッセルやヴィトゲンシュタインの弟子たちの側では、言語活動はその具体的な働きを考慮に入れるのでなければ、形式的性質において分析することはできないということが気づかれ始めています。言語体系は諸々の構造の総体です。しかし、言説の方は働きの単位であり、言語活動を全体として分析しようとするなら、そのような本質的な要求に必ず直面せざるをえない。・・・(同99ページ)
さらに「世界の散文」という「言葉と物」の第2章のもとになったテクストから引用しておこう。ハイパーリンク、ハイパーテキストとは何かを考えさせる。
もろもろの記号をして語らせ、その意味の発見を可能にするような知識や技術の総体を、解釈学と呼ぼう。一方、どれが記号かを識別し、それらの記号を記号として構成しているものを規定して、記号どうしの関連や連鎖の法則の認識へと導いてくれるような知識や技術の総体を、記号学と呼ぶことにしよう。そうした場合、十六世紀とは、解釈学と記号学とを相似という形態のうちに重ね合わせていた時代なのであった。意味を探すこと、それは類似物を明るみに出すことだった。・・・・・(同64ページ、「世界の散文」、1966年)
タグ付けとは何かということになる。言わば、ハイパーリンクも類似物の引用なのである。これ以上はここで止めておこう。ここに本質が横たわっている。何の本質が・・・よく考えてみないと。
更新: 2006-07-18T21:19:26+09:00
[CodeZine] Web日記のAtom配信
プログラミングと開発者のためのCodeZine:デスクトップCGIでWebとデスクトップを融合する 第2回 Web日記のAtom配信ネタ。
第2回がようやく公開された。第1回のAtomリーダーのほうも合わせて、最新版にした。Atomリーダーから、Atom配信、そして、第3回はWeb日記そのものの作成配信について書こうと思う。次第に情報の源に遡る。
記事の執筆は、自分で使っているシステムと自分のスクリプティング技量を向上させるドライビングフォースにもなるというか、そうでないと意味がないというか。
わたしが何であるかを正確に認識する必要があるとは思いません。人生や仕事での主要な関心は、当初のわれわれとは異なる人間になることです。ある本を書き始めたとき結論で何を言いたいかが分かっているとしたら、その本を書きたい勇気がわく、なんて考えられますか。ものを書くことや恋愛関係にあてはまる事柄は人生についてもあてはまる。ゲームは、最終的にどうなるか分からぬ限りやってみる価値があるのです。(ミシェル・フーコーほか「自己のテクノロジー フーコー・セミナーの記録」、岩波現代文庫 学術116、2~3ページ、「Ⅰ 真理・権力・自己」)
[日記] 本は堆く積まれ
例によってというか、前にも増して、本が高く積まれた。同時に十冊以上もの本を読んでいる。僕の30年も前、過去の本。先月出版されたばかりの新しい本。言葉の世界の連なりに記憶を辿る旅に出る。言葉は記憶を刺激し、過去から現在に繋がる嗜好を浮かび上がらせ、懐かしいが、ほとんど考える術を知らなかった若き日を反芻する。仮想図書館に、本の目録、僕の嗜好の目録を作ろう。
[日記] アジサイの色
家内がアジサイの色が咲き初めと今では随分色が変わっていると持ってきた。前に撮影した時と比べてみよう。

2006-06-17

2006-07-05
[日記] Sageに負けない機能
なんて、競争しても仕方ないんだけど、alt-Sで起動してSageを使うのもそれなりに便利だ。フィードを集めるのにブックマークを使うのは同じだけど。「メモる」システムでsubmainフレームにフィードリストを出して、同じsubmainで解析した結果を見るのも見にくい。最近は別のタブに配信元の該当記事を表示させることができるから、mainフレームでフィード解析した結果を見るのが便利だとフィードリストの解析結果出力先を変更。なかなかいいじゃないと自画自賛。
IE 7風に出力スタイルを変更するかな(^^;)
「メモる」システムで
アキバ系!電脳空間カウボーイズのPodcastを聴いているところ
TSNETで評判の、なかなかインテリジェントでIT最新の洒落た話題を取り扱うPodcast。SageではPodcastへのリンクを表示できない。
拡大図: 「メモる」システムで「アキバ系!電脳空間カウボーイズ」のPodcastを聴いているところ
[日記] TS Networkの行方
風つかいさんのIcon講座を再発見して、Iconを久し振りに見に行ってきた。Unicode対応の可能性はJcon(Java-based Icon)での対応の可能性が示されているが、現時点ではまだ。
TSNETが創設されて以来、本サイトは「更新日記」に比重を移し、「日曜プログラマのひとりごと」と別称を持ち、次第に本来のプライベートサイトになりかけていたのだが。
TSNETは、気楽なマイペースのメーリングリストとWikiとして継続されている。気が向いたら話しかけることができる仲間がいる。TSNETWikiに、風つかいさんのIcon講座 - TSNETWikiのページも作ってみた。
最初はWikiページに貼り付けて加工しようとしかけたのだが、分量が多すぎて挫折。自分の日記で加工し始めた。我が日記に掲載すれば、Atomで取り出すことも簡単だ。Wikiは独自形式のテキストで保存する。これが少し標準化に逆行する。更新日記はdmlで書いているのだが、dml自体は残さない方針である。なぜなら、仕様をどんどん変えることが可能なのである。dmlで保存せず、HTMLとして保存するからである。
TS Networkは、コミュニティとして、新たなものを生み出すのか、コミュニティそのものが新しい形態になるのか、さて・・・、未来だけが知っている。
[日記] 雑音箱
夏になると、我が愛機もうるさい雑音を発する箱になる。エアコンを付けていても、ファンが唸って回り始める。やめてくれよと言いたくなる。まだまだ、PCは進歩しなくてはならない。一つはファンによる騒音であり、もう一つはやはりスピードである。多数のアプリケーションを遅滞なく、すなわち待ち時間なく実行できる必要がある。
「もう負荷分散は必要ない」---1台で同時50万接続のWebサーバーが登場:ITpro。ここまでのスペックは個人のデスクトップには不要と、通常考えるかもしれないが、世界をデスクトップ上に構築しようとすれば、必要な性能に限界はないかもしれない。僕が、PS3に期待しているのはそのような革新である。
[日記] サンデー・プログラマ
サンデー・プログラマよ再び:ITproネタ。「日曜プログラマのひとりごと」サイトの住人としては無視はできまい。
飛び跳ねるドットインパクトプリンタと今はなき2インチFDのシングルドライブを装備したベーシックマスターJr.で、カナの情報処理をしていた時代を思い出す。FDDを含めると軽自動車並みの価格のパーソナルコンピュータを横目で眺めながら、ワープロの時代が到来し、漢字が使えることが当たり前になる。ワープロでようやくMS-DOSを動く時代が来た頃、jgawkやjperlと出会って、今日に至る。その間にパーソナルコンピュータの発展のもっと長い歴史がある。MS-DOS→MS-DOS+DOS Extender→Windows 3.1→Windows 95→Windows 98→Windows 2000→Windows XPという具合だ。もっぱら、プログラミング言語はjperlであった。
今や、フリーでかつ日本語が使えるプログラミング言語はよりどりみどり。データはテキスト化し、題材はインターネットにもデスクトップにもごろごろ転がっている。これでプログラミングをせずして、何をするのか。
次世代のコンピューティングプラットフォームは何か。Windows Vistaか、Mac OS Xか、Linuxか、PS3か・・・PS3がどのような世界をもたらすのか、僕も大変楽しみにしているのだが・・・
[日記] 鮮やかな島々
早い帰宅時の車から見える瀬戸内の島々は何時になく鮮やかな色彩が立体感を際立たせている。商工センターに入る橋の上からは、久し振りに晴れた空の下で四国のほうまでよく見通せる。遠くに霞む島はない。見えるものすべてがクリアな実在感を持っている。めずらしい風景を見ている。不思議な感覚の中で、記憶の中に刻み込もうとしたはずだが、日記を書く今となっては感動したという記憶だけが鮮明である。
[日記] 過ぎ去る時間
毎週があっという間に飛び去る。もう今年の半分が過ぎ去り、今日はというか、昨日は雷で停電した。帰りに雲が垂直に発達しているのが見える。夏、積乱雲。Podcastを聴きながら帰宅し、続きを聴く。
IE 7の日本語版βをインストールしてみたが、リンクを右クリックでタブに開いたページを開こうとタブをクリックするとやはり落ちる。Firefox 2β1をインストールしてみたが、まだ拡張機能が動かないので困る。結局アンインストール。GDSも英語版のver.4をインストールしたあと、日本語版のver.3に戻したら、Becky!のメール表示ができなくなった。プラグインがver.4用になってしまったからだろう。日本語版ver.4が出るまで我慢するか(^^;)
電脳空間カウボーイズの話が頭にいろいろと残っている。Btronの話。VGAケータイの話。Lisp対Javaの話。毎週楽しみだ。時は過ぎ去り、過ぎ去り、過ぎ去り・・・
[日記] 投稿という文化
アキバ系!電脳空間カウボーイズのPodcastをTSNETで知ってから、いろいろなことを考えた。彼らのような若い人たちが日本にいることは素晴らしいことだと思う。彼らのこだわりはベーマガやCマガの投稿文化である。これをWebで蘇らせ、新しいものを生み出す原動力にしようというわけだ。これが電脳空間カウボーイズ探しのPodcastというわけ。
インターネットによってNIFTY SERVEのフォーラムが衰退の危機を迎え、Webへの移行を想定して、TS Network構想をFGALTSで呼びかけた時、僕は各人のホームページが相互作用する緩やかなネットワークを提唱した。これは、フォーラムでの盛り上がりや爆発現象(発言数の急激な増大)によって象徴されるフォーラムへのアクセスの多さやライブラリの利用度で評価するNIFTY SERVE文化とは相反するもののようにみんなは感じたらしい。
僕がインターネットを知って思ったのは、個人の表現の自由度が格段に向上することである。フォーラムでの発言は、今で言えば単なるメーリングリストのプレーン・テキストに過ぎない。コミュニケーションには適しているが、表現には適さない。表現の自由度が上がることは、個人的にはそれを作りだすために忙しくなるはずで、コミュニケーションがおろそかになるはずだというのが私の読みであり、各人のホームページを結ぶ(お互いに参照する)ことがある意味のコミュニケーションになると考えたのである。TS Networkingのページがその名残である。最近では、コミュニティのPlanetという考え方が出ているが、それを先取りしたようなものだった。今では、TSNETWikiにそれが実現されていると言えるだろう。メーリングリスト+Wiki(+RSS)というのがWebのコミュニティに適した形態と考えられる。
翔泳社のCodeZineも投稿ができるようになっている。投稿文化の再生を促すアイデアが実際に動いている。ただ、発表をするメディアが、ベーマガやCマガなどの雑誌しかないという状況ではないので、投稿をするという敷居を越えるかどうかは最早微妙かもしれない。電脳空間カウボーイズでも誰かが言っていたが、メディアが紙媒体の雑誌から、Webに移ったということなのだ。それを再度取り込もうという試みが始まっている。齊木さんも忙しそうだし、意外と成功するのかもしれない(^^)
[日記] 人間世界の透視図
フーコーの「知の考古学」とトフラー夫妻の「富の未来」をきっかけに、歴史を遡ることになった。人間世界の時空の透視図を描いてみること。これが、最終的な到達点である。
グラハム・ハンコックの「神々の世界」で、1~2万年前ぐらいの地殻変動が、人類文明の発祥へ与えた影響について考えたが、新人類の生物学・考古学的な歴史は20万年も遡る。旧人類を含めれば700万年の進化の歴史がある。それ以前には46億年の地球の歴史もあるわけだけど、それどころか、人類の認識は、宇宙の原初から終局までも描き出し、我々の住む宇宙は並行宇宙の一つに過ぎないかもしれないという人間の限界を越えた領域に突入している。
次はもっと身近な文明以後の人間の歴史、フーコーの言うカント以前以後の西欧の歴史。これはフーコーの他の著作を調べるところから始めることになるだろう。なぜ、著作のようなことに関心を持つのか、ようやく見えてきた。しかし、これは西欧の歴史と密接に関係があり、西欧人でないと見えにくい話のような気はしている。カント以前以後は歴史的には第二の波の発生前後と対応しているように考えられ、そのような視点からフーコーの著作を見てみたい。
僕が若い頃は、戦前、戦中、戦後という言葉がよく使われた。第二次世界大戦の以前以後で世代を分けて考えられた。「戦争を知らない子供たち」というフォークソングが歌われたり、戦無派という言葉が出現した。負のイメージを持つ戦前のことは忘れて、次第に戦後について考えるだけでいいじゃないという傾向になっていった。実際、歴史の授業はそれなりにおもしろかったが、平安時代や江戸時代がどうであろうと現代とは関係ないと思われた。
西欧については、フーコーの思索の道を辿ることでよいだろう。並行して、日本を見る。これはまだどのように見ればよいのかわからない。司馬遼太郎を読めばヒントが得られるのかもしれない。養老先生は都市化と非都市化の繰り返しというような視点も持たれている。古典を系統的に読む必要があるのだろうと思ったりしている。吉本隆明などいろいろ読んで手掛かりを探そう。
更新: 2006-07-15T17:12:20+09:00
[日記] ピカソとモディリアーニの時代
リール近代美術館所蔵の絵画を中心とした展覧会最終日。ひろしま美術館。
まあ、数は少なかったが、ピカソやモディリアーニだから悪かろうはずはない。聞いたことがない作家の作品もあり、めずらしいなというものもあった。もう名前はわすれちゃったが。ひろしま美術館所蔵品で水増しの感じ。ひろしま美術館の得意分野でもあるから、当然か。常設展は、展覧会に抜けた分だけ、見たことのない別の所蔵品がたくさん出ており、ルノアールの風景画2点とビュフェの赤い家が目を引いた。
 ピカソ・モディリアーニの時代
ピカソ・モディリアーニの時代
2006-07-16
ひろしま美術館
34.398553162287854132.45814561843872
地図の表示・非表示
Google Maps APIのtroubleshootingを見て、いろいろと環境を変えるなどしてみたけど、IE 6では地図を表示できない。Firefoxでは表示できる。
[日記] 花火、夏へ
鹿児島は水害でひどい状態。天気予報では雨は明日も相当降るらしい。被害が悪化しなければよいが。今朝は、広島はなぜか、蝉が鳴いていた。例年ならそろそろ梅雨が明けてもよい時期だ。今日は宇品花火大会。今年はできるだけ近づいて見ようとニチレイの倉庫の南まで歩いた。
[日記] 夏の計画
さて、風つかいさんのIcon講座一応完了。風つかいさんのIcon講座 - TSNETWikiに、更新日記インデックスのIconカテゴリのリンクを作成して、アクセスは確保した(^^;)
少し疲れ気味。だいぶ先のことになりそうだが、いずれ、講座をまとめてAtomで配信するかなと思っている。既に更新日記としては配信されているのだが。
「デスクトップCGIによるデスクトップとWebの融合」のCodeZineの記事第2回もようやく校正が終わって、来週には公開されるだろう。第3回の記事の完全な見通しはまだないので、少しずつ実験を続けていくしかない。Diary Description Language(Diary Markup Languageを改名)をMicroformatsやHTMLテンプレートと結び付けようとしているが、一貫性があり、かつ柔軟な方法論として、まだまとまりそうもない。Perl/Tkでコンソールを作るか、TeraPad上での編集を前提とするか。SJISかUTF-8か。jperlかPerl 5.8か。結局毎日やっていることを書くしかないわけだけど(^^;)自分で使う分には、現状でまったく問題ないのだが^^;;;第3回は起承転結の転だから、一捻りしたいところ。
ライティングデスクには例によって、新たに購入した本と本棚から引っ張り出した本が堆く積まれている。スタニスワフ・レムの「ソラリスの陽のもとに」と「砂漠の惑星」、J・G・バラードの「コカイン・ナイト」が新たに加わっている。この三冊は、フーコーの「フーコー・コレクション 3 言説・表象」と一緒に購入したものだ。金曜日には、吉本隆明の「初期ノート」を新大阪駅構内のキオスクで購入。アマゾンからは、中野馨著、「脳の情報処理」が届いた。SFをゆっくりと読み解くような余裕のある気持ちになれるとハッピーなのだが・・・チョムスキーの「言語と精神」の翻訳者の川本茂雄氏が、「ことばとこころ」(岩波新書青版988、1976年)の著者だと気が付いて、周囲が赤茶けて変色したページを捲って読んだ。本棚の背表紙を見て、フランシス・ポンジュのことがなぜか気に掛かる。・・・明日のことにしよう。
[日記] 変形生成文法
古きを尋ねて新しきを知る。フーコーが書いた「ポート・ロワイヤルの文法」は、Grammaire Générale et Raisonnéeの復刻出版(1969年)の序文である。元の本はデカルトの死後10年を経過した1660年に書かれている。300年後の復刻とはすごい。チョムスキーの「デカルト派言語学」(1966年)は、ポート・ロワイヤル文法について検討しているらしい。これを廻って、現在でも議論は尽きないようだ。少し、関連する重要なリンクを拾っておこう。The New York Review of Booksの記事がおそらく歴史的には重要なものだろう。レイコフ氏は、認知言語学の立場を取る言語学者である。結局、元の「デカルト派言語学」を読んでみないとなにも言えないが。
R.ジェイコブズ、P.ローゼンボーム著、松浪有、吉野利弘訳、「文体と意味 - 変形文法理論と文学」、大修館書店、1974年9月1日再版(1972年5月1日初版)、(Roderick A. Jacobs and Peter S. Rosenbaum; Transformation, Style, and Meaning; 1971)、182ページ、1500円のまえがきには、言語学の歴史と動向が要領よくまとめられている。といっても、1970年当時のことだろうし、現在の言語学がどのような状況にあるのかは、Wikipediaを参照するのがよいのかもしれない。
福井直樹著、「自然科学としての言語学 - 生成文法とは何か」、大修館書店、2001年2月15日第1版、275ページ、2300円、ISBN4-469-21265-2には、日本の理論言語学の現状・困難さを含めて書かれており、自然科学としての言語学を標榜する以上、チョムスキーの立場に立つものである。
更新: 2006-07-24T00:10:48+09:00
[日記] スリラーじみた話
最近は、文庫本も古いものを再版する動きが出ているようだ。スタニスワフ・レムの本も2006年3月の死去を契機に復刊されている。2005年<書物復権>共同復刊Ⅸ、筑摩書房: ちくま文庫復刊などの動き、復刊ドットコムという仕組みも出てきている。
メディアとしての本もインターネットを利用して読者ニーズを掴めば復権できるかもしれない。しかし、それなりに売れているんじゃないのとも思ったり。僕は相当買っている。家内から本を買う病気に罹っているんじゃないのって言われてしまった(^^;)いや、情報が情報を、本が本を呼ぶので仕方がないって答える。何か、スリラーじみた話だよね・・・(^^;)そのうち、インターネットのおかげで本が売れるようになったという話が出てくるかもしれない。インターネットの情報が本の需要を喚起するようになるという話。本のような実体的メディアももはやネットワークやコンピュータ上のデジタル情報と実質的なリンクを持っている。人間を媒介としてであるが・・・
更新: 2006-07-23T23:56:42+09:00
[日記] つまらない結論を書くな - オープンクエスチョン
暑い最中、日陰をつたいながらジャスコに向けて歩いた。電車通りから翠町のバス通りへの曲がり道の横断歩道で起きたらしい交通事故の検証の準備をしているのを眺めながら、電柱の影にかくれて信号の変わるのを待つ。夏がとうとうやってきた。
買い物の人々をよけながら、3階のフタバ図書に上がる。すぐ目についたのが、『考える人 創刊4周年記念特集 戦後日本の「考える人」100人100冊』。考える人は最初の年は購読したのだが、なんだか、感覚が合わなくて2年目から中止したのだが。100人100冊で1万冊かと思ったけど、100人それぞれ一冊ということ。今後の読書に参考になりそう。
他には、養老先生と内田樹先生の対談、「ユダヤ人、言葉の定義、日本人をめぐって」。つまらない結論を書くなというのは「物事をまるめるな」という養老先生のもの言いの内田先生流表現。デスクトップにどれだけ我慢して疑問を広げておけるか。これが大切ということ。下手に結論を出さない。
100人100冊についての坪内祐三氏と井上章一氏の対談『「考える」ための"素振り"』。いろいろ調べたり、書いたりして素振りをしないと考えも進まない。完璧なものはそう簡単には書けないものだ。
[日記] 梅雨明けのひとりごと
気象庁も梅雨明け宣言。昼間、アテンザのambientの温度表示は35℃を示している。
TSNETでの話題をきっかけにiCalendarを見直すことになった。RFC2445とRFC2446を印刷した。それぞれ、148ページと109ページ。Mozilla Calendarの実装に合わせて、iCalendar出力だけを考えるのがよいか、自ら、メモカレンダーに実装していくかだが・・・メモカレンダーに機能を持たせるなら、iCalendarにこだわる必要もないか・・・祝祭日のマーキングにiCalendarデータを使うことができるのはメリットになる・・・
メモカレンダーは日付別のメモファイルを認識して、日付にメモをリンクしているのだが、拡大カレンダーを作るのなら、個別メモの記事タイトルの表示が必要だろう。祝祭日は、カテゴリにイベントを作って、メモに書き込むだけでよい。このメモカレンダーを少し改造すれば、更新日記にもカレンダーを持たせることが簡単にできるが、日記のカレンダーにどれほどの意味があるのかは疑問だ。メモカレンダーは、日付のスケジュールカテゴリのメモを作成するフォームを生成するリンクを持っている。
[デジカメ] GPSとデジタルカメラの連動
撮影地点情報をデジタルカメラで撮影と同時に画像ファイルに埋め込めれば、これがベストだが、ありそうでなかなかない。おそらく充分な性能を出すことが難しいのだろう。GPSで測地することと高速でシャッターを切ることは相反することだからだ。リコー Caplio Pro G3 - レビュー - CNET Japan。これが今のところ現実的な線かな。しかし、残念ながら高価である。
ExifにはGPSデータも書き込める。デジカメのいいのを持っていれば、GPSのデータを時間情報をキーにして画像ファイルに書き込むという手もあるが、移動速度と時計の精度も問題になるらしい。
更新: 2006-07-15T23:12:44+09:00
[Firefox] Mozilla Calendar - iCalendarの応用
TSNETネタから展開。スケジュールだけでなく、時間情報をiCalendar形式に変換して、何に使えるかを調べたり、いろいろ考えた。
閑舎さんに紹介いただいた「iCal MEMO - 関連アプリ等」のページから、カレンダー公開サイトのページを見つけて、目を引いたのが、Calendar - 標準に準拠したカレンダー クライアント プロジェクトである。
早速、FirefoxのAddinをインストールした。エラーが出るけど、インストールはされている。起動してみると、かなり高機能なもののようだ。カレンダーをサーバーに公開する機能もある。
このカレンダーで、日記情報を配信することも可能だろう。想像力を刺激するアプリケーションである。
Mozilla Calendar
[Flash] Web KADOKAWAのFlash Viewer
web KADOKAWAネタ。「フランシス・ポンジュ」から、東京創元社|Webミステリーズ!(桜庭一樹 読書日記【第3回】(1/3) 二〇〇六年四月――ジョン・ランプリエールが辞書になる!)の記事が引っ掛かり、「桜庭一樹」って誰と検索して、少女七竈と七人の可愛そうな大人 :: Flash Viewerの立ち読みに至る。このFlash Viewerはよくできている。以上、おわりとしたいところだが・・・
さすが、小説家だけあって、日記もおもしろい。小説のほうは興味は別にして、Flash Viewerでちょっと読んだだけだけど、確かに天才だろうね。化粧の話が日記に出てくるのでほーっと思ったのだが、Profileを見ると女性なんだ。サイトデザインを含めて納得(^^;)ライトノベルだけでなくてヘビーノベルも書いてほしい。
今回は検索によって、引用という入れ子構造のリンクを辿って、異質なおもしろいものにぶちあたる例である。Web KADOKAWAのサイトも様々な工夫がしてある。注目キーワードをリンクに使うのははやりかな。しかし、サイトの全容をわかりやすく見せるのは情報量が多くなるにつれて難しくなる。ロングテールを大切にするなら、サイトマップをうまく作るのが重要な気がする。我がサイトでは更新日記インデックスが一種のサイトマップではあるのだが。更新日記検索スクリプトを日記における引用出力ができるように改造しようとしていたのを思い出した。
[Flash] OpenLaszlo
Yahoo!ポッドキャスト - アキバ系!電脳空間カウボーイズ - 第十三回 電網閃光技術者(フラッシュ・テック)ネタ。
ケイス淀橋氏より紹介のあったラズロを探した。
OpenLaszlo Explorer
インストールするとポート番号:8080でTomcatが起動して、Firefoxに表示される。見るとおり、流石、フラッシュ、ちょーかっこいい。XMLでフラッシュのプログラミングができるらしい。本質的には、フラッシュの機能の抽象化が進んでいて、他のシステムに変換が容易にできるようになるのかもしれない。無論、他のシステムとは何かという問題はあるが。Webブラウザの表現がどの方向に向かうのか・・・
[Google] Googleマップの地図とサテライト画像のずれ
マーカーの位置が指し示す位置がサテライト画像では地図の位置に対して東にだいぶずれている(サテライト画像が地図に対して西にずれている)。だいぶといっても、1秒未満のずれだと思うが。地図では川の岸ぎりぎりを指しているマーカーが衛星画像では川の中に落ちている。
[Google] toggleVisibility + Google Maps API 2
toggleVisibilityとGoogle Maps APIのver.2の組み合わせがうまく動かないので、困ったなと思っていたのだが、今日、スクリプトを再検討していると、GLatLngがGlatLngになっているのに気が付いた(^^;)これを直すと動き始めた。
以前のAPI ver.1を使っている記事もver.2に書き直したり、ver.2がうまく動かないので挫折していた写真と地図を連動させるMicroformat(viewpoint)の導入作業を開始した。ver.2は衛星画像表示が使えるので、素晴らしい。ただ、今回、大宰府付近の地図を見たが、九州国立博物館が記載されていない。少し地図は古いし、わかりにくい感じだ。
更新: 2006-07-17T21:55:20+09:00
[Google] Google Calendar
Text Worldにlivedoor天気予報の変形版を出力するCGIを置いて、Google Calendarから読めるようにしてみた。まったく意味がない。URL:項目を解析表示できないからだ。元のままなら、DESCRIPTIONに含まれるURLにリンクを張って表示する。
Google Calendar
結局、フルの機能を使おうと思えば自作するしかない。
[Icon] Icon入門講座6 Iconミニ講座
2003/9/26 風つかい(hshinoh[atmark]mb.neweb.ne.jp)さんの--- TS Network への書込から ---
本サイトの講座には、風つかいさんのIcon Lectureという記事があります。実は、閑舎さんから風つかいさんからのメールを転送してもらって講座(Seminar on TS Network)に追加するように依頼されていたのを、当時おそらくバタバタしていた時期だったので、見逃していたか、忘れてしまったかだけど、今日メールを整理していてたまたま発見。TSfreeへの書き込みをまとめられたもの。今日までほったらかしで申し訳ない。_(__)_テキスト分量が大きいので本日記で連載し、少しずつHTML化しつつ発表することにして、最後にまとめて、講座に追加いたします。以前、HTML化に使ったスクリプトの行方も定かでないし・・・、デザイン的にも少し考えるかと。
■ TSfree > Iconミニ講座(前説) 風つかい
残梅雨お見舞い申し上げます。残暑じゃなくて、梅雨が未だ残っているような天気ですね。火星大接近とかいうニュースで夜空を見上げても、雲ばかり。
さて、先日、TS Networkの TSabcで、クロスワードパズルの関係で、面白い題材を提供して頂いています。こんなケースです。
- 英文字のクロスワードパズルをまず解いて、その後指定の升目の文字を組み合わせて最終的な単語を見つける。
- しかし、一部判っていない升目がある。
- 辞書は、英語の単語がズラッと並んだ形式の辞書ファイルがある。
- サンプル 判らない文字を .で表すと、a.ahviy.r となる。尚、この場合の正解は、heavy rain という2つの単語の組合せだそうです。
というこことがありまして、Icon版で簡単な支援プログラムを作ってみたのですがお盆休みに、もう少し機能アップできないかと考えてみました。少し整理して、アップしてみます。
- 指定文字の順列組合せの生成(これは、比較的簡単。TSabcにアップ済み。)
- その順列を分けて、単語候補を生成 heavyrain -> heavy rainと分ける
- 辞書の検索(不明文字があるので、曖昧検索が必要)
あたりを考えてみたのですが、
- 曖昧検索は、一挙に処理時間が増えてしまいそうなので、パス。heavyではなく、h.avyだと、"."は a-zの可能性があるので、一挙に 26倍になってしまいます。
- 文字列を分割して、単語候補を生成する。これはできそう。これには、まず、5文字の文字列だと、5文字の単語、4+1文字、3+2文字、3+1+1文字、2+2+1文字、2+1+1+1文字、1+1+1+1+1文字等の組合せが考えられます。あまりに多い分割数とか、短い単語はある程度無視して良いかと思います。
- 英語辞書は、スペルチェック用のフリーの辞書を探す。辞書は、最初に一挙に読み込んで、setに登録し、それを使って検索する。
こんなところで、やってみましょう。Iconのプログラムおよびライブラリーは、次の所から 入手できます。→ http://www.cs.arizona.edu/icon/
この講座は、TS Networkの TSfree メーリングリストにポストしたものに加筆・修正を行ったものです。Iconは PDSですので、この講座も同じ扱いとします。(転載・編集自由)(This textbook is in the public domain.)
Iconミニ講座 目次 内容
第1回 辞書読込 ファイル読込、set(集合)生成・格納・参照
第2回 組合せ文字列の辞書参照 順列生成(nPm)、set参照
第3回 正整数の分割 生成数の部分和、再帰プログラム
第4回 フィルター generatorとフィルター
第5回 文字列分解・辞書参照 文字列の分解・繰り返し参照
第6回 辞書参照の別方式 table生成・格納・参照
第7回 曖昧参照 組合せ生成(nHm)
第8回 辞書分割 ファイル書込み
第9回 分配組合せ 文字列の組合せ分配
第10回 分割文字で辞書参照 繰り返し参照
おまけ プログラムの整理 link
あまり procedure構成 再帰・every・while
風つかい(hshinoh[atmark]mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: Battery's not included /森山威男&杉本喜代志
(2003/08/20 TSfree0.txt)
[Icon] Icon入門講座6 Iconミニ講座1(辞書読込)
風つかいさんのIcon講座。
- [Icon] Icon入門講座6 Iconミニ講座 [7/9/2006 (Sun.)]
■ TSfree > Iconミニ講座1(辞書読込) 風つかい
今回は、辞書の読み込みです。 辞書と言っても、単語がずらっと並んでいるテキストファイルですので、テキストファイルの読込プログラムと変わりはありません。 後々、時間が問題に気になりそうなので、現在時刻を書き出すようにしました。 &clockは、現在時刻を hh:mm:ss形式で保持している組込キーワードです。 最初、動作モニター用の表示は、エラー出力へ出していましたが、アップの都合上、標準出力へ出すように修正してあります。
-----^ DICREF.ICN ( date:03-08-19 time:23:32 ) -------------<cut here
####################
# 辞書読込・辞書参照の習作。
####################
# dicref.icn Rev.1.0 2003/08/19 windy 風つかい H.S.
####################
# Usage dicref 文字列
# english.dicは、スペルチェック用の英単語が順に並んだもの。
# このプログラムのテストでは、DD SOFT SoundMixSpellコンポーネント
# Ver 0.3.0 に 同梱の辞書ファイルを使用。
# This file is in the public domain.
procedure main()
# 辞書読込
dic := "english.dic" # 辞書ファイル名
dir := open(dic) | stop(dic," が見つかりません") # 辞書ファイルオープン
S_dic := set() # 辞書格納 set生成
# write(&errout,dic," を読込中です。") # 辞書読み込み
write(dic," を読込中です。") # 辞書読み込み
# write(&errout,"開始:",&clock)
write("開始:",&clock)
n := 0 # 辞書行数カウンタ
while word := read(dir) do { # 辞書を1行ずつ読み込んで、
insert(S_dic,word) # setに登録
n +:= 1
if n % 1000 = 0 then writes(&errout,"*") # 読み込み状況表示
}
close(dir) # 辞書ファイルクローズ
write(&errout)
# write(&errout,"終了:",&clock)
write("終了:",&clock)
# write(&errout,dic," の読込を終わりました。\n",*S_dic," 語ありました。")
write(dic," の読込を終わりました。\n",*S_dic," 語ありました。")
# 辞書参照テスト
L := ["heavy","rain","yveah","niar"] # テストデータ
# write(&errout,"参照テストを開始します。")
write("参照テストを開始します。")
# write(&errout,"開始:",&clock)
write("開始:",&clock)
every s := !L do { # テストデータを順次読み出し
writes(s)
if member(S_dic,s) then write(": OK") # 辞書にあるかチェック
else write(": NG")
}
# write(&errout,"終了:",&clock)
write("終了:",&clock)
# write(&errout,"参照テストを終わりました。")
write("参照テストを終わりました。")
end
-----$ DICREF.ICN ( lines:53 words:154 ) -------------------<cut here
dicref >aaa としますと、こんな結果になります。
-----^ AAA ( date:03-08-19 time:23:35 ) --------------------<cut here
english.dic を読込中です。
開始:23:35:43
終了:23:35:51
english.dic の読込を終わりました。
257650 語ありました。
参照テストを開始します。
開始:23:35:51
heavy: OK
rain: OK
yveah: NG
niar: NG
終了:23:35:51
参照テストを終わりました。
-----$ AAA ( lines:13 words:20 ) ---------------------------<cut here
私のPCでは、辞書読込・setへの格納に、8秒ほどかかっています。CPU Celeronで、クロック 733M、メモリーは多分32M、MS-DOS版の Iconを、Windows-MEのDOS窓で動作させています。
風つかい(hshinoh[atmark]mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: Battery's not included /森山威男&杉本喜代志
(2003/08/20 TSfree1.txt)
[Icon] Icon入門講座6 Iconミニ講座2(組合せ文字列の辞書参照)
風つかいさんのIcon講座。
- [Icon] Icon入門講座6 Iconミニ講座 [7/9/2006 (Sun.)]
- [Icon] Icon入門講座6 Iconミニ講座1(辞書読込)
■ TSfree > Iconミニ講座2(組合せ文字列の辞書参照) 風つかい
今回は、
- コマンドラインから入力した文字列の順列組合わせを作成
- その組合せ文字が辞書にあるか参照し、あれば出力する
処理を行います。前回の辞書読込の辞書参照の部分に、コマンドライン入力の文字列の順列組み合わせを適用する構成となっています。
-----^ DICREFP.ICN ( date:03-08-20 time:18:18 ) ------------<cut here
####################
# 辞書読込・文字列順列の辞書参照
####################
# dicrefp.icn Rev.1.0 2003/08/20 windy 風つかい H.S.
####################
# Usage dicrefp 文字列
# english.dicは、スペルチェック用の英単語が順に並んだもの。
# このプログラムのテストでは、DD SOFT SoundMixSpellコンポーネント
# Ver 0.3.0 に 同梱の辞書ファイルを使用。
# This file is in the public domain.
procedure main(args)
# コマンドライン引数チェック。無ければ Usage表示
if *args < 1 then stop("dicrefp 英単語")
# 辞書読込
dic := "english.dic" # 辞書ファイル名
dir := open(dic) | stop(dic," が見つかりません") # 辞書ファイルオープン
S_dic := set() # 辞書格納 set生成
# write(&errout,dic," を読込中です。") # 辞書読み込み
write(dic," を読込中です。") # 辞書読み込み
# write(&errout,"開始:",&clock)
write("開始:",&clock)
n_line := 0 # 辞書行数カウンタ
while word := read(dir) do { # 辞書を1行ずつ読み込んで、
insert(S_dic,word) # setに登録
n_line +:= 1
if n_line % 1000 = 0 then writes(&errout,"*") # 読み込み状況表示
}
close(dir) # 辞書ファイルクローズ
write(&errout)
# write(&errout,"終了:",&clock)
write("終了:",&clock)
# write(&errout,dic," の読込を終わりました。\n",*S_dic," 語ありました。")
write(dic," の読込を終わりました。\n",*S_dic," 語ありました。")
# コマンドラインの引数の順列を生成し、辞書を参照
c_word := args[1]
# write(&errout,c_word," の組合せが辞書にあるかチェック中です。")
write(c_word," の組合せが辞書にあるかチェック中です。")
# write(&errout,"開始:",&clock)
write("開始:",&clock)
n_comb := 0 # 組合せ数カウンタ
n_find := 0 # 辞書にある件数カウンタ
every word := exsperm(c_word) do { # 順列 generatorから文字を取り出し
n_comb +:= 1 # カウンタ+1
if n_comb % 1000 = 0 then writes(&errout,"*") # チェック状況表示
if member(S_dic,word) then { # 組合せ文字列が辞書にあれば、
n_find +:= 1 # カウンタ+1
writes(&errout,"!") # 発見表示
write(word) # 組合せ文字列出力
}
}
write(&errout)
# write(&errout,"終了:",&clock)
write("終了:",&clock)
# write(&errout,n_comb," 通りの組合せのうち、",n_find," 通りが辞書にありました。")
write(n_comb," 通りの組合せのうち、",n_find," 通りが辞書にありました。")
end
# 以下は、Icon入門講座から引用
####################
# 英文字の組み合わせ(同一文字指定対応)
####################
# 名称変更 expermute -> exsperm
# arg [1]: s string
# value: string
# Usage: every ss := exsperm(s) do ...
# Icon入門講座2(18)
procedure exsperm(s) # string permutations
if *s = 0 then return "" #
ss := csort(s) # 文字列をソートする。(strings.icn)
suspend ss[i := new_pos(ss)] || exsperm(ss[1:i] || ss[i+1:0])
# ↑同一文字はスキップする
end
####################
# ソートされた文字列 sの左はじから、順に文字位置を出力する generator。
####################
# 手前の文字と同一ならスキップする。
# arg [1]: s string
# value: integer
# Usage: every i := new_pos(s) do ...
procedure new_pos(s)
ss := "" # 手前の文字を記憶しておく変数
every i := 1 to *s do {
if ss ~== s[i] then { # 手前の文字と違っていたら
ss := s[i] # 手前文字を更新
suspend i # i を返す。
}
}
end
####################
# BIPL(Icon基本ライブラリー)の strings.icnに含まれる 文字のソート procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ローカル変数宣言(無くても良い)
s1 := "" # 初期値クリア
every c := !cset(s) do # 引数を cset(文字集合)へ変換し順に取り出す。
every find(c, s) do # 取り出した文字で、引数文字列を検索し、
s1 ||:= c # 見つかる度に、文字を s1に足し込む。
return s1
end
# csetから !で要素を取り出す時には、アルファベット順に取り出せる。
-----$ DICREFP.ICN ( lines:110 words:369 ) -----------------<cut here
dicrefp sunrise >bbb としますと、こんな結果になります。
-----^ BBB ( date:03-08-20 time:19:18 ) --------------------<cut here
english.dic を読込中です。
開始:19:18:22
終了:19:18:30
english.dic の読込を終わりました。
257650 語ありました。
sunrise の組合せが辞書にあるかチェック中です。
開始:19:18:30
insures
sunrise
終了:19:18:30
2520 通りの組合せのうち、2 通りが辞書にありました。
-----$ BBB ( lines:11 words:17 ) ---------------------------<cut here
いくつかの単語で試してみましたが、短い単語ですと並べ替えで結構他の単語になりますが、長い単語だと並べ替えてもうまくは他の単語にはならないみたいです。
風つかい(hshinoh@mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: ふたりのビッグショー ~Talk百歌~ vol.7 /篠原美也子&奥井亜紀
(2003/08/20 TSfree2.txt)
[Icon] Icon入門講座6 Iconミニ講座3(正整数の分割)
風つかいさんのIcon講座。
- [Icon] Icon入門講座6 Iconミニ講座 [7/9/2006 (Sun.)]
- [Icon] Icon入門講座6 Iconミニ講座1(辞書読込)
- [Icon] Icon入門講座6 Iconミニ講座2(組合せ文字列の辞書参照)
■ TSfree > Iconミニ講座3(正整数の分割) 風つかい
今回は、正整数の部分和への分解です。これは、5文字の文字列があるとして、例えば、3文字と2文字の2つの単語として、辞書を参照するためのものです。5の分解でも、5(分解しない)、4+1、3+2、3+1+1、...といって、最後は1+1+1+1+1と、かなりのパターンが発生します。こういう面倒な繰り返しが必要な処理は、再帰処理を行うとプログラムが楽になることが多いみたいですね。
処理は、5の例ですと、5から順次 5、4、3、2、1と引き算していくやり方にしています。
最初は、5から5を引くケースで、余りは0です。結果は[5]を返します。
次は、5から4を引くケースで、余りは1です。余りがある場合は、中間結果として[4]を保持して、自分自身を更に呼んで(再帰)、余りの1を与えて、結果をもらいます。その結果として[1]が返って来ます。中間結果の[4]に[1]を追加して[4,1]を結果として返します。
次は、5から3を引くケースで、
1回目の動作 中間結果1 [3] 余り 2 ・・・余り処理のため再帰
2回目の動作 中間結果1 [2] 余り 0
2 [1] 余り 1 ・・・余り処理のため再帰
3回目の動作 結果1 [1]
という動作を経ますので、結果は[3,2]と、[3,1,1]の2つが返ります。
こんな風な動作となります。
-----^ N_DIV.ICN ( date:03-08-20 time:19:43 ) --------------<cut here
####################
# 正数分割
####################
# n_div.icn Rev.1.0 2003/08/20 windy 風つかい H.S.
####################
# Usage n_div 正数
# 与えられた数字を部分和に分解する。
# 例:5->[5],[4,1],[3,2],[3,1,1],[2,2,1],[2,1,1,1],[1,1,1,1,1]
# This file is in the public domain.
procedure main(args)
Usage := "n_div 正数"
if *args < 1 then stop(Usage) # コマンドライン引数が無ければ Usage表示
if args[1] < 1 then stop(Usage) # 正数でなければ Usage表示
# ↓正数分割 generatorから順次結果を取り出し
every L := n_div(args[1]) do show_sl(L)
# ↑listの内容を表示する
end
####################
# 正数分割 generator
####################
# arg [1]: 分割される数(正数)(再帰の場合は、余り)
# value : 分解結果の数 listに格納
# Usage : every L := n_div(r) do ...
procedure n_div(r)
if r < 1 then fail # 念のため
if r = 1 then return [1] # 再帰終了
# r >= 2 の場合
every i := r to 1 by -1 do { # r から順に -1しながら
rr := r -i # 元の数から引き算していく
if rr = 0 then suspend [i] # 余りが 0なら結果を返す。
else suspend [i] ||| n_div(rr)
# ↑余りがでたら、再帰してその結果を listの末尾
# に追加。 ||| は listの要素の追加演算子
} # suspend は、複数の結果を返す return
end
# 以下は、Icon入門講座より
####################
# listの 内容表示
####################
# arg : list
# value : null
# Usage : show_sl(L)
# 最終的に stringか numberが要素であること
# Icon入門講座(13),Icon入門講座3(15)
procedure show_sl(list)
# listの内容表示(test/表示用)
every writes(" ",!list)
write()
return
end
-----$ N_DIV.ICN ( lines:57 words:192 ) --------------------<cut here
n_div 5 >ccc としますと、こんな結果になります。
-----^ CCC ( date:03-08-20 time:19:44 ) --------------------<cut here
5
4 1
3 2
3 1 1
2 3
2 2 1
2 1 2
2 1 1 1
1 4
1 3 1
1 2 2
1 2 1 1
1 1 3
1 1 2 1
1 1 1 2
1 1 1 1 1
-----$ CCC ( lines:16 words:48 ) ---------------------------<cut here
以上の結果を良く見ますと、5=4+1と1+4や 3+2と2+3の両方が現れています。辞書検索は、どちらか一方を行えば、残りは入れ替えるだけで人が判断できると思います。ということで、片方だけにするために、結果は、降順しか許さないという条件を付けましょう。ということで、再帰の際に制限を付けました。
-----^ N_DIVD.ICN ( date:03-08-20 time:19:42 ) -------------<cut here
####################
# 正数分割
####################
# n_divd.icn Rev.1.0 2003/08/20 windy 風つかい H.S.
####################
# Usage n_divd 正数
# 与えられた数字を部分和に分解する。結果は降順の分解のみ。
# 例:5->[5],[4,1],[3,2],[3,1,1],[2,2,1],[2,1,1,1],[1,1,1,1,1]
# This file is in the public domain.
procedure main(args)
Usage := "n_divd 正数"
if *args < 1 then stop(Usage) # コマンドライン引数が無ければ Usage表示
if args[1] < 1 then stop(Usage) # 正数でなければ Usage表示
# ↓正数分割 generatorから順次結果を取り出し
every L := n_divd(args[1]) do show_sl(L)
# ↑listの内容を表示する
end
####################
# 正数分割 generator
####################
# 5=3+2 等に分割する。分割は降順のみ許す。(例 5=2+3は除外)
# arg [1]: 分割される元の数(再帰の場合は、前の処理の余り)
# [2]: 最大数 (5=2+2+1 の場合に、最初の 2の時 3が余るが、再帰して 3の
# 分割を始める時、3からではなく 2から始めるための細工。降順手当。)
# value : 分解結果の数。listに格納
# Usage : every L := n_divd(r) do ...
procedure n_divd(r,max)
/max := r # 指定無きは、分割される元の数そのもの
if r < 1 then fail # 念のため
if r = 1 then return [1] # 再帰終了
# r >= 2 の場合
if r > max then rs := max # 分割(取り去る)数の最大数の設定。
else rs := r # 分割される数か 最大数指定の 小さい方
every i := rs to 1 by -1 do { # 上記指定数~1迄、順に-1しながら
rr := r -i # 新たな余り
if rr = 0 then suspend [i] # 余りが無ければ
# 余りがあれば、再帰処理
else if rr > i then suspend [i] ||| n_divd(rr,i) # 余りが大き過ぎる時
else suspend [i] ||| n_divd(rr)
}
end
# 以下は、Icon入門講座より
####################
# listの 内容表示
####################
# arg : list
# value : null
# Usage : show_sl(L)
# 最終的に stringか numberが要素であること
# Icon入門講座(13),Icon入門講座3(15)
procedure show_sl(list)
# listの内容表示(test/表示用)
every writes(" ",!list)
write()
return
end
-----$ N_DIVD.ICN ( lines:63 words:231 ) -------------------<cut here
n_divd 5 >ddd とすると結果は、こうなります。だいぶパターンが減りました。それでも、未だ随分ありますので、分割数や最小数に制限をつけたいと思います。それは、次回に。
-----^ DDD ( date:03-08-20 time:19:45 ) --------------------<cut here
5
4 1
3 2
3 1 1
2 2 1
2 1 1 1
1 1 1 1 1
-----$ DDD ( lines:7 words:20 ) ----------------------------<cut here
風つかい(hshinoh@mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: Battery's not included / 森山威男&杉本喜代志
(2003/08/20 TSfree3.txt)
[Icon] Icon入門講座6 Iconミニ講座4(フィルター)
風つかいさんのIcon講座。
- [Icon] Icon入門講座6 Iconミニ講座 [7/9/2006 (Sun.)]
- [Icon] Icon入門講座6 Iconミニ講座1(辞書読込)
- [Icon] Icon入門講座6 Iconミニ講座2(組合せ文字列の辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座3(正整数の分割)
■ TSfree > Iconミニ講座4(フィルター) 風つかい
今回は、正整数の部分和への分解で、結構な数のパターンが生成されますので、これに制限を掛けます。 分割数の制限と最小数の制限を付けられるようにします。
前回の n_divd.icn に制限を付ける処理を追加しても良いのですが、降順のみの制限を付けるだけで結構面倒したので、更に修正する気は起きません。
そこで、n_divd.icnはそのままにして、n_divdを呼ぶ方で制限を付けようと思います。
あるプログラムの処理結果を、別のプログラムが加工して、更に別のプログラムに渡すことを、フィルターと言いますので、この procedureも、フィルターと言って良いと思います。 こんな格好の構成です。
+----------------+ +--------------+ +--------------+
| n_divd | | n_divdf | | main |
| 正整数分割生成 | ---> | 分割数制限 | ---> | 結果を使用 |
| | | 最小数制限 | | |
| | | フィルター | | |
| generator | | generator | | |
+----------------+ +--------------+ +--------------+
-----^ N_DIVDF.ICN ( date:03-08-20 time:23:48 ) ------------<cut here
####################
# 正整数分割 分割数・最小数制限付き
####################
# n_divdf.icn Rev.1.0 2003/08/20 windy 風つかい H.S.
####################
# Usage n_divdf 正整数 最大分割数 最小数
# 与えられた数字を部分和に分解する。結果は降順の分解のみ。
# 例:5->[5],[4,1],[3,2],[3,1,1],[2,2,1],[2,1,1,1],[1,1,1,1,1]
# この中で、最大分割数、最小数の制限に合うものを出力する。
# This file is in the public domain.
procedure main(args)
Usage := "n_divd 正整数 最大分割数 最小数"
if *args < 1 then stop(Usage) # コマンドライン引数が無ければ Usage表示
if args[1] < 1 then stop(Usage) # 正数でなければ Usage表示
n := args[1] # ↓defaultはなるべく生成パターンが少なくなるよう
ndiv := \args[2] | 1 # defaultの最大分割数は、1(分割せず)
nmin := \args[3] | *n # defaultの最小数は、分割される数そのもの
write(n," を、最大分割数 ",ndiv,"、最小数 ",nmin," にて分割")
# ↓正整数分割 generatorから順次結果を取り出し
every L := n_divdf(n,ndiv,nmin) do show_sl(L)
# ↑listの内容を表示する
end
####################
# 正整数分割 generator
####################
# 5=3+2 等に数字分割する。この procedureは n_divdを呼びフィルターを掛けている。
# 分割パターンが多すぎる時に、制限をかけるために使用。
# arg [1]: 分割する元の数
# [2]: 最大分割数
# [3]: 最小数
# value : list
procedure n_divdf(r,ndiv,nmin)
every L := n_divd(r) do { # r の分割結果を取り出し
if *L <= ndiv then { # 分割数チェック(listのサイズチェック)
if L[*L] >= nmin then suspend L # 最小数チェック(降順に入っているので
} # 末尾の要素をチェック)
}
end
####################
# 正整数分割 generator
####################
# 5=3+2 等に分割する。分割は降順のみ許す。(例 5=2+3は除外)
# arg [1]: 分割される元の数(再帰の場合は、前の処理の余り)
# [2]: 最大数 (5=2+2+1 の場合に、最初の 2の時 3が余るが、再帰して 3の
# 分割を始める時、3からではなく 2から始めるための細工。降順手当。)
# value : 分解結果の数。listに格納
# Usage : every L := n_divd(r) do ...
procedure n_divd(r,max)
/max := r # 指定無きは、分割される元の数そのもの
if r < 1 then fail # 念のため
if r = 1 then return [1] # 再帰終了
# r >= 2 の場合
if r > max then rs := max # 分割(取り去る)数の最大数の設定。
else rs := r # 分割される数か 最大数指定の 小さい方
every i := rs to 1 by -1 do { # 上記指定数~1迄、順に-1しながら
rr := r -i # 新たな余り
if rr = 0 then suspend [i] # 余りが無ければ
# 余りがあれば、再帰処理
else if rr > i then suspend [i] ||| n_divd(rr,i) # 余りが大き過ぎる時
else suspend [i] ||| n_divd(rr)
}
end
# 以下は、Icon入門講座より
####################
# listの 内容表示
####################
# arg : list
# value : null
# Usage : show_sl(L)
# 最終的に stringか numberが要素であること
# Icon入門講座(13),Icon入門講座3(15)
procedure show_sl(list)
# listの内容表示(test/表示用)
every writes(" ",!list)
write()
return
end
-----$ N_DIVDF.ICN ( lines:86 words:320 ) ------------------<cut here
n_divdf 9 3 3 >eee とすると、結果はこうなります。 相当、制限が付けられますね。
-----^ EEE ( date:03-08-21 time:00:00 ) --------------------<cut here
9 を、最大分割数 3、最小数 3 にて分割
9
6 3
5 4
3 3 3
-----$ EEE ( lines:5 words:13 ) ----------------------------<cut here
さて、次回は、まとめです。
風つかい(hshinoh@mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: Battery's not included / 森山威男&杉本喜代志
(2003/08/21 TSfree4.txt)
[Icon] Icon入門講座6 Iconミニ講座5(文字列分解・辞書参照)
風つかいさんのIcon講座。
- [Icon] Icon入門講座6 Iconミニ講座 [7/9/2006 (Sun.)]
- [Icon] Icon入門講座6 Iconミニ講座1(辞書読込)
- [Icon] Icon入門講座6 Iconミニ講座2(組合せ文字列の辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座3(正整数の分割)
- [Icon] Icon入門講座6 Iconミニ講座4(フィルター)
■ TSfree > Iconミニ講座座5(文字列分解・辞書参照) 風つかい
今日は、当地では、午前中は日が差していましたが、午後に雲が広がって曇空に。暑さ寒さに弱い私には、涼しくて好都合なのですが。
さて今回は、今までのまとめで、文字列を分解したもので辞書を参照する処理をやります。 プログラムは、辞書参照の所で、文字列分解パターン(切り出す文字列の長さ)を取り出してきて、それに従い順に部分文字列で辞書を参照します。
move()という関数出てきますが、これは文字列に対するポインターを動かすものです。
- "abcde" ? write(move(2)) とすると、"abcde"を走査対象文字列として、最初はポインターは先頭の "a"の手前にあります。
- move(2)で、ポインターは2文字分進んで、"b"と"c"の中間に来ます。
- move(2)の値は、その進んだ2文字分の間の文字列 すなわち "ab"となります。
- write(move(2))で、"ab"の書き出しができます。
- もう一度、write(move(2))とすると、"cd"が書き出せます。
このように、文字列から順に指定長の部分文字列を取り出すことができます。
-----^ DICREFPD.ICN ( date:03-08-21 time:19:10 ) -----------<cut here
####################
# 辞書読込・文字列順列生成/分割・辞書参照
####################
# dicrefpd.icn Rev.1.0 2003/08/21 windy 風つかい H.S.
####################
# Usage dicrefpd 英文字列 最大分割数 最小文字長
# english.dicは、スペルチェック用の英単語が順に並んだもの。
# このプログラムのテストでは、DD SOFT SoundMixSpellコンポーネント
# Ver 0.3.0 に 同梱の辞書ファイルを使用。
# 5文字の文字列を、5=2+2+1に分割した時に 2のところで、ダブリが生じる。
# 例えば、"ab"、"cd"、"e"が辞書にあれば ab cd e と cd ab eが出力される。
# This file is in the public domain.
procedure main(args)
# コマンドライン引数チェック。無ければ Usage表示
if *args < 1 then stop("dicrefpd 文字列 最大分割数 最小文字長")
# 辞書読込
dic := "english.dic" # 辞書ファイル名
dir := open(dic) | stop(dic," が見つかりません") # 辞書ファイルオープン
S_dic := set() # 辞書格納 set生成
# write(&errout,dic," を読込中です。") # 辞書読み込み
write(dic," を読込中です。") # 辞書読み込み
# write(&errout,"開始:",&clock)
write("開始:",&clock)
n_line := 0 # 辞書行数カウンタ
while word := read(dir) do { # 辞書を1行ずつ読み込んで、
insert(S_dic,word) # setに登録
n_line +:= 1
if n_line % 1000 = 0 then writes(&errout,"*") # 読み込み状況表示
}
close(dir) # 辞書ファイルクローズ
write(&errout)
# write(&errout,"終了:",&clock)
write("終了:",&clock)
# write(&errout,dic," の読込を終わりました。\n",*S_dic," 語ありました。")
write(dic," の読込を終わりました。\n",*S_dic," 語ありました。")
# コマンドラインの引数の順列を生成し、辞書を参照
c_word := args[1]
ndiv := \args[2] | 1 # 分割数指定無しは、1(分割せず)
nmin := \args[3] | *c_word # 最小文字長指定無しは、引数文字列長
n_comb := 0 # 組合せ数カウンタ
n_find := 0 # 辞書にある件数カウンタ
L_pat := [] # 文字列分割パターン格納 list
every put(L_pat,n_divdf(*c_word,ndiv,nmin)) # 分割パターン格納
# write(&errout,"\n",c_word," を、最大分割数 ",ndiv,"、最小文字長 ",nmin,
# " にて分割して、その全てが辞書にあるかチェック中。")
write("\n",c_word," を、最大分割数 ",ndiv,"、最小文字長 ",nmin,
" にて分割して、その全てが辞書にあるかチェック中。")
# write(&errout,"開始:",&clock)
write("開始:",&clock)
# ↓コマンドライン文字列の組合せを順次取り出し
every s := exsperm(c_word) do {
every L := !L_pat do { # 文字列を細分するデータを取り出して
ERR := &null # 辞書参照エラーフラッグリセット
ss := "" # 細分後の文字列格納エリア
s ? { # sを走査対象として、
every (length := !L ) & /ERR do { # 細分文字数を取り出して、
# ↑既に辞書参照エラーが発生していなければ、
n_comb +:= 1 # チェック回数カウンタ+1
if n_comb % 1000 = 0 then writes(&errout,"*") # チェック状況表示
sss := move(length) # 細分文字列の取り出し
# 細分文字が辞書に存在するかチェック
if member(S_dic,sss) then ss ||:= (sss || " ") # データ足し込み
else ERR := "ERR" # 参照エラーフラッグセット
}
# 細分文字列が全て辞書にあれば、書き出し
if /ERR then { # エラーフラッグが立っていなければ
n_find +:= 1 # カウンタ+1
write(s," -> ",ss) # 組合せ文字列出力
writes(&errout,"!") # 合致表示
}
}
}
}
write(&errout)
# write(&errout,"終了:",&clock)
write("終了:",&clock)
# write(&errout,n_comb," 通りの組合せのうち、",n_find," 通りが辞書にありました。")
write(n_comb," 通りの組合せのうち、",n_find," 通りが辞書にありました。")
end
####################
# 正整数分割 generator
####################
# 5=3+2 等に数字分割する。この procedureは n_divdを呼びフィルターを掛けている。
# 分割パターンが多すぎる時に、制限をかけるために使用。
# arg [1]: 分割する元の数
# [2]: 最大分割数
# [3]: 最小数
# value : list
procedure n_divdf(r,ndiv,nmin)
every L := n_divd(r) do { # r の分割結果を取り出し
if *L <= ndiv then { # 分割数チェック(listのサイズチェック)
if L[*L] >= nmin then suspend L # 最小数チェック(降順に入っているので
} # 末尾の要素をチェック)
}
end
####################
# 正整数分割 generator
####################
# 5=3+2 等に分割する。分割は降順のみ許す。(例 5=2+3は除外)
# arg [1]: 分割される元の数(再帰の場合は、前の処理の余り)
# [2]: 最大数 (5=2+2+1 の場合に、最初の 2の時 3が余るが、再帰して 3の
# 分割を始める時、3からではなく 2から始めるための細工。降順手当。)
# value : 分解結果の数。listに格納
# Usage : every L := n_divd(r) do ...
procedure n_divd(r,max)
/max := r # 指定無きは、分割される元の数そのもの
if r < 1 then fail # 念のため
if r = 1 then return [1] # 再帰終了
# r >= 2 の場合
if r > max then rs := max # 分割(取り去る)数の最大数の設定。
else rs := r # 分割される数か 最大数指定の 小さい方
every i := rs to 1 by -1 do { # 上記指定数~1迄、順に-1しながら
rr := r -i # 新たな余り
if rr = 0 then suspend [i] # 余りが無ければ
# 余りがあれば、再帰処理
else if rr > i then suspend [i] ||| n_divd(rr,i) # 余りが大き過ぎる時
else suspend [i] ||| n_divd(rr)
}
end
# 以下は、Icon入門講座から引用
####################
# 英文字の組み合わせ(同一文字指定対応)
####################
# 名称変更 expermute -> exsperm
# arg [1]: s string
# value: string
# Usage: every ss := exsperm(s) do ...
# Icon入門講座2(18)
procedure exsperm(s) # string permutations
if *s = 0 then return "" #
ss := csort(s) # 文字列をソートする。(strings.icn)
suspend ss[i := new_pos(ss)] || exsperm(ss[1:i] || ss[i+1:0])
# ↑同一文字はスキップする
end
####################
# ソートされた文字列 sの左はじから、順に文字位置を出力する generator。
####################
# 手前の文字と同一ならスキップする。
# arg [1]: s string
# value: integer
# Usage: every i := new_pos(s) do ...
procedure new_pos(s)
ss := "" # 手前の文字を記憶しておく変数
every i := 1 to *s do {
if ss ~== s[i] then { # 手前の文字と違っていたら
ss := s[i] # 手前文字を更新
suspend i # i を返す。
}
}
end
####################
# BIPL(Icon基本ライブラリー)の strings.icnに含まれる 文字のソート procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ローカル変数宣言(無くても良い)
s1 := "" # 初期値クリア
every c := !cset(s) do # 引数を cset(文字集合)へ変換し順に取り出す。
every find(c, s) do # 取り出した文字で、引数文字列を検索し、
s1 ||:= c # 見つかる度に、文字を s1に足し込む。
return s1
end
# csetから !で要素を取り出す時には、アルファベット順に取り出せる。
-----$ DICREFPD.ICN ( lines:176 words:675 ) ----------------<cut here
dicrefpd sunburn 2 3 >e723 としますと、結果はこうなります。知らない単語が沢山でてきます。
-----^ E723 ( date:03-08-21 time:19:15 ) -------------------<cut here
english.dic を読込中です。
開始:19:15:50
終了:19:15:59
english.dic の読込を終わりました。
257650 語ありました。
sunburn を、最大分割数 2、最小文字長 3 にて分割して、その全てが辞書にあるかチェック中。
開始:19:15:59
bunsnur -> buns nur
bunsrun -> buns run
bunsurn -> buns urn
burnnus -> burn nus
burnsun -> burn sun
bursnun -> burs nun
nubsnur -> nubs nur
nubsrun -> nubs run
nubsurn -> nubs urn
nunsbur -> nuns bur
nunsrub -> nuns rub
nunsurb -> nuns urb
nursbun -> nurs bun
nursnub -> nurs nub
rubsnun -> rubs nun
runsbun -> runs bun
runsnub -> runs nub
snubnur -> snub nur
snubrun -> snub run
snuburn -> snub urn
sunburn -> sunburn
sunnbur -> sunn bur
sunnrub -> sunn rub
sunnurb -> sunn urb
urbsnun -> urbs nun
urnsbun -> urns bun
urnsnub -> urns nub
終了:19:15:59
2592 通りの組合せのうち、27 通りが辞書にありました。
-----$ E723 ( lines:37 words:125 ) -------------------------<cut here
dicrefpd midnight 2 3 >e823 としますと、結果はこうなります。
-----^ E823 ( date:03-08-21 time:19:16 ) -------------------<cut here
english.dic を読込中です。
開始:19:16:14
終了:19:16:22
english.dic の読込を終わりました。
257650 語ありました。
midnight を、最大分割数 2、最小文字長 3 にて分割して、その全てが辞書にあるかチェック中。
開始:19:16:23
dightmin -> dight min
dightnim -> dight nim
midnight -> midnight
mightdin -> might din
mightnid -> might nid
mindthig -> mind thig
nightdim -> night dim
nightmid -> night mid
thigmind -> thig mind
thingdim -> thing dim
thingmid -> thing mid
終了:19:16:26
60954 通りの組合せのうち、11 通りが辞書にありました。
-----$ E823 ( lines:21 words:61 ) --------------------------<cut here
8文字を4文字+4文字に分けた場合に、同じ組合せが2度出てきます。mindthig -> mind thig と thigmind -> thig mind のところです。今回は、とりあえず見なかったことに。(汗)
dicrefpd heavyrain 2 4 >e923 としますと、結果はこうなります。
-----^ E923 ( date:03-08-21 time:19:17 ) -------------------<cut here
english.dic を読込中です。
開始:19:16:40
終了:19:16:48
english.dic の読込を終わりました。
257650 語ありました。
heavyrain を、最大分割数 2、最小文字長 3 にて分割して、その全てが辞書にあるかチェック中。
開始:19:16:48
aviaryhen -> aviary hen
hairynave -> hairy nave
hairyvane -> hairy vane
hairyvena -> hairy vena
havenairy -> haven airy
haverayin -> haver ayin
hayervain -> hayer vain
hayervina -> hayer vina
heavyairn -> heavy airn
heavyrain -> heavy rain
heavyrani -> heavy rani
hieranavy -> hiera navy
hyenariva -> hyena riva
hyenavair -> hyena vair
invaryeah -> invar yeah
naiverhay -> naiver hay
naiveryah -> naiver yah
navierhay -> navier hay
navieryah -> navier yah
nerviayah -> nervi ayah
rainyhave -> rainy have
ravenhiya -> raven hiya
ravinehay -> ravine hay
ravineyah -> ravine yah
ravinyeah -> ravin yeah
rayahnevi -> rayah nevi
rayahvein -> rayah vein
rayahvine -> rayah vine
rivenayah -> riven ayah
vahineray -> vahine ray
vahinerya -> vahine rya
vahineyar -> vahine yar
vainerhay -> vainer hay
vaineryah -> vainer yah
veinyhaar -> veiny haar
viharanye -> vihara nye
viharayen -> vihara yen
vinerayah -> viner ayah
vineryaah -> vinery aah
vineryaha -> vinery aha
終了:19:17:21
545145 通りの組合せのうち、40 通りが辞書にありました。
-----$ E923 ( lines:50 words:178 ) -------------------------<cut here
この場合、545145 通りで、33秒かかっています。 これに1文字の曖昧検索ができるようににすると、単純に作ると 26倍かかるプログラムになりそうな気がします。2文字の曖昧検索にすると、更にその26倍?曖昧検索を入れるのでしたら、検索方式を根本的に考え直した方が良さそうです。heavyrainの例ですと、'a'が2個、'ehinrvy'の各文字が1個ずつの単語もしくは単語の組合せが辞書にあるか? という問題で、解法は色々あると思います。
9文字の文字列で54万通りというと、辞書単語数26万語を越えていますので、これ以上の文字数を対象とするには、方式を考え直した方が良いだろうと思います。今のプログラムの工夫でも速くなるとは思いますが。 あるいは、マシンを速い物にしたりメモリー増設するという手もありますが、先立つものが...
しばらく、Iconを動かしていませんでしたが、面白い題材を提供して頂いたお陰で、多少 Iconのリハビリができました。ありがとうございます。
Iconは、この題材のような文字列をいじりまわす処理のために作られた言語です。ご興味をお持ちになった方がいらっしゃれば、うれしいです。
風つかい(hshinoh@mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: Battery's not included / 森山威男&杉本喜代志
(2003/08/21 TSfree5.txt)
[Icon] Icon入門講座6 Iconミニ講座6(辞書参照の別方式)
風つかいさんのIcon講座。
- [Icon] Icon入門講座6 Iconミニ講座 [7/9/2006 (Sun.)]
- [Icon] Icon入門講座6 Iconミニ講座1(辞書読込)
- [Icon] Icon入門講座6 Iconミニ講座2(組合せ文字列の辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座3(正整数の分割)
- [Icon] Icon入門講座6 Iconミニ講座4(フィルター)
- [Icon] Icon入門講座6 Iconミニ講座5(文字列分解・辞書参照)
■ TSfree > Iconミニ講座6(辞書参照の別方式) 風つかい
前回で、ミニ講座は終わったつもりでいたのですが、辞書参照がどうもスッキリしませんので、ツラツラ考えていました。(シツコイ!)
特定文字を使った単語をスバヤク検索するのだったら、スバヤイ検索には、setか tableを使うのが良い。同一文字を使った文字列に、何か共通のインデックスを付けて、テーブルに登録しておけば、スバヤク検索できる。
ということで、辞書の単語の文字列をソートしたもので、インデックスを作っておいて、同一文字を使用した単語をまとめて、テーブルに登録しておき、検索したい文字列をソートしたもので、テーブルを参照すれば、一回の参照で、候補の単語群が見つかる。と、気が付きました。
例えば、"abcd"と "cdab"と "dcab"という単語があったとして、皆ソートすると、"abcd"となります。ソートした "abcd"を インデックス(Iconでは keyと言います。)として、値に list形式で、["abcd","cdab","dcab"]と格納しておけば、"abcd"で参照すれば、文字の配列を入れ替えた場合の候補が、一挙に出てきます。
この方式ですと、不明文字を、1~2文字入れて 26倍とか、26^2倍程度に処理が増えても、ガマンできる時間で処理ができそうです。
↓ソート
辞書 "abcd" ----> テーブル
"cdab" ----> key: "abcd" ->value: ["abcd","cdab","dcab"]
"dcab" ----> ↑
|参照
検索文字 --->ソート---------
という考えで、辞書読込・参照のプログラムを修正してみました。
辞書の登録文字にダブリがあります。setに登録する場合は問題は起きないのですがテーブルに登録する時に valueでダブルといけないので、チェックを入れてあります。
また keyは、小文字に統一して処理するようにしました。
-----^ DICREF2.ICN ( date:03-08-23 time:11:12 ) ------------<cut here
####################
# 辞書読込・使用文字種毎の分類をした辞書参照の習作。
####################
# dicref2.icn Rev.1.0 2003/08/23 windy 風つかい H.S.
####################
# Usage dicref2
# english.dicは、スペルチェック用の英単語が順に並んだもの。
# このプログラムのテストでは、DD SOFT SoundMixSpellコンポーネント
# Ver 0.3.0 に 同梱の辞書ファイルを使用。
# This file is in the public domain.
procedure main()
# 辞書読込
dic := "english.dic" # 辞書ファイル名
dir := open(dic) | stop(dic," が見つかりません") # 辞書ファイルオープン
S_dic := set() # 辞書ダブリチェック用 set生成
T_dic := table() # 辞書格納 table生成
write(dic," を読込中です。") # 辞書読み込み
write("開始:",&clock)
n := 0 # 辞書行数カウンタ
while word := read(dir) do { # 辞書を1行ずつ読み込んで、
n +:= 1
if n % 1000 = 0 then writes(&errout,"*") # 読み込み状況表示
if member(S_dic,word) then writes(&errout,"?") # 登録済みならエラー表示
else {
insert(S_dic,word) # setに登録
# 単語を小文字変換しソートしたものをインデックスにして格納
# 同一文字を含む単語は同じインデックスに listの要素として格納される。
# ↓文字列ソート
s_word := csort(map(word)) # 小文字へ変換し、ソートして
# ↑小文字変換
if member(T_dic,s_word) # 辞書テーブルにあるかチェック
then put(T_dic[s_word], word) # あれば、その listに追加
else T_dic[s_word] := [word] # 無ければ、listに入れて登録
}
}
close(dir) # 辞書ファイルクローズ
write(&errout)
write("終了:",&clock)
write(dic," の読込を終わりました。 ",*S_dic," 語ありました。")
write("同一文字で構\成される単語をまとめると、",*T_dic," 種類となります。")
# ↑Shift-JISでは、0x5cを含むので、"\"を補完。
# 辞書参照テスト
L := ["heavy","rain","yveah","niar","noword"] # テストデータ
write("参照テストを開始します。")
write("開始:",&clock)
every s := !L do { # テストデータを順次読み出し
ss := csort(map(s)) # テストデータを、小文字変換し、ソートして
writes(s,": ") # 変換前のデータを書き出し
if member(T_dic,ss) # 辞書にあれば
then {
every writes(" ",!T_dic[ss]) # 辞書内容を書き出す
write()
}
else write("辞書にありません。")
}
write("終了:",&clock)
write("参照テストを終わりました。")
end
####################
# BIPL(Icon基本ライブラリー)の strings.icnに含まれる 文字のソート procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ローカル変数宣言(無くても良い)
s1 := "" # 初期値クリア
every c := !cset(s) do # 引数を cset(文字集合)へ変換し順に取り出す。
every find(c, s) do # 取り出した文字で、引数文字列を検索し、
s1 ||:= c # 見つかる度に、文字を s1に足し込む。
return s1
end
# csetから !で要素を取り出す時には、アルファベット順に取り出せる。
-----$ DICREF2.ICN ( lines:76 words:243 ) ------------------<cut here
dicref2 >fff とすると、こういう結果になります。 辞書読込の際に、加工をしていますので、読込時間が 42秒に増えています。
-----^ FFF ( date:03-08-23 time:11:13 ) --------------------<cut here
english.dic を読込中です。
開始:11:12:25
終了:11:13:07
english.dic の読込を終わりました。 257650 語ありました。
同一文字で構成される単語をまとめると、223704 種類となります。
参照テストを開始します。
開始:11:13:07
heavy: heavy Yahve
rain: airn Arni Iran rain rani
yveah: heavy Yahve
niar: airn Arni Iran rain rani
noword: 辞書にありません。
終了:11:13:07
参照テストを終わりました。
-----$ FFF ( lines:14 words:33 ) ---------------------------<cut here
このプログラムでは、tableの値に listを入れていますが、Iconでは、tableの値に tableとか、listの値に tableや listとか、割と複雑なデータ構造を比較的簡単に実現できます。
風つかい(hshinoh@mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: Battery's not included / 森山威男&杉本喜代志
(2003/08/23 TSfree6.txt)
[Icon] Icon入門講座6 Iconミニ講座7(曖昧参照)
風つかいさんのIcon講座。
- [Icon] Icon入門講座6 Iconミニ講座 [7/9/2006 (Sun.)]
- [Icon] Icon入門講座6 Iconミニ講座1(辞書読込)
- [Icon] Icon入門講座6 Iconミニ講座2(組合せ文字列の辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座3(正整数の分割)
- [Icon] Icon入門講座6 Iconミニ講座4(フィルター)
- [Icon] Icon入門講座6 Iconミニ講座5(文字列分解・辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座6(辞書参照の別方式)
■ TSfree > Iconミニ講座7(曖昧参照) 風つかい
やめられない・止まらないエビセン体質のため、ついついミニ講座の続きを考えてしまいます。 曖昧検索を入れてみました。コマンドラインから、英文文字列を指定して辞書検索を行いますが、'.'をワイルドカード (a-z)と見なせるようにしてみました。'.'が2文字以上の場合は、"ab"と "ba"のようなものは、別に検索しないように細工を入れました。&lcaseは、英小文字に対応する組込キーワードです。
-----^ DICREFP2.ICN ( date:03-08-23 time:21:51 ) -----------<cut here
####################
# 辞書読込・使用文字種毎の分類をした辞書参照で、曖昧検索対応。
####################
# dicrep2.icn Rev.1.0 2003/08/23 windy 風つかい H.S.
####################
# Usage dicrefp2 英文字列(.はワイルドカード)
# english.dicは、スペルチェック用の英単語が順に並んだもの。
# このプログラムのテストでは、DD SOFT SoundMixSpellコンポーネント
# Ver 0.3.0 に 同梱の辞書ファイルを使用。
# This file is in the public domain.
procedure main(args)
# コマンドライン引数チェック。無ければ Usage表示
if *args < 1 then stop("dicrefp2 英単語 ( . はワイルドカード)")
# 辞書読込
dic := "english.dic" # 辞書ファイル名
dir := open(dic) | stop(dic," が見つかりません") # 辞書ファイルオープン
S_dic := set() # 辞書ダブリチェック用 set生成
T_dic := table() # 辞書格納 table生成
write(dic," を読込中です。") # 辞書読み込み
write("開始:",&clock)
n := 0 # 辞書行数カウンタ
while word := read(dir) do { # 辞書を1行ずつ読み込んで、
n +:= 1
if n % 1000 = 0 then writes(&errout,"*") # 読み込み状況表示
if member(S_dic,word) then writes(&errout,"?") # 登録済みならエラー表示
else {
insert(S_dic,word) # setに登録
# 単語を小文字変換しソートしたものをインデックスにして格納
# 同一文字を含む単語は同じインデックスに listの要素として格納される。
# ↓文字列ソート
s_word := csort(map(word)) # 小文字へ変換し、ソートして
# ↑小文字変換
if member(T_dic,s_word) # 辞書テーブルにあるかチェック
then put(T_dic[s_word], word) # あれば、その listに追加
else T_dic[s_word] := [word] # 無ければ、listに入れて登録
}
}
close(dir) # 辞書ファイルクローズ
write(&errout)
write("終了:",&clock)
write(dic," の読込を終わりました。 ",*S_dic," 語ありました。")
write("同一文字で構\成される単語をまとめると、",*T_dic," 種類となります。")
# ↑Shift-JISでは、0x5cを含むので、"\"を補完。
# 辞書参照テスト
# コマンドラインの引数にて、辞書を参照
c_word := args[1]
s_word := deletec(c_word,'.') # コマンドライン文字列から '.'を削除
n := *c_word -*s_word # '.'の数
n_comb := 0 # 組合せ数カウンタ
n_find := 0 # 辞書にある件数カウンタ
write(c_word," の組合せが辞書にあるかチェック中です。")
write("開始:",&clock)
every s := mscombd(string(&lcase),n) do { # ワイルドカード対応文字を取り出し
n_comb +:= 1 # 組合せ数カウンタ+1
ss := csort(map(s || s_word)) # コマンドライン引数の '.'以外の部分に足し
# 小文字変換し、ソートして
if member(T_dic,ss) # 辞書にあれば
then {
n_find +:= 1 # 辞書にある件数カウンタ+1
writes(&errout,"!") # 発見表示
writes(ss,": ") # 変換前のデータを書き出し
every writes(" ",!T_dic[ss]) # 辞書内容を書き出す
write()
}
}
write(&errout)
write("終了:",&clock)
write(n_comb," 通りの組合せのうち、",n_find," 通りが辞書にありました。")
end
#############################
# 文字列から重複して、n個、降順のものを取り出す generator
#############################
# arg [1]: string
# [2]: integer
# value : string
# Usage : every ss := mscombd(s,n) do ..
# ("abc",2) -> "aa","ab","ac","bb","bc","cc"
procedure mscombd(s,n)
if n =0 then return "" # 再帰終了
every i := 1 to *s do { # 1~文字列長まで
# ↓ i番目の文字を取り出して
suspend s[i] || mscombd(s[i:0],n-1)
} # ↑それ以降の文字と組み合わせる
end
# BIPL(Icon基本ライブラリー)より
####################
# strings.icnに含まれる 文字のソート procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ローカル変数宣言(無くても良い)
s1 := "" # 初期値クリア
every c := !cset(s) do # 引数を cset(文字集合)へ変換し順に取り出す。
every find(c, s) do # 取り出した文字で、引数文字列を検索し、
s1 ||:= c # 見つかる度に、文字を s1に足し込む。
return s1
end
# csetから !で要素を取り出す時には、アルファベット順に取り出せる。
####################
# strings.icnに含まれる 文字の削除 procedure
####################
procedure deletec(s, c) #: delete characters
local result # ローカル宣言(無くても良い)
result := "" # 削除後の文字列格納エリア
s ? { # sを走査対象として、
while result ||:= tab(upto(c)) do # cが見つかる迄の文字列を足し込んで
tab(many(c)) # c以外の文字までスキップ
return result ||:= tab(0) # 余りの文字を足し込む
}
end
-----$ DICREFP2.ICN ( lines:123 words:404 ) ----------------<cut here
dicrefp2 sunris. >ggg と、ワイルドカードを 1ついれた場合はこんな結果になります。
-----^ GGG ( date:03-08-23 time:21:52 ) --------------------<cut here
english.dic を読込中です。
開始:21:51:57
終了:21:52:40
english.dic の読込を終わりました。 257650 語ありました。
同一文字で構成される単語をまとめると、223704 種類となります。
sunris. の組合せが辞書にあるかチェック中です。
開始:21:52:40
ainrssu: Russian Surnias
dinrssu: sundris
einrssu: insures Serinus sunrise
終了:21:52:40
26 通りの組合せのうち、3 通りが辞書にありました。
-----$ GGG ( lines:12 words:25 ) ---------------------------<cut here
風つかい(hshinoh@mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: 日本組曲 / 有馬徹とノーチェ・クバーナ with 杉本喜代志
(2003/08/23 TSfree7.txt)
[Icon] Icon入門講座6 Iconミニ講座8(辞書分割)
風つかいさんのIcon講座。
- [Icon] Icon入門講座6 Iconミニ講座 [7/9/2006 (Sun.)]
- [Icon] Icon入門講座6 Iconミニ講座1(辞書読込)
- [Icon] Icon入門講座6 Iconミニ講座2(組合せ文字列の辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座3(正整数の分割)
- [Icon] Icon入門講座6 Iconミニ講座4(フィルター)
- [Icon] Icon入門講座6 Iconミニ講座5(文字列分解・辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座6(辞書参照の別方式)
- [Icon] Icon入門講座6 Iconミニ講座7(曖昧参照)
■ TSfree > Iconミニ講座8(辞書分割) 風つかい
辞書にインデックスを付けて格納するようにしたせいで、辞書読込が40秒以上になってしまいました。流石に、待ち時間がツライので、辞書から必要な字数の部分だけ、読み込むようにしました。辞書を、まず文字数毎のファイルに分割します。辞書を、単語の文字数毎に、テーブルに読込みます。次に文字数毎のファイルに出力します。辞書のダブリチェックも入れて、出力ファイルはダブリを無くします。
english.dic T_dic
+----------+ +-----------------------------+
|辞書 | |テーブル |
|ファイル |--->|key:1 ->value:[a,i] |---> ファイル e01へ書き出し
| | |key:2 ->value:[AA,Ab,AB,...] |---> ファイル e02へ書き出し
+----------+ | |
+-----------------------------+
-----^ DICDIV.ICN ( date:03-08-24 time:12:27 ) -------------<cut here
####################
# 辞書を文字数毎に分割
####################
# dicdiv.icn Rev.1.0 2003/08/24 windy 風つかい H.S.
####################
# Usage dicdiv dictionary_name
# 辞書をファイル読込高速化のため、字数毎に分割するのに使用
# english.dicは、スペルチェック用の英単語が順に並んだもの。
# このプログラムのテストでは、DD SOFT SoundMixSpellコンポーネント
# Ver 0.3.0 に 同梱の辞書ファイルを使用。
# This file is in the public domain.
procedure main(args)
if *args < 1 then stop("dicdiv dictionary_name")
dic := args[1]
# 辞書読込
dir := open(dic) | stop(dic," が見つかりません") # ファイルオープン
n := 0 # ファイル行数カウンタ
S_dic := set() # ダブリチェック用 set生成
T_dic := table() # 字数毎ファイル格納 table生成
write(&errout,dic," を読込中です。") # ファイル読み込み
write(&errout,"開始:",&clock)
while word := read(dir) do { # ファイルを1行ずつ読み込んで、
n +:= 1
if n % 1000 = 0 then writes(&errout,"*") # 読み込み状況表示
if member(S_dic,word) then writes(&errout,"?") # 登録済みならエラー表示
else {
insert(S_dic,word) # setに登録
# 文字数を keyとしたテーブルに list形式で格納
if member(T_dic,*word) # テーブルにあるかチェック
then put(T_dic[*word], word) # あれば、その listに追加
else T_dic[*word] := [word] # 無ければ、listに入れて登録
}
}
close(dir) # ファイルクローズ
write(&errout)
write(&errout,"終了:",&clock)
write(&errout,dic," の読込を終わりました。 ",*S_dic," 語ありました。")
# 字数毎辞書 書き出し
write(&errout,"辞書の文字数別分割を始めます。")
write(&errout,"開始:",&clock)
every x := key(T_dic) do {
# ↓右寄せ桁合わせ関数
f_out := dic[1] || right(x,2,"0") # 出力ファイル名: 元のファイル名の
# 先頭1字+字数
# ↓書込モードでファイルオープン
dir := open(f_out,"w") | stop(f_out,"ファイルが開けません。")
write(&errout,x,"字: ",f_out,": ",*T_dic[x]," 語あります。")
every write(dir,!T_dic[x]) # x字の list要素を全て書き出し
close(dir)
}
write(&errout,"終了:",&clock)
write(&errout,"辞書の文字数毎の分割を終わりました。")
end
-----$ DICDIV.ICN ( lines:59 words:187 ) -------------------<cut here
dicdiv english.dic としますと、次のように分割されます。
-----^ DIR.E ( date:03-08-24 time:12:41 ) ------------------<cut here
ドライブ D: のボリュームラベルは DATA
ボリュームシリアル番号は 112D-12DF
ディレクトリは D:\2003\Unicon\TS_NW\CROSS\CROSS9
E01 6 03-08-24 12:28 E01
E02 1,444 03-08-24 12:28 E02
E03 9,070 03-08-24 12:28 E03
E04 35,286 03-08-24 12:28 E04
E05 87,381 03-08-24 12:28 E05
E06 172,848 03-08-24 12:28 E06
E07 286,461 03-08-24 12:28 E07
E08 386,510 03-08-24 12:28 E08
E09 425,040 03-08-24 12:28 E09
E10 399,012 03-08-24 12:28 E10
E11 329,615 03-08-24 12:28 E11
E12 248,346 03-08-24 12:28 E12
E13 176,520 03-08-24 12:28 E13
E14 122,784 03-08-24 12:28 E14
E15 79,084 03-08-24 12:28 E15
E16 49,194 03-08-24 12:28 E16
E17 29,716 03-08-24 12:28 E17
E18 17,500 03-08-24 12:28 E18
E19 9,093 03-08-24 12:28 E19
E20 3,916 03-08-24 12:28 E20
E21 1,932 03-08-24 12:28 E21
E22 912 03-08-24 12:28 E22
E23 450 03-08-24 12:28 E23
E24 338 03-08-24 12:28 E24
E25 54 03-08-24 12:28 E25
E27 29 03-08-24 12:28 E27
E28 30 03-08-24 12:28 E28
E29 31 03-08-24 12:28 E29
E30 32 03-08-24 12:28 E30
E31 33 03-08-24 12:28 E31
E32 34 03-08-24 12:28 E32
ENGLISH DIC 2,875,008 03-07-21 9:33 ENGLISH.DIC
32 個 5,747,709 バイトのファイルがあります.
0 ディレクトリ 1,183,285,248 バイトの空きがあります.
-----$ DIR.E ( lines:39 words:177 ) ------------------------<cut here
一番長い単語は、32文字で、dichlorodiphenyltrichloroethanes ですが、なんという意味なんでしょうね。辞書参照を、この分割辞書の必要なファイルだけ読み込むように、変更しました。
-----^ DICREFP3.ICN ( date:03-08-24 time:12:48 ) -----------<cut here
####################
# 辞書読込・使用文字種毎の分類をした辞書参照で、曖昧検索対応。
####################
# dicrep3.icn Rev.1.0 2003/08/23 windy 風つかい H.S.
####################
# Usage dicrefp3 英文字列(.はワイルドカード)
# 文字数毎に分割された辞書ファイルを使用。 english.dicを分割。
# english.dicは、スペルチェック用の英単語が順に並んだもの。
# このプログラムのテストでは、DD SOFT SoundMixSpellコンポーネント
# Ver 0.3.0 に 同梱の辞書ファイルを使用。
# This file is in the public domain.
procedure main(args)
# コマンドライン引数チェック。無ければ Usage表示
if *args < 1 then stop("dicrefp3 英単語 ( . はワイルドカード)")
# 辞書読込
n_dic := *args[1] # 引数の文字数
# ↓右寄せ桁合わせ関数
dic := "e" || right(n_dic,2,"0") # 辞書ファイル名
dir := open(dic) | stop("その文字数の辞書は見つかりません")
# 辞書ファイルオープン
T_dic := table() # 辞書格納 table生成
write(" ",n_dic,"文字用辞書 ",dic," を読込中です。") # 辞書読み込み
write("開始:",&clock)
n := 0 # 辞書行数カウンタ
while word := read(dir) do { # 辞書を1行ずつ読み込んで、
n +:= 1
if n % 1000 = 0 then writes(&errout,"*") # 読み込み状況表示
# 単語を小文字変換しソートしたものをインデックスにして格納
# 同一文字を含む単語は同じインデックスに listの要素として格納される。
# ↓文字列ソート
s_word := csort(map(word)) # 小文字へ変換し、ソートして
# ↑小文字変換
if member(T_dic,s_word) # 辞書テーブルにあるかチェック
then put(T_dic[s_word], word) # あれば、その listに追加
else T_dic[s_word] := [word] # 無ければ、listに入れて登録
}
close(dir) # 辞書ファイルクローズ
write(&errout)
write("終了:",&clock)
write(" ",n_dic,"文字用辞書 ",dic," の読込を終わりました。",n," 語ありました。")
write("同一文字で構\成される単語をまとめると、",*T_dic," 種類となります。")
# ↑Shift-JISでは、0x5cを含むので、"\"を補完。
# 辞書参照テスト
# コマンドラインの引数にて、辞書を参照
c_word := args[1]
s_word := deletec(c_word,'.') # コマンドライン文字列から '.'を削除
n := *c_word -*s_word # '.'の数
n_comb := 0 # 組合せ数カウンタ
n_find := 0 # 辞書にある件数カウンタ
write(c_word," の組合せが辞書にあるかチェック中です。")
write("開始:",&clock)
every s := mscombd(string(&lcase),n) do { # ワイルドカード対応文字を取り出し
n_comb +:= 1 # 組合せ数カウンタ+1
ss := csort(map(s || s_word)) # コマンドライン引数の '.'以外の部分に足し
# 小文字変換し、ソートして
if member(T_dic,ss) # 辞書にあれば
then {
n_find +:= 1 # 辞書にある件数カウンタ+1
writes(&errout,"!") # 発見表示
writes(ss,": ") # 変換前のデータを書き出し
every writes(" ",!T_dic[ss]) # 辞書内容を書き出す
write()
}
}
write(&errout)
write("終了:",&clock)
write(n_comb," 通りの組合せのうち、",n_find," 通りが辞書にありました。")
end
#############################
# 文字列から重複して、n個、降順のものを取り出す generator
#############################
# arg [1]: string
# [2]: integer
# value : string
# Usage : every ss := mscombd(s,n) do ..
# ("abc",2) -> "aa","ab","ac","bb","bc","cc"
procedure mscombd(s,n)
if n =0 then return "" # 再帰終了
every i := 1 to *s do { # 1~文字列長まで
# ↓ i番目の文字を取り出して
suspend s[i] || mscombd(s[i:0],n-1)
} # ↑それ以降の文字と組み合わせる
end
# BIPL(Icon基本ライブラリー)より
####################
# strings.icnに含まれる 文字のソート procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ローカル変数宣言(無くても良い)
s1 := "" # 初期値クリア
every c := !cset(s) do # 引数を cset(文字集合)へ変換し順に取り出す。
every find(c, s) do # 取り出した文字で、引数文字列を検索し、
s1 ||:= c # 見つかる度に、文字を s1に足し込む。
return s1
end
# csetから !で要素を取り出す時には、アルファベット順に取り出せる。
####################
# strings.icnに含まれる 文字の削除 procedure
####################
procedure deletec(s, c) #: delete characters
local result # ローカル宣言(無くても良い)
result := "" # 削除後の文字列格納エリア
s ? { # sを走査対象として、
while result ||:= tab(upto(c)) do # cが見つかる迄の文字列を足し込んで
tab(many(c)) # c以外の文字までスキップ
return result ||:= tab(0) # 余りの文字を足し込む
}
end
-----$ DICREFP3.ICN ( lines:120 words:401 ) ----------------<cut here
(追記 mscombdという命名は間違っていますね。最後の dは降順という意味なのですが、ご覧の通り、ソートを一切かけていませんので、降順にはなりません。この procedureに対する名前は、mscombが正しいのです。)
dicrefp3 mi.nigh. >hhh とすると、次のような結果になります。だいぶ、辞書読込時間が短くなりました。
-----^ HHH ( date:03-08-24 time:14:13 ) --------------------<cut here
8文字用辞書 e08 を読込中です。
開始:14:13:51
終了:14:13:54
8文字用辞書 e08 の読込を終わりました。38651 語ありました。
同一文字で構成される単語をまとめると、32836 種類となります。
mi.nigh. の組合せが辞書にあるかチェック中です。
開始:14:13:54
acghiimn: Michigan
cghiimnr: chirming
cghiimns: michings
cghiimnt: mitching
dghiimnt: midnight
ghiimmns: shimming
ghiimmnw: whimming
ghiimnnu: inhuming
ghiimnst: smithing
終了:14:13:54
351 通りの組合せのうち、9 通りが辞書にありました。
-----$ HHH ( lines:18 words:36 ) ---------------------------<cut here
風つかい(hshinoh@mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: Battery's not included / 森山威男&杉本喜代志
(2003/08/24 TSfree8.txt)
[Icon] Icon入門講座6 Iconミニ講座9(分配組合せ)
風つかいさんのIcon講座。
- [Icon] Icon入門講座6 Iconミニ講座 [7/9/2006 (Sun.)]
- [Icon] Icon入門講座6 Iconミニ講座1(辞書読込)
- [Icon] Icon入門講座6 Iconミニ講座2(組合せ文字列の辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座3(正整数の分割)
- [Icon] Icon入門講座6 Iconミニ講座4(フィルター)
- [Icon] Icon入門講座6 Iconミニ講座5(文字列分解・辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座6(辞書参照の別方式)
- [Icon] Icon入門講座6 Iconミニ講座7(曖昧参照)
- [Icon] Icon入門講座6 Iconミニ講座8(辞書分割)
■ TSfree > Iconミニ講座9(分配組合せ) 風つかい
文字列で、辞書参照をするときに、文字の組合せを作ろうと思うのですが、例えば
-----^ PCOMB1.ICN ( date:03-08-25 time:20:43 ) -------------<cut here
####################
# 文字列分配プログラムの習作1
####################
# pcomb1.icn Rev.1.0 2003/08/25 windy 風つかい H.S.
####################
# This file is in the public domain.
procedure main()
L := [[4],[3,1],[2,2],[2,1,1],[1,1,1,1]] # 文字列分配パターン(文字数)
s := "abcd" # テスト文字列
write(s)
every LL := !L do { # 分配文字数パターンから順次取り出して、
write("---") # 表示用
every LLL := pcomb(s,LL) do { # 分配結果を順次取り出して、
writes(" ->") # 表示用
every writes(" ",!LLL) # 出力する。
write()
}
}
end
####################
# 分配の組合せ
####################
# arg [1]: string 分配する英文字列:分配パターンのトータルに合ってること。
# [2]: list 分配パターン(降順の list)
# value : list 分割された文字列
# Usage : every LL := pcomb(s,L) do ..
# ("abc",[2,1]) -> ["ab","c"],["ac","b"],["bc","a"]
# 同一分配数が複数ある場合は、無駄が生じる。
# 例:("abcd",[2,2])の場合に、["ab","cd"] と ["cd","ab"]の両方が出る。
procedure pcomb(s,L)
if *L = 1 then return [s] # 再帰終了
if L[1] = 1 then { # 後は、順に1文字ずつ listに入れるだけ
return [s[1]] ||| pcomb(s[2:0], L[2:0]) #
} # ↑先頭文字 ↑残り文字列 ↑残りのリスト
# 2文字以上の指定ならば、
every ss := scomb(s,L[1]) do { # 文字の組合せを作って
suspend [ss] ||| pcomb(ssub(s,ss),L[2:0]) # 残りの文字のため再帰
} # ↑組合せ文字 ↑残り文字列 ↑残りのリスト
end
####################
# 文字列の引き算
####################
# arg [1]: string 被削除文字列
# [2]: string 削除文字列
# value : string 結果文字列
# 文字列 s1の先頭から、文字列 s2の文字を削除。1:1で削除。
# ("abcabc","abd") -> "cabc" s1に無い文字は無視される。
procedure ssub(s1,s2)
every c := !s2 do { # s2から1文字ずつ取り出して
ss := "" # 上記文字を削除後の文字列の格納エリア
s1 ? { # s1を走査対象として、
if ss ||:= tab(upto(c)) then { # 文字が見つかれば そこ迄の文字列を
# ssに足し込み
move(1) # 1文字スキップ
ss ||:= tab(0) # 残りの文字列を足し込み
s1 := ss # s1更新
}
}
}
return s1
end
####################
# 文字列の nCm (n = *s) n個文字列から、m文字を選ぶ。 generator
####################
# 1998/04/16 windy 名称変更 comb -> scomb (BIPLとダブルので)
# stringの組み合わせ
# nCm (n = *s) n個のものから、m個を選ぶ。
# arg: [1]: s: string
# [2]: m: integer
# value: string
# Usage: every ss := scomb(s,m) do ...
# Icon入門講座3(11)
procedure scomb(s,m)
/m := *s # デフォルト nCn (n = m = *s)
if m = 0 then return "" # mを文字数カウンターに使う。
# 0なったら、そこで打ち止め。
suspend s[i := 1 to *s] || scomb(s[i+1 : 0], m -1)
#↑ 1文字選ぶ ↑ ↑←前で選んだ文字以降 ↑指定文字数に
# | の文字列に対し同じ 文字列を抑え
# | 処理を行う。 るためのカウ
# 文字列の連結 ンター
end
-----$ PCOMB1.ICN ( lines:88 words:334 ) -------------------<cut here
pcomb1 > iii とすると、こうなります。
-----^ III ( date:03-08-25 time:20:45 ) --------------------<cut here
abcd
---
-> abcd
---
-> abc d
-> abd c
-> acd b
-> bcd a
---
-> ab cd
-> ac bd
-> ad bc
-> bc ad
-> bd ac
-> cd ab
---
-> ab c d
-> ac b d
-> ad b c
-> bc a d
-> bd a c
-> cd a b
---
-> a b c d
-----$ III ( lines:24 words:67 ) ---------------------------<cut here
結果を見てみますと、同じ文字数を連続して取り出す(2文字を2回)時に、["ab","cd"] と ["cd","ab"]が、両方でてきます。これは、片方だけで良いのです。 よく見ると、不要なケースは、結果の並びが、降順になっていないケースみたいです。そこで、降順の組合わせだけ取り出すように、修正してみました。文字列の比較式で、<< という記号が出てきますが、これは文字列が辞書順で先か後かの比較を行うものです。文字列組合せの scombが、同一文字指定に対応していませんでしたので、対応するexscombを作りました。
-----^ PCOMB2.ICN ( date:03-08-25 time:20:44 ) -------------<cut here
####################
# 文字列分配プログラムの習作2
####################
# pcomb2.icn Rev.1.0 2003/08/25 windy 風つかい H.S.
####################
# This file is in the public domain.
procedure main()
L := [[4],[3,1],[2,2],[2,1,1],[1,1,1,1]] # 文字列分配パターン(文字数)
s := "abcd" # テスト文字列
write(s)
every LL := !L do { # 分配文字数パターンから順次取り出して、
write("---") # 表示用
every LLL := expcomb(s,LL) do { # 分配結果を順次取り出して、
writes(" ->") # 表示用
every writes(" ",!LLL) # 出力する。
write()
}
}
end
####################
# 分配の組合せ
####################
# arg [1]: string 分配する英文字列:分配パターンのトータルに合ってること。
# [2]: list 分配パターン(降順の list)
# [3]: string 前の文字列(同一文字数指定の場合に降順のものだけ選ぶための)
# value : list 分割された文字列( listに格納)
# Usage : every LL := expcomb(s,L) do ..
# ("abc", [2,1]) -> ["ab","c"], ["ac","b"], ["bc","a"]
# ("abcd",[2,2]) -> ["ab","cd"],["ac","bd"],["ad","bc"]
procedure expcomb(s,L,s_ref)
/s_ref := "" # 指定なければ、空文字
s := csort(s) # 文字列ソート
if *L = 1 then { # パターン要素の最後で、
if L[1] = *s_ref then { # 前回と文字数が同じで、
if s << s_ref then return &fail # 辞書順で前なら、失敗させる。
}
return [s] # ↑で、無ければ、文字列を返す。
}
# 1文字の文字列指定ならば、後は、順に1文字ずつ listに入れるだけ
if L[1] = 1 then { # 1文字の文字列指定ならば、
# 後は、順に1文字ずつ listに入れるだけ
return [s[1]] ||| expcomb(s[2:0], L[2:0])
} # ↑先頭文字 ↑残り文字列 ↑残りのリスト
# 2文字以上の文字列指定ならば、
every ss := exscomb(s,L[1]) do { # 文字の組合せを作って
if *ss = *s_ref then { # 前回と文字数が同じで、
if ss << s_ref then return &fail # 辞書順で前なら、失敗させる。
} # ↓参照用文字列
suspend [ss] ||| expcomb(ssub(s,ss),L[2:0],ss)
} # ↑組合せ文字 ↑残り文字列 ↑残りのリスト
end
####################
# 文字列の引き算
####################
# arg [1]: string 被削除文字列
# [2]: string 削除文字列
# value : string 結果文字列
# 文字列 s1の先頭から、文字列 s2の文字を削除。1:1で削除。
# ("abcabc","abd") -> "cabc" s2にある文字で、s1に無い文字は無視される。
procedure ssub(s1,s2)
every c := !s2 do { # s2から1文字ずつ取り出して
ss := "" # 上記文字を削除後の文字列の格納エリア
s1 ? { # s1を走査対象として、
if ss ||:= tab(upto(c)) then { # 文字が見つかれば そこ迄の文字列を
# ssに足し込み
move(1) # 1文字スキップ
ss ||:= tab(0) # 残りの文字列を足し込み
s1 := ss # s1更新
}
}
}
return s1
end
####################
# 文字列の nCm (n = *s) n個文字列から、m文字を選ぶ。 generator
####################
# stringの組み合わせ
# nCm (n = *s) n個のものから、m個を選ぶ。
# arg: [1]: s: string
# [2]: m: integer
# value: string
# Usage: every ss := exscomb(s,m) do ...
# Icon入門講座3(11)scomb()を同一文字指定対応に拡張
procedure exscomb(s,m)
initial {
s := csort(s) # 文字列をソートする。(BIPL:strings.icn)
/m := *s # デフォルト nCn (n = m = *s)
}
if m = 0 then return "" # mを文字数カウンターに使う。
# 0なったら、そこで打ち止め。
suspend s[i := new_pos(s)] || exscomb(s[i+1 : 0], m -1)
#↑ 1文字選ぶ ↑ ↑←前で選んだ文字以降 ↑指定文字数に
# | の文字列に対し同じ 文字列を抑え
# | 処理を行う。 るためのカウ
# 文字列の連結 ンター
end
####################
# ソートされた文字列 sの左はじから、順に文字位置を出力する generator。
####################
# 手前の文字と同一ならスキップする。
# arg [1]: s string
# value: integer
# Usage: every i := new_pos(s) do ...
procedure new_pos(s)
ss := "" # 手前の文字を記憶しておく変数
every i := 1 to *s do {
if ss ~== s[i] then { # 手前の文字と違っていたら
ss := s[i] # 手前文字を更新
suspend i # i を返す。
}
}
end
####################
# BIPL(Icon基本ライブラリー)の strings.icnに含まれる 文字のソート procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ローカル変数宣言(無くても良い)
s1 := "" # 初期値クリア
every c := !cset(s) do # 引数を cset(文字集合)へ変換し順に取り出す。
every find(c, s) do # 取り出した文字で、引数文字列を検索し、
s1 ||:= c # 見つかる度に、文字を s1に足し込む。
return s1
end
# csetから !で要素を取り出す時には、アルファベット順に取り出せる。
-----$ PCOMB2.ICN ( lines:136 words:501 ) ------------------<cut here
pcomb2 > jjj とするとこうなります。2文字を2回取り出す所での重複がなくなりました。 なんとか、ケースを減らせたみたいです。
-----^ JJJ ( date:03-08-25 time:20:44 ) --------------------<cut here
abcd
---
-> abcd
---
-> abc d
-> abd c
-> acd b
-> bcd a
---
-> ab cd
-> ac bd
-> ad bc
---
-> ab c d
-> ac b d
-> ad b c
-> bc a d
-> bd a c
-> cd a b
---
-> a b c d
-----$ JJJ ( lines:21 words:58 ) ---------------------------<cut here
風つかい(hshinoh@mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: 蝉の声 / 近所の蝉たち
(2003/08/25 Ts_free9.txt)
[Icon] Icon入門講座6 Iconミニ講座10(分割文字で辞書参照)
風つかいさんのIcon講座。
- [Icon] Icon入門講座6 Iconミニ講座 [7/9/2006 (Sun.)]
- [Icon] Icon入門講座6 Iconミニ講座1(辞書読込)
- [Icon] Icon入門講座6 Iconミニ講座2(組合せ文字列の辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座3(正整数の分割)
- [Icon] Icon入門講座6 Iconミニ講座4(フィルター)
- [Icon] Icon入門講座6 Iconミニ講座5(文字列分解・辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座6(辞書参照の別方式)
- [Icon] Icon入門講座6 Iconミニ講座7(曖昧参照)
- [Icon] Icon入門講座6 Iconミニ講座8(辞書分割)
- [Icon] Icon入門講座6 Iconミニ講座9(分配組合せ)
■ TSfree > Iconミニ講座10(分割文字で辞書参照) 風つかい
さて、まとめで、フルスペックのプログラムにまとめましょう。
- 入力文字列を分割したもので、辞書参照。
- 不明文字対応のため、曖昧検索指定。
- 辞書は、文字数別に分割し、必要なものだけ使う。辞書分割の際にダブリチェックして、分割後の辞書ファイルにはダブリが無いので、このプログラムでは単語のダブリチェックは削除します。
というところで、まとめると次のようになります。
尚、試して頂きやすいように、全ての procedureを1つのファイルにしていますが、サブ procedureを、別のファイルにして、mainファイルから linkするようにもできます。
-----^ DICREFP5.ICN ( date:03-08-25 time:20:05 ) -----------<cut here
####################
# 文字列の組合せで、辞書参照。曖昧検索。分割辞書。ワイルドカード未対応
####################
# dicrefp5.icn Rev.1.0 2003/08/25 windy 風つかい H.S.
####################
# Usage dicrefp5 英文字列(.はワイルドカード)
# 文字数毎に分割された辞書ファイルを使用。 english.dicを分割。
# english.dicは、スペルチェック用の英単語が順に並んだもの。
# このプログラムのテストでは、DD SOFT SoundMixSpellコンポーネント
# Ver 0.3.0 に 同梱の辞書ファイルを使用。
# This file is in the public domain.
procedure main(args)
# コマンドライン引数チェック。無ければ Usage表示
if *args < 1 then stop("dicrefp5 英単語(.はワイルドカード)",
" 最大分割数 最小文字長")
# コマンドラインの引数から、辞書を読込
c_word := args[1] # コマンドラインの英文字列
ndiv := \args[2] | 1 # 分割数指定無しは、1(分割せず)
nmin := \args[3] | *c_word # 最小文字長指定無しは、引数文字列長
# 分割パターン格納
L_lpat := [] # 文字列分割パターン格納 list
every put(L_lpat,n_divdf(*c_word,ndiv,nmin)) # 分割パターン格納
# 必要な文字数に対応する辞書の読込
S_pat := set() # 文字数格納 set(指定文字数辞書読込のため)
every L := !L_lpat do every insert(S_pat,!L) # 文字数を全て 格納
T_dic := table() # 辞書格納 table生成
every n_pat := !S_pat do {
# ↓右寄せ桁合わせ関数
dic := "e" || right(n_pat,2,"0") # 辞書ファイル名
dir := open(dic) | stop(" ",n_pat,"文字用の辞書が見つかりません。")
# 辞書ファイルオープン
writes(" ",n_pat,"文字用辞書 ",dic," を読込中です。開始:",&clock)
n := 0 # 辞書行数カウンタ
while word := read(dir) do { # 辞書を1行ずつ読み込んで、
n +:= 1
if n % 1000 = 0 then writes(&errout,"*") # 読み込み状況表示
# 単語を小文字変換しソートしたものをインデックスにして格納
# 同一文字を含む単語は同じインデックスに listの要素として格納される。
# ↓文字列ソート
s_word := csort(map(word)) # 小文字へ変換し、ソートして
# ↑小文字変換
if member(T_dic,s_word) # 辞書テーブルにあるかチェック
then put(T_dic[s_word], word) # あれば、その listに追加
else T_dic[s_word] := [word] # 無ければ、listに入れて登録
}
close(dir) # 辞書ファイルクローズ
write(&errout)
write(" 終了:",&clock," ",n,"語ありました。")
}
write("\n",c_word," を、最大分割数 ",ndiv,"、最小文字長 ",nmin,
" にて分割してチェック。開始:",&clock)
# 辞書参照
n_comb := 0 # 組合せ数カウンタ
n_find := 0 # 辞書にある件数カウンタ
s_word := deletec(c_word,'.') # コマンドライン文字列から '.'を削除
n_dot := *c_word -*s_word # '.'の数
# ↓英小文字
every s_wild := mscombd(string(&lcase),n_dot) do { # ワイルドカード文字を、
s_check := s_wild || map(s_word) # コマンドライン引数の '.'以外に足し、
every Lpat:= !L_lpat do { # 分配文字数パターンから順次取り出して、
every Lword := expcomb(s_check,Lpat) do { # 分配結果を順次取り出して、
n_comb +:= 1 # チェック回数カウンタ+1
if n_comb % 1000 = 0 then writes(&errout,"*") # チェック状況表示
ERR := &null # 辞書参照エラーフラッグリセット
Llresult := [] # 辞書検索結果格納 list
every (ss := !Lword) & /ERR do { # 細分文字を取り出して、
# ↑既に辞書参照エラーが発生していなければ、
# 細分文字が辞書に存在するかチェック
if member(T_dic,ss) then put(Llresult,T_dic[ss]) # 結果データ格納
else ERR := "ERR" # 参照エラーフラッグセット
}
# 細分文字列が全て辞書にあれば、書き出し
if /ERR then { # エラーフラッグが立っていなければ
n_find +:= 1 # カウンタ+1
writes(&errout,"!") # 合致表示
writes(s_word) #
if *s_wild >= 1 then writes(" + ",s_wild)
writes(" ->") #
nn := 0 # 細分文字群カウンタ
every Lstr := !Llresult do { # 細分文字群を取り出して
nn +:= 1 # カウンタ+1
if nn > 1 then writes(" +") # 先頭でなければ、区切りマーク
every writes(" ",!Lstr) # 文字群を書き出し
}
write()
}
}
}
}
write(&errout)
write(n_comb," 通りの組合せのうち、",n_find," 通りが辞書にありました。",
" 終了:",&clock)
end
####################
# 分配の組合せ
####################
# arg [1]: string 分配する英文字列:分配パターンのトータルに合ってること。
# [2]: list 分配パターン(降順の list)
# [3]: string 前の文字列(同一文字数指定の場合に降順のものだけ選ぶための)
# value : list 分割された文字列( listに格納)
# Usage : every LL := expcomb(s,L) do ..
# ("abc", [2,1]) -> ["ab","c"], ["ac","b"], ["bc","a"]
# ("abcd",[2,2]) -> ["ab","cd"],["ac","bd"],["ad","bc"]
procedure expcomb(s,L,s_ref)
/s_ref := "" # 指定なければ、空文字
s := csort(s) # 文字列ソート
if *L = 1 then { # パターン要素の最後で、
if L[1] = *s_ref then { # 前回と文字数が同じで、
if s << s_ref then return &fail # 辞書順で前なら、失敗させる。
}
return [s] # ↑で、無ければ、文字列を返す。
}
# 1文字の文字列指定ならば、後は、順に1文字ずつ listに入れるだけ
if L[1] = 1 then { # 1文字の文字列指定ならば、
# 後は、順に1文字ずつ listに入れるだけ
return [s[1]] ||| expcomb(s[2:0], L[2:0])
} # ↑先頭文字 ↑残り文字列 ↑残りのリスト
# 2文字以上の文字列指定ならば、
every ss := exscomb(s,L[1]) do { # 文字の組合せを作って
if *ss = *s_ref then { # 前回と文字数が同じで、
if ss << s_ref then return &fail # 辞書順で前なら、失敗させる。
} # ↓参照用文字列
suspend [ss] ||| expcomb(ssub(s,ss),L[2:0],ss)
} # ↑組合せ文字 ↑残り文字列 ↑残りのリスト
end
####################
# 文字列の引き算
####################
# arg [1]: string 被削除文字列
# [2]: string 削除文字列
# value : string 結果文字列
# 文字列 s1の先頭から、文字列 s2の文字を削除。1:1で削除。
# ("abcabc","abd") -> "cabc" s2にある文字で、s1に無い文字は無視される。
procedure ssub(s1,s2)
every c := !s2 do { # s2から1文字ずつ取り出して
ss := "" # 上記文字を削除後の文字列の格納エリア
s1 ? { # s1を走査対象として、
if ss ||:= tab(upto(c)) then { # 文字が見つかれば そこ迄の文字列を
# ssに足し込み
move(1) # 1文字スキップ
ss ||:= tab(0) # 残りの文字列を足し込み
s1 := ss # s1更新
}
}
}
return s1
end
####################
# 文字列の nCm (n = *s) n個文字列から、m文字を選ぶ。 generator
####################
# stringの組み合わせ
# nCm (n = *s) n個のものから、m個を選ぶ。
# arg: [1]: s: string
# [2]: m: integer
# value: string
# Usage: every ss := exscomb(s,m) do ...
# Icon入門講座3(11)scomb()を同一文字指定対応に拡張
procedure exscomb(s,m)
initial {
s := csort(s) # 文字列をソートする。(BIPL:strings.icn)
/m := *s # デフォルト nCn (n = m = *s)
}
if m = 0 then return "" # mを文字数カウンターに使う。
# 0なったら、そこで打ち止め。
suspend s[i := new_pos(s)] || exscomb(s[i+1 : 0], m -1)
#↑ 1文字選ぶ ↑ ↑←前で選んだ文字以降 ↑指定文字数に
# | の文字列に対し同じ 文字列を抑え
# | 処理を行う。 るためのカウ
# 文字列の連結 ンター
end
####################
# ソートされた文字列 sの左はじから、順に文字位置を出力する generator。
####################
# 手前の文字と同一ならスキップする。
# arg [1]: s string
# value: integer
# Usage: every i := new_pos(s) do ...
procedure new_pos(s)
ss := "" # 手前の文字を記憶しておく変数
every i := 1 to *s do {
if ss ~== s[i] then { # 手前の文字と違っていたら
ss := s[i] # 手前文字を更新
suspend i # i を返す。
}
}
end
#############################
# 文字列から重複して、n個、降順のものを取り出す generator
#############################
# arg [1]: string
# [2]: integer
# value : string
# Usage : every ss := mscombd(s,n) do ..
# ("abc",2) -> "aa","ab","ac","bb","bc","cc"
procedure mscombd(s,n)
if n =0 then return "" # 再帰終了
every i := 1 to *s do { # 1~文字列長まで
# ↓ i番目の文字を取り出して
suspend s[i] || mscombd(s[i:0],n-1)
} # ↑それ以降の文字と組み合わせる
end
####################
# 正整数分割 generator
####################
# 5=3+2 等に数字分割する。この procedureは n_divdを呼びフィルターを掛けている。
# 分割パターンが多すぎる時に、制限をかけるために使用。
# arg [1]: 分割する元の数
# [2]: 最大分割数
# [3]: 最小数
# value : list
procedure n_divdf(r,ndiv,nmin)
every L := n_divd(r) do { # r の分割結果を取り出し
if *L <= ndiv then { # 分割数チェック(listのサイズチェック)
if L[*L] >= nmin then suspend L # 最小数チェック(降順に入っているので
} # 末尾の要素をチェック)
}
end
####################
# 正整数分割 generator
####################
# 5=3+2 等に分割する。分割は降順のみ許す。(例 5=2+3は除外)
# arg [1]: 分割される元の数(再帰の場合は、前の処理の余り)
# [2]: 最大数 (5=2+2+1 の場合に、最初の 2の時 3が余るが、再帰して 3の
# 分割を始める時、3からではなく 2から始めるための細工。降順手当。)
# value : 分解結果の数。listに格納
# Usage : every L := n_divd(r) do ...
procedure n_divd(r,max)
/max := r # 指定無きは、分割される元の数そのもの
if r < 1 then fail # 念のため
if r = 1 then return [1] # 再帰終了
# r >= 2 の場合
if r > max then rs := max # 分割(取り去る)数の最大数の設定。
else rs := r # 分割される数か 最大数指定の 小さい方
every i := rs to 1 by -1 do { # 上記指定数~1迄、順に-1しながら
rr := r -i # 新たな余り
if rr = 0 then suspend [i] # 余りが無ければ
# 余りがあれば、再帰処理
else if rr > i then suspend [i] ||| n_divd(rr,i) # 余りが大き過ぎる時
else suspend [i] ||| n_divd(rr)
}
end
# BIPL(Icon基本ライブラリー)より
####################
# strings.icnに含まれる 文字のソート procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ローカル変数宣言(無くても良い)
s1 := "" # 初期値クリア
every c := !cset(s) do # 引数を cset(文字集合)へ変換し順に取り出す。
every find(c, s) do # 取り出した文字で、引数文字列を検索し、
s1 ||:= c # 見つかる度に、文字を s1に足し込む。
return s1
end
# csetから !で要素を取り出す時には、アルファベット順に取り出せる。
####################
# strings.icnに含まれる 文字の削除 procedure
####################
procedure deletec(s, c) #: delete characters
local result # ローカル宣言(無くても良い)
result := "" # 削除後の文字列格納エリア
s ? { # sを走査対象として、
while result ||:= tab(upto(c)) do # cが見つかる迄の文字列を足し込んで
tab(many(c)) # c以外の文字までスキップ
return result ||:= tab(0) # 余りの文字を足し込む
}
end
-----$ DICREFP5.ICN ( lines:290 words:1124 ) ---------------<cut here
(追記 コメントの 「ワイルドカード未対応」は、削除漏れです。ワイルドカードに対応しています。)
曖昧検索指定が無い場合の例をを1つ。dicrefp5 heavyrain 2 4 >kkk としますと、次のようになります。
-----^ KKK ( date:03-08-25 time:20:56 ) --------------------<cut here
5文字用辞書 e05 を読込中です。開始:20:56:50 終了:20:56:50 12483語ありました。
4文字用辞書 e04 を読込中です。開始:20:56:50 終了:20:56:51 5881語ありました。
9文字用辞書 e09 を読込中です。開始:20:56:51 終了:20:56:55 38640語ありました。
heavyrain を、最大分割数 2、最小文字長 4 にて分割してチェック。開始:20:56:55
heavyrain -> rayah + nevi vein vine
heavyrain -> Aryan + hive
heavyrain -> hiera + navy Navy
heavyrain -> haven + airy Iyar
heavyrain -> hyena + riva vair
heavyrain -> haver + ayin
heavyrain -> hayer + vain vina
heavyrain -> heavy Yahve + airn Arni Iran rain rani
heavyrain -> raven + hiya Yahi
heavyrain -> hairy + Evan nave vane vena
heavyrain -> Invar invar ravin Vanir + yeah
heavyrain -> rainy + have
heavyrain -> hiver + Yana
heavyrain -> nervi riven viner + ayah
heavyrain -> veiny + haar
92 通りの組合せのうち、15 通りが辞書にありました。 終了:20:56:55
-----$ KKK ( lines:21 words:119 ) --------------------------<cut here
さて不明文字が2つあるケースだと、dicrefp5 a.ahviy.r 2 4 >lll としますと、こんな結果になります。
-----^ LLL ( date:03-08-25 time:20:59 ) --------------------<cut here
5文字用辞書 e05 を読込中です。開始:20:59:10 終了:20:59:10 12483語ありました。
4文字用辞書 e04 を読込中です。開始:20:59:10 終了:20:59:11 5881語ありました。
9文字用辞書 e09 を読込中です。開始:20:59:11 終了:20:59:15 38640語ありました。
a.ahviy.r を、最大分割数 2、最小文字長 4 にて分割してチェック。開始:20:59:15
aahviyr + aa -> Avahi + raya
aahviyr + aa -> varia + ayah
aahviyr + ab -> Bahai + vary
aahviyr + ab -> brava + hiya Yahi
aahviyr + ab -> Avahi + bray Brya
(中略)
aahviyr + en -> hayer + vain vina
aahviyr + en -> heavy Yahve + airn Arni Iran rain rani
aahviyr + en -> raven + hiya Yahi
aahviyr + en -> hairy + Evan nave vane vena
aahviyr + en -> Invar invar ravin Vanir + yeah
(中略)
aahviyr + uy -> hairy + Vayu
aahviyr + vx -> hyrax + viva
aahviyr + wy -> hairy + wavy
aahviyr + xx -> rayah + xxiv XXIV xxvi XXVI
aahviyr + xz -> varix + hazy
27602 通りの組合せのうち、943 通りが辞書にありました。 終了:20:59:20
-----$ LLL ( lines:949 words:7467 ) ------------------------<cut here
結構、合致するものがありますので、途中を略してあります。943件だと結果のチェックに時間がかかりそうです。
ちょっと長引きましたが、ちょうど10回目ということで、Iconミニ講座は、終わりにします。(宣言しておかないと、すぐまた続けそうなので。笑)長文におつき合い頂きまして、有り難うございます。
風つかい(hshinoh@mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: Hello It's Me / Lani Hall
(2003/08/25 TSfreeA.txt)
[Icon] Icon入門講座6 Iconミニ講座 おまけ(プログラムの整理)
風つかいさんのIcon講座。
- [Icon] Icon入門講座6 Iconミニ講座 [7/9/2006 (Sun.)]
- [Icon] Icon入門講座6 Iconミニ講座1(辞書読込)
- [Icon] Icon入門講座6 Iconミニ講座2(組合せ文字列の辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座3(正整数の分割)
- [Icon] Icon入門講座6 Iconミニ講座4(フィルター)
- [Icon] Icon入門講座6 Iconミニ講座5(文字列分解・辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座6(辞書参照の別方式)
- [Icon] Icon入門講座6 Iconミニ講座7(曖昧参照)
- [Icon] Icon入門講座6 Iconミニ講座8(辞書分割)
- [Icon] Icon入門講座6 Iconミニ講座9(分配組合せ)
- [Icon] Icon入門講座6 Iconミニ講座10(分割文字で辞書参照)
■ TSfree > Iconミニ講座 おまけ(プログラムの整理) 風つかい
何かのプログラムを作っても、しばらく経つと、作った自分でも、「一体何のためのプログラムだっけ?」とか「一体何のためにこういう処理にしてるんだろう?」と悩むことが沢山あります。私のハードディスクには、そんな正体不明のプログラムがあふれています。
今後も使えそうな procedureはライブラリーにして、独立プログラムはコメントを充実して保管したい。とは、思っていますが、なかなかできないですね。
今回は、少しやっておこうと思います。また、少し Iconの特徴を生かしていない部分がありますので、書き直してみました。
<書き直し1>
if member(T_dic,s_word) # 辞書テーブルにあるかチェック
then put(T_dic[s_word], word) # あれば、その listに追加
else T_dic[s_word] := [word] # 無ければ、listに入れて登録
という部分があります。
辞書 tableには、例えば key:"abc" に対応した 値として、ソートして小文字化すると"abc"となる単語を登録します。
そういう単語は複数ある可能性がありますので、key:"abc"に対応する 値は listとして、その中に 順次追加していきます。
<1>最初 値に "ABC"を追加 key:"abc" -> ["ABC"] としたい。
・・・key:"abc"が無い状態から追加
<2>次は 値に "BcA"を追加 key:"abc" -> ["ABC","BcA"] としたい。
・・・既に key:"abc"に対応する要素 "ABC"があって更に "BcA"を追加
<1>の状態(key:"abc"が無い状態)で、key:"abc"の値に listがあるつもりで<2gt;と同じやり方で、単語を追加しようと listへの追加処理をすると、該当する keyが無いということで、エラーが発生します。
put(T_dic[s_word],word) は、エラーが発生。
(ランタイムエラー:存在しない値(&null)にアクセスしようとした。)
(補足:listの追加処理で、追加先の listが無いというエラーも発生する条件だが、
tableの keyが無いというエラーが先だと思います。)
<2>の状態なら key:"abc"は存在して、値には list ["ABC"]が存在していますので、
このlistへの追加処理で単語が追加できます。
put(T_dic[s_word],word) で、単語が追加できる。
<1>の状態(key:"abc"が無い状態)で値に単語を追加する場合は、
T_dic["abc"] := ["ABC"]で、 key:"abc"の値に要素数1の listをセット
しなければいけません。
この<1>と<2>処理の違いを if..then..else..で分けています。
さて、(key:"abc"が無い状態)をチェックするには、member(T_dic,"abc")でできますが、実際に key:"abc"で tableにアクセス(T_dic["abc"])してエラーが発生するかどうかでもチェックできます。
でも、ランタイムエラーが発生するとプログラムが止まってしまいます。それでは困るので、Iconには、存在しない(&null)かどうかを判定する仕掛けがあります。
\T_dic["abc"] は、存在すれば key:"abc"に対応する T_dicの値を、存在しなければ、&fail(エラー状態)となり、ランタイムエラーにはなりません。
そこで、if member(T_dic,s_word) は、if \T_dic[s_word] とできますので、
if \T_dic[s_word] # 辞書テーブルにあるかチェック
then put(T_dic[s_word], word) # あれば、その listに追加
else T_dic[s_word] := [word] # 無ければ、listに入れて登録
と、書き直せます。
key:"abc"が無い状態では、put(T_dic["abc"],word)は、ランタイムエラーを発生しますが、put(\T_dic[["abc"],word)は、ランタイムエラーを発生せず failして、値は、&failとなります。
そこで、更に、if .. then .. else ..式を、
put(\T_dic[s_word],word) | (T_dic[s_word] := [word])
と、1行にできます。 "|"の左辺が failした場合は、右辺の式が生きて、(T_dic[s_word] := [word])を実行する動作となり、if .. then .. else .. と同等の動作となります。
<書き直し2>
ERR := &null # 辞書参照エラーフラッグリセット
Llresult := [] # 辞書検索結果格納 list
every (ss := !Lword) & /ERR do { # 細分文字を取り出して、
# ↑既に辞書参照エラーが発生していなければ、
# 細分文字が辞書に存在するかチェック
if member(T_dic,ss) then put(Llresult,T_dic[ss]) # 結果データ格納
else ERR := "ERR" # 参照エラーフラッグセット
}
ここは、分解した文字列の各々が辞書に存在するかのチェックをしています。ERR というフラッグを立てているのが、美しくありません。これは、辞書 table参照用の別 procedureを作ると、
Llresult := tbl_ref(T_dic,Lword) | &null
# 分配文字列が全て辞書にあれば 辞書参照結果をセット。
# いずれかが辞書になければ、&nullでクリア。
と、一行にできます。このように、Iconでは "|"を使うと、表記がコンパクトになる場合があります。
<書き直しその他>
共通的な procedureは、別ファイルにして、メインファイルから linkするようにしてみました。 また変数名は若干変更してあります。 procedure名も1つ統一が取れてなかったので修正しました。
link指定は、私のライブラリ区分に従っていましたが、お試しになる場合を考えて元のファイルから必要な部分だけ抜粋したファイルを作成し、それを linkしてあります。ライブラリを、icont -c foo.icn と、予めコンパイルして、中間コード化しておき、その後に、icont decrefp6.icn と、すれば実行ファイルが作成できます。
-----^ DICREFP6.ICN ( date:03-08-29 time:23:15 ) -----------<cut here
####################
# クロスワードパズル支援
####################
# dicrefp6.icn Rev.1.1 2003/08/29 windy 風つかい H.S.
####################
# クロスワードパズル支援
# ・英文字のクロスワードパズルをまず解いて、その後指定の升目の文字を
# 組み合わせて最終的な単語を見つける。
# ・一部判っていない升目がある。
# ・辞書ファイルを参照。英語の単語がズラッと並んだ形式の辞書ファイル。
# ・例: 判らない文字を .で表すと、a.ahviy.r となる。
# この場合の正解(例)は、heavy rain という2つの単語の組合せ。
# 補足
# ・コマンドライン引数から、文字列を生成して、辞書を参照し、辞書にあれば出力。
# 不明文字のための曖昧検索。単語組合せのため文字列分割。
# ・辞書参照時間短縮のため、辞書を読み込む時に、単語を文字ソート・小文字変換
# した keyをつけて、tableに格納。 この tableを参照。
# ・辞書読込時間短縮のため、文字数毎に分割された辞書ファイルから必要な字数の
# ファイルのみを読込む。
# 元の辞書(english.dic)は、スペルチェック用の英単語が順に並んだもの。
# このプログラムのテストでは、DD SOFT SoundMixSpellコンポーネント
# Ver 0.3.0 に 同梱の辞書ファイルを使用。
# ・辞書は、予め文字数毎に、e01,e02,...等に分割しておく。(別プログラム)
# ・TS Network TSabc,TSfree関連
# 履歴
# dicrefp5.icnを修正。サブ procedureを link形式にした。
# 条件式 変数名 を見直し。訂正: mscombd -> mscomb procedure名の付与ミス
# This file is in the public domain.
link file_x, # ファイル関係 f_name: 実行ファイル名取得
string_x, # 文字列関係 mscomb: 英文字列重複組合せ
# expcomb: 英文字列分配組合せ
number_x, # 数字関係 ndivdf: 正整数の部分和(降順 分割数・最小制限)
stringsx # 文字列関係(Icon基本ライブラリ BIPLに含まれるもの)
# deletec: 英文字列から文字を削除
# csort: 英文字列の辞書順ソート
procedure main(args)
# コマンドライン引数チェック。無ければ Usage表示
Usage := " 英単語(.はワイルドカード) 最大分割数 最短文字長"
if *args < 1 then stop(f_name(),Usage)
c_word := args[1] # コマンドラインの英文字列
# ↓左辺の式が失敗すれば、右辺の式を選ぶ
ndiv := \args[2] | 1 # 分割数指定無しは、1(分割せず)
nmin := \args[3] | *c_word # 最小文字長指定無しは、引数文字列長
# コマンドライン引数から、分割パターンを生成
L_lpat := [] # 文字列分割パターン格納 list
every put(L_lpat,n_divdf(*c_word,ndiv,nmin)) # 分割パターン格納
# L_lpat例:[[6],[3,3]]
# 必要な文字数の生成( setに入れて、ダブリを削除)
S_pat := set() # 文字数格納 set(指定文字数ため)
every L := !L_lpat do every insert(S_pat,!L) # 文字数を全て 格納
# S_pat例: (6,3)
T_dic := table() # 辞書格納 table生成
every n_pat := !S_pat do {
# 辞書ファイル名生成
# ↓rightは、右寄せ桁合わせ関数
dic := "e" || right(n_pat,2,"0") # 辞書ファイル名 例:"e06","e03"
# 辞書ファイルオープン
dir := open(dic) | stop(" ",n_pat,"文字用の辞書が見つかりません。")
writes(" ",n_pat,"文字用辞書 ",dic," を読込中です。開始:",&clock)
# 辞書読込
n_line := 0 # 辞書行数カウンタ
# 辞書を1行ずつ読み込んで、
while word := read(dir) do {
n_line +:= 1 # 辞書行数+1
if n_line % 1000 = 0 then writes(&errout,"*") # 読み込み状況表示
# 単語を小文字変換しソートしたものを keyにして格納。
# 同一文字を含む単語は同じ keyに対応する valueに listの形式で格納。
# tableの key生成
# ↓文字列ソート
s_word := csort(map(word)) # 小文字へ変換しソート
# ↑小文字変換 例: "ACb" -> "abc"
# 辞書 tableへ格納
put(\T_dic[s_word],word) | (T_dic[s_word] := [word])
# 格納例: key:"abc" -> value: ["ACb","Bca","cab"]
} # end of while word ..
close(dir) # 辞書ファイルクローズ
write(&errout)
write(" 終了:",&clock," ",n_line,"語ありました。")
} # end of every n_pat ..
write("\n",c_word," を、最大分割数 ",ndiv,"、最小文字長 ",nmin,
" にて分割してチェック。開始:",&clock)
# 辞書参照
n_comb := 0 # 組合せ数カウンタ
n_find := 0 # 辞書にある件数カウンタ
s_word := deletec(c_word,'.') # コマンドライン文字列から '.'を削除
n_dot := *c_word -*s_word # '.'の数
# ワイルドカード文字生成 ↓&lcaseは英小文字 ↓例: a-z,aa-zz,aaa-zzz
every s_wild := mscomb(&lcase,n_dot) do { # ワイルドカード文字を、
s_check := s_wild || map(s_word) # コマンドライン引数の "."以外に足し、
# 分配文字数パターン取り出し
every Lpat:= !L_lpat do { # Lpat例: [6]とか、[3,3]とか
# 文字列分割結果取り出し Lword例: ["sunday"]とか,["day","sun"]とか
every Lword := expcomb(s_check,Lpat) do { # 分配文字列を順次取り出して、
n_comb +:= 1 # チェック回数カウンタ+1
if n_comb % 1000 = 0 then writes(&errout,"*") # チェック状況表示
# 辞書参照して、分配結果が全て辞書にあれば、L_loutにセット
L_lout := tbl_ref(T_dic,Lword) | &null # 分配文字列が全て辞書にあれば、
# 辞書参照結果をセット。いずれかが辞書になければ、&nullでクリア。
# L_lout例: [["Day"],["day"],["Sun","sun","nus"]]
# 分配文字列が全て辞書にあれば、書き出し
if \L_lout then { # L_outに値がセットされていれば
n_find +:= 1 # カウンタ+1
writes(&errout,"!") # 合致表示
# "."を除く元の文字書き出し
writes(s_word) #
if *s_wild >= 1 then writes(" + ",s_wild) # ワイルドカード文字
writes(" ->") #
# 辞書検索結果(2重 list)の書き出し
every Lout := L_lout[i := 1 to *L_lout] do {
# 参照結果を取り出して
if i > 1 then writes(" +") # 先頭でなければ、区切りマーク
every writes(" ",!Lout) # 参照結果を書き出し
} # end of Lout ..
write()
} # end of if \L_lout ..
} # end of every Lword ..
} # end of every Lpat ..
} # end of s_word ..
write(&errout)
write(n_comb," 通りの組合せのうち、",n_find," 通りが辞書にありました。",
" 終了:",&clock)
end
###################
# Tableを list要素で参照し、結果を list連結
###################
# arg [1]: table key: "abc" -> value: "ABC"
# [2]: list 参照する要素の list 例:["abc","def",...]
# value : list table参照結果を格納 例:["ABC","DEF",...]
# Usage : L := tbl_ref(T,L)
# listの 要素のいずれかが tableに存在しなければ、fail
procedure tbl_ref(T,L) #
L1 := []
# ↓ Lの全ての要素につき
every x := !L do put(L1,\T[x]) | fail # 参照 tableになければ failさせる。
return L1
end
# 条件が全て揃った場合だけ結果を返す(いずれかの条件が成立しなかった場合は、
# 全体を failさせる。)には、その部分を サブ procedureにすること。
-----$ DICREFP6.ICN ( lines:151 words:589 ) ----------------<cut here
tbl_ref()は、今回作りましたので、この dicrefp6.icnに入れてありますが、汎用的な procedureですので、共通ライブラリに移す予定です。
ちょっと長いですが、ライブラリから抜粋したファイルを付けます。
-----^ FILE_X.ICN ( date:03-08-29 time:23:17 ) -------------<cut here
####################
# file操作関係 procedure
####################
# file_x.icn Rev.1.1 2003/08/29 windy 風つかい H.S.
# file_e.icn から抜粋。
# This file is in the public domain.
link string_x # top_get,top_cut
# f_name(file_name) # 拡張子を除くファイル名生成(小文字)
# F_name(file_name) # 拡張子を除くファイル名生成(大文字)
####################
# 拡張子を除くファイル名を生成
####################
# Usageの file名訂正漏れを 防ぐための作成
# f_name(),F_name() 1997/12/27 windy 大文字、小文字対応に分ける。
# f_name() 1997/08/15 windy exe_name() -> f_name()
# exe_name() 1997/06/02 windy 風つかい H.S.
# args : ファイル名
# value: string
# Icon入門講座4 Icon回り道(4)
procedure f_name(file_name)
/file_name := &progname # defaultは、実行ファイル名
return map(top_get('.',top_cut('\\',file_name)))
end
procedure F_name(file_name)
/file_name := &progname # defaultは、実行ファイル名
return map(top_get('.',top_cut('\\',file_name)),&lcase,&ucase)
end
-----$ FILE_X.ICN ( lines:31 words:91 ) --------------------<cut here
-----^ NUMBER_X.ICN ( date:03-08-29 time:22:49 ) -----------<cut here
####################
# 数字関係補助 procedure
####################
# number_x.icn Rev1.1 2003/08/29 windy 風つかい H.S.
# number_e.icnから抜粋
# This file is in the public domein.
# n_divd(r,max) # 正整数の分割(降順のみ) genarator
# n_divdf(r,ndiv,nmin) # 正整数の分割(降順、分割数・最小数制限)generator
####################
# 正整数分割 generator(降順のみ)
####################
# 5=3+2 等に分割する。分割は降順のみ許す。(例 5=2+3は除外)
# arg [1]: 分割される元の数(再帰の場合は、前の処理の余り)
# [2]: 最大数 (5=2+2+1 の場合に、最初の 2の時 3が余るが、再帰して 3の
# 分割を始める時、3からではなく 2から始めるための細工。降順手当。)
# value : 分解結果の数。listに格納
# Usage : every L := n_divd(r) do ...
# Iconミニ講座3
# (4) -> [4],[3,1],[2,2],[2,1,1],[1,1,1,1]
procedure n_divd(r,max)
/max := r # 指定無きは、分割される元の数そのもの
if r < 1 then fail # 念のため
if r = 1 then return [1] # 再帰終了
# r >= 2 の場合
if r > max then rs := max # 分割(取り去る)数の最大数の設定。
else rs := r # 分割される数か 最大数指定の 小さい方
every i := rs to 1 by -1 do { # 上記指定数~1迄、順に-1しながら
rr := r -i # 新たな余り
if rr = 0 then suspend [i] # 余りが無ければ
# 余りがあれば、再帰処理
else if rr > i then suspend [i] ||| n_divd(rr,i) # 余りが大き過ぎる時
else suspend [i] ||| n_divd(rr)
}
end
####################
# 正整数分割 generator(フィルター)
####################
# 5=3+2 等に数字分割する。この procedureは n_divdを呼びフィルターを掛けている。
# 分割パターンが多すぎる時に、制限をかけるために使用。
# arg [1]: 分割する元の数
# [2]: 最大分割数
# [3]: 最小数
# value : list
# Usage : every L := n_divdf(r,ndiv,nmin) do ..
# Iconミニ講座4
# (4,2,2) -> [4],[2,2]
procedure n_divdf(r,ndiv,nmin)
every L := n_divd(r) do { # r の分割結果を取り出し
if *L <= ndiv then { # 分割数チェック(listのサイズチェック)
if L[*L] >= nmin then suspend L # 最小数チェック(降順に入っているので
} # 末尾の要素をチェック)
}
end
-----$ NUMBER_X.ICN ( lines:60 words:243 ) -----------------<cut here
-----^ STRING_X.ICN ( date:03-08-29 time:23:18 ) -----------<cut here
####################
# 文字列操作 procedure
####################
# string_x.icn Rev.1.1 2003/09/29 windy 風つかい H.S.
# string_e.icn から抜粋
# This file is in the public domain.
link stringsx # BIPL csort
# ssub(s1,s2) # 文字列の引き算
# top_cut(c,s) # 先頭削除(最長一致削除)
# top_get(c,s) # 先頭切り出し(最短一致切り出し)
# 組合せ関係
# exscomb(s,m) # 文字の組合せ生成(同一文字対応) generator
# mscomb(s,m) # 文字の組合せ生成 nHm(重複取り出し) genarator
# 順列・組合せ共通
# new_pos(s) # 文字位置生成 (同一文字対応用) generator
# 組合せ分配
# pcomb(s,L) # 文字の組合せを 分配 generator
# expcomb(s,L,s_ref) # 文字の組合せを 分配(同一文字 同一数)generator
####################
# 文字列の引き算
####################
# arg [1]: string 被削除文字列
# [2]: string 削除文字列
# value : string 結果文字列
# 文字列 s1の先頭から、文字列 s2の文字を削除。1:1で削除。
# ("abcabc","abd") -> "cabc" s2にある文字で、s1に無い文字は無視される。
# Iconミニ講座9
procedure ssub(s1,s2)
every c := !s2 do { # s2から1文字ずつ取り出して
ss := "" # 上記文字を削除後の文字列の格納エリア
s1 ? { # s1を走査対象として、
if ss ||:= tab(upto(c)) then { # 文字が見つかれば そこ迄の文字列を
# ssに足し込み
move(1) # 1文字スキップ
ss ||:= tab(0) # 残りの文字列を足し込み
s1 := ss # s1更新
}
}
}
return s1
end
####################
# 文字列の 先頭から特定文字までの部分 を取り去る。最長部分を取り去る。
####################
# arg : cset
# value : string
# Usage : top_cut(c,s)
# Icon入門講座2(5)
procedure top_cut(c,s)
/s := &subject # sの指定がなければ &subject
/c := ' \t' # cの指定がなければ spaceか tab
s ? { # sを走査対象とする。
while tab(upto(c)) do tab(many(c)) # cが見つかる限り、走査位置を
# その文字の後に移動。
return tab(0) # 残りの文字列を返す。
}
end
####################
# 文字列の 先頭から特定文字までの部分 を得る。最短部分を得る。
####################
# arg : cset
# value : string
# Usage : top_get(c,s)
# Icon入門講座2(5)
procedure top_get(c,s)
/s := &subject # sの指定がなければ &subject
/c := ' \t' # cの指定がなければ spaceか tab
s ? { # sを走査対象とする。
return tab(upto(c) | 0) # cまで走査位置を移動しその間の
} # 文字列を返す。cがみつからなけ
# れば、末尾まで返す。
end
####################
# 組合せ関係
####################
####################
# 文字列の組合せ 同一文字指定を許す n文字列から m個を選ぶ組合せ generator
####################
# stringの組み合わせ
# n個から、m個を選ぶ。(同一文字指定対応)
# arg: [1]: s: string
# [2]: m: integer
# value: string
# Usage: every ss := exscomb(s,m) do ...
# Icon入門講座3(11)scomb()を同一文字指定対応に拡張。 Iconミニ講座9
# ("abca",3) -> "aab","aac","abc"
procedure exscomb(s,m)
initial {
/m := *s # デフォルト nCn (n = m = *s)
s := csort(s) # 文字列をソートする。(BIPL:strings.icn)
}
if m = 0 then return "" # mを文字数カウンターに使う。
# 0にになったら、再帰終了。
suspend s[i := new_pos(s)] || exscomb(s[i+1 : 0], m -1)
#↑ 1文字選ぶ ↑ ↑←前で選んだ文字以降 ↑指定文字数に
# | の文字列に対し同じ 文字列を抑え
# | 処理を行う。 るためのカウ
# 文字列の連結 ンター
end
#############################
# 文字列の nHm n文字列から、重複して m個を選ぶ組合せ generator
#############################
# n個から 重複して、m個を選ぶ。
# arg [1]: string
# [2]: integer
# value : string
# Usage : every ss := mscomb(s,m) do ..
# ("abc",2) -> "aa","ab","ac","bb","bc","cc"
procedure mscomb(s,m)
initial {
/m := *s
}
if m =0 then return "" # 再帰終了
every i := 1 to *s do { # 1~文字列長まで
# ↓ i番目の文字を取り出して
suspend s[i] || mscomb(s[i:0],m-1)
} # ↑その文字以降の文字と組み合わせる。
end
####################
# 順列・組合せ共通
####################
####################
# ソートされた英文字列 sの左はじから、順に文字位置を出力する generator。
####################
# 手前の文字と同一ならスキップする。
# arg [1]: s string
# value: integer
# Usage: every i := new_pos(s) do ...
procedure new_pos(s)
ss := "" # 手前の文字を記憶しておく変数
every i := 1 to *s do {
if ss ~== s[i] then { # 手前の文字と違っていたら
ss := s[i] # 手前文字を更新
suspend i # i を返す。
}
}
end
####################
# 分配の組合せ(同一文字指定・同一文字数指定対応)
####################
# arg [1]: string 分配する英文字列:分配パターンのトータルに合ってること。
# [2]: list 分配パターン(降順の list)
# [3]: string 前の文字列(同一文字数指定の場合に降順を選ぶための参照用)
# value : list 分割された文字列(降順の組合せのみ)( listに格納)
# Usage : every LL := expcomb(s,L) do ..
# ("abc", [2,1]) -> ["ab","c"], ["ac","b"], ["bc","a"]
# ("abcd",[2,2]) -> ["ab","cd"],["ac","bd"],["ad","bc"]
# 分配パターン生成に、number_e.icnの n_div(),n_divd(),n_divdf()が使えるかも。
# Iconミニ講座9
procedure expcomb(s,L,s_ref)
/s_ref := "" # 指定なければ、空文字
s := csort(s) # 文字列ソート
if *L = 1 then { # パターン要素の最後で、
if L[1] = *s_ref then { # 前回と文字数が同じで、
if s << s_ref then return &fail # 辞書順で前なら、失敗させる。
}
return [s] # ↑で、無ければ、文字列を返す。
} # いずれににしても、再帰終了。
# 1文字の文字列指定ならば、後は、順に1文字ずつ listに入れるだけ
if L[1] = 1 then { # 1文字の文字列指定ならば、
# 後は、順に1文字ずつ listに入れるだけ
return [s[1]] ||| expcomb(s[2:0], L[2:0])
} # ↑先頭文字 ↑残り文字列 ↑残りのリスト
# 2文字以上の文字列指定ならば、
every ss := exscomb(s,L[1]) do { # 文字の組合せを作って
if *ss = *s_ref then { # 前回と文字数が同じなら、
if ss << s_ref then return &fail # 降順で無ければ、失敗させる。
} # ↓参照用文字列
suspend [ss] ||| expcomb(ssub(s,ss),L[2:0],ss)
} # ↑組合せ文字 ↑残り文字列 ↑残りのリスト
end
-----$ STRING_X.ICN ( lines:198 words:657 ) ----------------<cut here
-----^ STRINGSX.ICN ( date:03-08-29 time:23:13 ) -----------<cut here
####################
# 文字列操作 procedure BIPL(Icon基本ライブラリー)より
####################
# stringsx.icn Rev.1.1 2003/08/29 windy 風つかい H.S.
# BIPL strings.icn から抜粋
# This file is in the public domain.
####################
# strings.icnに含まれる 文字のソート procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ローカル変数宣言(無くても良い)
s1 := "" # 初期値クリア
every c := !cset(s) do # 引数を cset(文字集合)へ変換し順に取り出す。
every find(c, s) do # 取り出した文字で、引数文字列を検索し、
s1 ||:= c # 見つかる度に、文字を s1に足し込む。
return s1
end
# csetから !で要素を取り出す時には、アルファベット順に取り出せる。
####################
# strings.icnに含まれる 文字の削除 procedure
####################
procedure deletec(s, c) #: delete characters
local result # ローカル宣言(無くても良い)
result := "" # 削除後の文字列格納エリア
s ? { # sを走査対象として、
while result ||:= tab(upto(c)) do # cが見つかる迄の文字列を足し込んで
tab(many(c)) # c以外の文字までスキップ
return result ||:= tab(0) # 余りの文字を足し込む
}
end
-----$ STRINGSX.ICN ( lines:32 words:117 ) -----------------<cut here
風つかい(hshinoh@mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: Yesterday's Dream / 山見慶子
(2003/08/30 TSfreeB.txt)
[Icon] Icon入門講座6 Iconミニ講座 あまり(procedure構成)
風つかいさんのIcon講座。
- [Icon] Icon入門講座6 Iconミニ講座 [7/9/2006 (Sun.)]
- [Icon] Icon入門講座6 Iconミニ講座1(辞書読込)
- [Icon] Icon入門講座6 Iconミニ講座2(組合せ文字列の辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座3(正整数の分割)
- [Icon] Icon入門講座6 Iconミニ講座4(フィルター)
- [Icon] Icon入門講座6 Iconミニ講座5(文字列分解・辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座6(辞書参照の別方式)
- [Icon] Icon入門講座6 Iconミニ講座7(曖昧参照)
- [Icon] Icon入門講座6 Iconミニ講座8(辞書分割)
- [Icon] Icon入門講座6 Iconミニ講座9(分配組合せ)
- [Icon] Icon入門講座6 Iconミニ講座10(分割文字で辞書参照)
- [Icon] Icon入門講座6 Iconミニ講座 おまけ(プログラムの整理)
■ TSfree > Iconミニ講座 あまり(procedure構成) 風つかい
ライブラリ整理の際、ちょっと遊んでみましたので、ご参考に。テーブルをリストの要素で参照する procedureの3つの例です。
-----^ PROC01.ICN ( date:03-08-29 time:23:38 ) -------------<cut here
####################
# テーブル参照プログラム例
####################
# proc01.icn Rev.1.1 2003/08/29 windy 風つかい H.S.
# TS Network TSfree
# This file is in the public domain.
procedure main()
T := table() # table生成
T["a"] := "AA" ; T["b"] := "BB" ; T["c"] := "CC" # データ登録
# ↓データ1 # ↓データ2
L := [["a","b","c"],["a","d","c"]] # テストデータ
# procedure のテスト procedureを引数にして、procedureを呼ぶ。
test(tbl_ref1,T,L)
test(tbl_ref2,T,L)
test(tbl_ref3,T,L)
end
# procedureのテスト
# arg [1]: procedure
# [2]: table テスト用 table
# [3]: list テスト用 list
procedure test(prcdr,T,L)
write(image(prcdr)) # procedure名
every L1 := !L do { # テスト用 listからデータを取り出して
every writes(" ",!L1) # 書き出し
writes(" -> ")
L2 := prcdr(T,L1) | ["error"] # 処理結果
every writes(" ",!L2) # 処理結果書き出し
write()
}
write("----- ----- -----") # 仕切線
end
###################
# Table参照し、結果を list連結
###################
# arg [1]: table key -> value
# [2]: list 参照する要素の list 例:["abc","def",...]
# value : list table参照結果を格納 例:["ABC","DEF",...]
# Usage : L := tbl_ref(T,L)
# args[2]の 要素のいずれかが tableに存在しなければ、fail
# 条件が全て揃った場合だけ結果を返す(いずれかの条件が成立しなかった場合は、
# 全体を failさせる。)には、その部分を procedureにすること。
# 再帰
procedure tbl_ref1(T,L) # ↓ \xは存在すればその値、なければ fail
return if *L = 1 then [ \T[ L[1] ] ] #←listの最後なら再帰終了
else [ \T[ L[1] ] ] ||| tbl_ref1(T,L[2:0])
end # listの連結 ↑ ↑最後でなければ、再帰
# every
procedure tbl_ref2(T,L) # <- この辺が分かりやすいかな。
L1 := []
every x := !L do put(L1,\T[x]) | fail # いずれか辞書になければ、fail
return L1
end
# whileループ
procedure tbl_ref3(T,L)
L1 := []
while x := get(L) do put(L1,\T[x]) | fail # いずれか辞書になければ、fail
return L1
end
-----$ PROC01.ICN ( lines:65 words:234 ) -------------------<cut here
動かすとこんな風です。
-----^ PROC01 ( date:03-08-29 time:23:38 ) -----------------<cut here
procedure tbl_ref1
a b c -> AA BB CC
a d c -> error
----- ----- -----
procedure tbl_ref2
a b c -> AA BB CC
a d c -> error
----- ----- -----
procedure tbl_ref3
a b c -> AA BB CC
a d c -> error
----- ----- -----
-----$ PROC01 ( lines:12 words:51 ) ------------------------<cut here
風つかい(hshinoh@mb.neweb.ne.jp)
IconのWWWは、 http://www.cs.arizona.edu/icon/
UniconのWWWは、http://unicon.sourceforge.net/index.html
BGM: for Masqurade / 山見慶子
(2003/08/30 TSfreeC.txt)
[jperl] 実践実用Perl - フレームの編集と保存
なんちゃって、あらたまって、少し書いた。前から、ブラウザ上でシステムの変更ができるほうが便利だと思っていたが、書くのも面倒でほったらかし。ようやくちょこちょこっと書いてみた。
frame_edit.cgi : htmlというパラメータにhtmlファイル名を与えると該当ファイルを編集できる。もちろん、mainフレームで編集するように、memolシステムが前提で書いてある。
#!/Perl/bin/MSWin32-x86-object/jperl.exe
require 'cgi-lib.pl';
&ReadParse(*in);
$html = $in{'html'};
$cgidir = $ENV{'CGIDIR'};
$docroot = $ENV{'DOCROOT'};
print <<TOP;
Content-type: text/html
<HTML>
<HEAD>
<TITLE>Frameの編集</TITLE>
<META HTTP-EQUIV="Content-Type" content="text/html; charset=Shift_JIS">
<link rel="stylesheet" type="text/css" href="/mystyle.css">
</HEAD>
<BODY>
<div class="emph">$htmlの編集</div>
TOP
print <<HEADER;
<form method="POST" action="$cgidir/frame_save.cgi/$html" target="main">
<textarea rows=30 cols=80 name="content">
HEADER
# 編集ファイルを読み込む
if(open(IN, "<$docroot/$html")){
while(<IN>){
print;
}
close(IN);
}
# 編集フォーム最終部分を CGI 出力する
print <<FOOTER;
</textarea>
<br>
<input type="submit" value="保存">
<input type="reset" value="リセット">
</form>
</BODY>
</HTML>
FOOTER
frame_save.cgi : 編集結果を保存するためのCGI、textareaの内容を元のファイルに上書き保存する。確認などはないが、失敗した時は戻りボタンで戻れば助かるかも(^^;)確かめる時はバックアップを取っておくこと。
#!/Perl/bin/MSWin32-x86-object/jperl.exe
require 'cgi-lib.pl';
&ReadParse(*in);
$content = $in{'content'};
$cgidir = $ENV{'CGIDIR'};
$docroot = $ENV{'DOCROOT'};
$html = $ENV{'PATH_INFO'};
open(OUT, "> $docroot$html");
print OUT $content;
close(OUT);
print <<HTML;
Content-type: text/html
<HTML>
<HEAD>
<TITLE>Frameの編集保存</TITLE>
<META HTTP-EQUIV="Content-Type" content="text/html; charset=Shift_JIS">
<link rel="stylesheet" type="text/css" href="/mystyle.css">
</HEAD>
<BODY>
<div class="emph">$htmlの保存</div>
<p>$htmlを保存しました。</p>
</BODY>
</HTML>
HTML
もちろん、デスクトップCGIの編集にも応用可能だ。メモを書く部分と同じで、こんな感じで書けばWikiっぽいものも簡単に作れるはずだ。
items.htmlに次のようにCGIへのリンクを書いておく。
<a href="/cgi-bin/awakening/frame_edit.cgi?html=items_ff.html" target="main">Frame編集</a>
ボタンで少し格好を付けるなら、次のように書く。
<FORM action="/cgi-bin/awakening/frame_edit.cgi" target="main">
<INPUT type="hidden" name="html" value="items_ff.html">
<INPUT type="submit" value="Frame編集">
</FORM>
frame_edit.cgi実行画面
更新: 2006-07-14T19:51:28+09:00
[言語学] チョムスキーとフーコー
チョムスキーで更新日記を検索すると、二桁に及ぶぐらいの記事が出てくる。酒井先生の「言語の脳科学」をきっかけとしてだが、関心事のリストに戻ってきた。僕の関心事は当然?なのだろうけど、スモールワールドを形成していて、「フーコー・コレクション 3 言説・表象」の「6. 『ポール・ロワイヤルの文法』の序文」にチョムスキーについての記載を見つけた。
<デカルト派言語学>の検討を通じて、チョムスキーはけっして古典派の文法を今日の言語学に近づけていない。むしろ、両者の未来となり、将来の共通の場を提供しようとするひとつの文法を出現せしめようとしているのだ。すなわち、ことばを離散的要素の集合としてではなく、創造的活動として分析するような文法、表層にあってすぐ目につく言語のさまざまなすがたの下に深層構造が描かれるような文法、諸関連の単純な記述が説明的分析の内部で再現されるような、そして、言語の体系がそれを習得せしめる理性の駆使と不可分であるような文法である。現代の言語学にとってデカルト派文法は、もはやたんにその対象や手順についてなされる新奇な、遠い予兆であるばかりか、それ固有の歴史に参与し、その変容の記録に名を記すものなのだ。(ミシェル・フーコー、「フーコー・コレクション 3 言説・表象」、「6. 『ポール・ロワイヤルの文法』の序文」、1969年、211-212ページ)
フーコーがチョムスキーの仕事の解釈として考えていることは、自らが欲していることのように思えるが、チョムスキーと同年代のフーコーはチョムスキーの変形生成文法の未来に想像力を廻らせていたかもしれない。ChomskyとFoucaultを並べて、ググるとCHOMSKY.INFOの討論の記事が引っ掛かった。フーコーの後年の研究の題材は特にチョムスキーの影響を受けている可能性がある。
日本語によるチョムスキーの解説は、「金川 欣二☆言語学のお散歩(マックde記号論)☆ Rideo, ergo sum. 」にあるものがよさそう。
簡単に言えば、変形生成文法は、言語の深層構造を有限の数の規則で変形すると、あらゆる表層構造を得ることができるということである。従って、深層構造と変形規則から、あらゆる表層構造を説明できる必要がある。それが証明できれば、深層構造と変形規則の仕組みが脳に見つかるはずである。これだけだと、ちょっと単純すぎるかもしれない。言語の深層構造は意識下にあると考えられ、記憶として絶えず変化しているはずだし、言語と記憶との関係はまったく議論されていない。記憶の保持される構造自体がわかっていないどころか、記憶が何かさえわかっていないのだから、現時点では、考えてもしかたがないのかもしれない。感覚や身体との結び付きもあるはずだし、深層構造とは単純な語の集合としての構造ではないように思える。言語が学習され、保持される生得的構造とはどのようなものだろうか。
田中克彦著、「言語学とは何か」、岩波書店、岩波新書(新赤版)303、2003年9月25日第1版第15刷(1993年10月20日第1刷)、229ページ、740、ISBN4-00-430303-6には、チョムスキー批判が展開されているが、チョムスキーは自分のやっていることはよくわかっていると思う。意味的には深層構造が問題になるわけで、単に表層構造の多様性を説明できたとしても、これが文法の目的であるからそれを目指すのは当然であるが、意味を追求するのは、深層構造においてである。表層構造が発現する原理を追及することによって、深層構造が明らかになっていくというフレームワークを提供したところに変形生成文法の価値があるのではないのだろうかと、素人ながら思ってみたり・・・フーコーが述べているのもそのようなことだろう。
文にメタデータを付与して、機械に理解させようとしている人間とは何だろうと思うが、よく考えると1940年代にコンピュータが登場して以来、機械上で走る、様々な言語が出現しているわけで、メタデータを解釈するデータベース(記憶に相当する)によって、メタデータを付与した文が機械の上を有意味に走れば、それは脳の言語的構造をシミュレートしたものといえるかもしれない。プログラミングの研究は、脳の言語的研究に最も近いところにあるのかもしれない。
更新: 2006-07-22T14:45:57+09:00
[Perl] Image::ExifTool
Image::ExifTool - Read and write meta information - search.cpan.orgネタ。[Podcast] 物理的実体(ハードウェア)工作の続き。
Image-ExifToolのドキュメントにあるサンプルを使って、デジカメの画像ファイルのEXIFデータを抽出してみた。簡単。ActivePerlではppmでインストールできる。
C:\Program Files\MySync Photo2 体験版 for A5403CA\BAlbum\2004\7>perl c:\anhttpd\
cgi-bin\imageexif.cgi 040703_1316~0001.jpg
---- ExifTool ----
ExifTool Version Number : 5.32
---- File ----
File Name : 040703_1316~0001.jpg
File Size : 22KB
File Modification Date/Time : 2004:07:03 13:16:58
File Type : JPEG
Image Width : 240
Image Height : 320
---- EXIF ----
Image Description : 040703_1316~0001
Make : KDDI-CA
Camera Model Name : A5403CA
Orientation : Horizontal (normal)
X Resolution : 72
Y Resolution : 72
Resolution Unit : inches
Y Cb Cr Positioning : Centered
Shutter Speed : 0.4
Exif Version : 0220
Shooting Date/Time : 2004:07:03 13:16:58
Components Configuration : YCbCr
Flash : Off
Flashpix Version : 0100
Color Space : sRGB
Exif Image Width : 240
Exif Image Length : 320
Custom Rendered : Normal
Exposure Mode : Auto
White Balance : Auto
Digital Zoom Ratio : 1.25
Scene Capture Type : Standard
---- PrintIM ----
Print IM 0x0001 : 0x00120012
Print IM 0x0002 : 0x01000000
Print IM 0x000e : 0x0000004c
Print IM 0x0101 : 0xff000000
Print IM 0x0102 : 0x84000000
Print IM 0x0103 : 0x83000000
Print IM 0x0104 : 0x80000000
Print IM 0x0105 : 0x83000000
Print IM 0x0106 : 0x83000000
Print IM 0x0107 : 0x80808200
---- Composite ----
Image Size : 240x320
Shutter Speed : 0.4
[Perl] 変形して読む - iCalendar
livedoor天気予報(iCal天気 - Weather Hacks - livedoor 天気情報)のical形式データのDESCRIPTIONには、天気予報の日別ページへのリンクが含まれているのだが、Mozilla Calendarの「イベントを編集」ウインドウにあるURLの項目に取得できない。DESCRIPTION:行からURLを切り出して、URL:行として出力するCGIスクリプト。デスクトップCGIとして動かせばよい。
#!C:/Perl5.8/bin/perl.exe
use strict;
use warnings;
use LWP;
my @header = (
'UserAgent' => "libwww-perl/$LWP::VERSION",
);
my $browser = LWP::UserAgent->new;
use CGI qw(:cgi);
my $ics;
unless(param("ics")){
$ics = "http://weather.livedoor.com/forecast/ical/34/90.ics";
}
print "Content-type: text/calendar; charset=UTF-8\n\n";
my $res = $browser->get($ics,@header);
my $content = $res->content;
my @lines = split(/\n/,$content);
my $line;
foreach $line (@lines){
$line =~ s/^(DESCRIPTION:)(http:\/\/[^ ]+) (.+)$/$1$3\nURL:$2/;
print $line,"\n";
}
実践実用Perlで作成したメモカレンダーを改良する構想は以前から持っているのだが、iCalendar対応というのも課題として取り組むのがよいのかもしれない。
[Podcast] 第五十一回 電脳空間カウボーイ宣言!
やれ、みんな若い。30前後の人たちなんだ。でも、おもしろい。まあ、僕もレベルは低いが同じようなコンピュータ体験は持っているのだが・・・世代がだいぶ違う。テクノロジー系で最大の視聴率を誇るらしいが、おもしろすぎるね。アキバ系!電脳空間カウボーイズ: 第五十一回 電脳空間カウボーイ宣言!ネタ。
やはり、iTunesで購読して、CDに焼いて朝の車で聞くかな。CGIでCDに焼く方法はあるかな・・・
[Podcast] 新しいメディア
今日帰宅すると、700MBのCD-Rを買いに出掛けた。コジマ電機とイオンを廻って、5mmの薄いケースに入った20枚、1280円也のマクセルのCD-Rを購入。Podcastの録音用である。昨晩、アキバ系!電脳空間カウボーイズの54回と55回の2回分を録音しようとして、650MBでは少し足りなかったからだ。昨日は、iTMSのPodcastのリストを調べて、RADIO SAKAMOTO Podcasting Vol.8,9を録音した。通勤の車中往復2時間を如何に有意義に過ごすかは人生の重要な問題なのである(^^;)
アキバ系!電脳空間カウボーイズの第2部は第52-53回の電網音声配信(Podcast)事情前後編から始まった。まずまずおもしろかった。明日は、うまく収まった第54-55回物理的実体(ハードウェア)工作前後編を聴ける。途中で、武田鉄矢の今朝の三枚おろしを聞き逃してしまうのが問題。FMとCDの切り替えを自動化できないものか(^^)
[Podcast] 物理的実体(ハードウェア)工作
アキバ系!電脳空間カウボーイズ: 第五十四回 物理的実体(ハードウェア)工作 前編、アキバ系!電脳空間カウボーイズ: 第五十五回 物理的実体(ハードウェア)工作 後編ネタ。
出演者の声と名前が少しずつわかりはじめたこの頃。keithって、キースと読むのかと思ったら、ケイスなんだよね。「そうだよね」、「なるほどね」という合いの手が抜群のタイミングで入って快い。PSoCが耳にこびりついた。
何か、電子工作をしてみたくなったね。実世界指向プログラミングだよね。5年ぐらい前かな、プログラミングできるロボット(MOVIT WAOⅡ)を半田付けで作ったけど、どこへやったかな。引越しで捨てちゃったか。結局プログラミングはしないまま・・・小さなインターフェースカード(IF-96)までは作ったのに(;_;)調べてみると、エレキットの製品か・・・
ロボットを作っても実用的にはほとんど意味がない。今なら、デジカメやGPSと連動したツールができないかと思う。手持ちのデジカメ、CP-600はPCに接続してリモートで撮影できるのだが、CFメモリカードに記録できなくなってしまったしねえ。撮影地点の緯度経度を記録できるデジカメはおもしろいけど、誰でも思いつきそうな話。自動化処理をするためには、写真画像ファイルに記録されて、それを読み出せないとつまらない。EXIFか・・・
[Podcast] メタデータを作る
アキバ系!電脳空間カウボーイズ: [番外編]ケイス淀橋カウボーイ探訪一人旅 長尾確氏 後編ネタ。話の合いの手がいつもと違うタイミングになるのにも負けずにいつもの調子で喋り捲るケイス氏。とうとう最後は自分のペースに巻き込んだ。が、その後に、ようやくおもしろい話がはじまった。
不明の主語の補完を促すような文章の書き方にまで踏み込んで、構文解析をしてメタデータ生成の自動化ができないかというのは一つの考え方だが、むしろ何のためにメタデータを作るのかという目的に合わせたほうが合理的だ。それをどう利用するかは、またアイデアがあるかもしれない。有効なアイデアはRSSのように亜種を生み出しながら、普及するだろう。
文章の書き方を考えるという方向性は、自然言語を考える意味では重要なことである。しかし、自然言語の相互作用性は定型的な捉え方を拒み続けるのではないか。文を読んで何を読み取るかということは、人によって違ってくる。読む人の経験や知識などによっては理解できない場合もあるし、また、連想によって、深い意味を読み取ることができる場合もあるわけである。そこでは他の文へのリンクさえ生成すべきかもしれないし、新たな文が生成する契機となるかもしれないのである。文を書いたり、読んだりすることは、そのようにダイナミックなものであり、新たな世界を生み出したり、異次元世界に通じる扉を生成する可能性を秘めている。これを支援するような仕組みこそが重要である。
HTMLやXMLのような言語を人間が生み出したのはある意味必然なのかもしれない。機械とのコミュニケーションという考え方もあるけど、むしろ、機械を媒介とした人間同士のコミュニケーションをより円滑にする仕組みになってきているのではないか。メタデータの付与を機械的にやるのはあまり意味がない。作業そのものを自動化するのはいいのだが、機械にはまだ意味はわからない。機械、すなわちPCは人間の拡張であり、インターネットでは拡張された器官を通して、コミュニケートしているのである。
ケイス氏の興味のある中野馨先生については、東京工科大学|教員紹介|バイオニクス学部|中野 馨を参照。死んじゃったっぽいなんて、失礼な(^^)しかし、連想記憶をニューラルネットワークでやるという話はおもしろそうだ。少し調べてみよう。中野馨先生は、ミンスキーとパパートの「パーセプトロン」の共訳者でもある。
更新: 2006-07-23T13:48:38+09:00
[Podcast] 夏とレジャーと電脳空間カウボーイズ
今週のサイバースペース・カウボーイズネタ。前編はカラオケ一色だったので、オイオイと思ったが、後編はおもしろかったね。でも盛り上がりきれなかったかな。いつも出力全開では疲れてしまうから、こんなところで。50回以降全部CD-Rにコピーして毎日聞いている。いやー、何度聞いてもおもしろい。ひとりでニヤニヤ笑いながら車を運転している。他の車から見たら不気味なこと間違いない(^^;)
我がサイトの夏休みネタ。カウボーイネタから出た駒で、夏休み工作に「脳」でも作るかなんて思っている。さて、Cのソースが届いたら、VC++あたりに移植してみようか。場合によっては、Perlで直接書いてもいいかも・・・何かできるかどうかは不明だが、触ってみないと・・・
[Podcast] アキバ系!電脳空間カウボーイズ配信歴史的事情
新しいPodcastはiTunesのPodcastに登録して、iTunesを立ち上げ、Podcastを更新するだけでよいのだが、アキバ系!電脳空間カウボーイズのPodcastを僕が聞き始めたのはたまたま50回からである。以前の番組はどのようにして聴いたらよいのだろう。カウボーイズのサイトを見ても何もわからない。
検索して調べてみると、Yahoo!ポッドキャストは第一回からの番組を聴くことができる(なぜか正規60回目は収録されていないが)。少しずつダウンロードしてCDに焼いて聴いていたのだけど、今日ようやく番外編を含めて、63回分のライブラリが完成。まだ、聴いたのは全体の3分の1を越えたところなので、しばらく楽しめそうだ。
通勤時の行き帰りに繰り返して聴いていると、人間の記憶の曖昧さがよくわかる。聞き取れていないところがわかるようになるからだ。昨年の10月3日に第1回が配信されていて、まだ内容的に新鮮。Webのソフトウェア開発の最新事情がよくわかる。とにかくおもしろいのが何よりだが・・・繰り返して聴くに足る内容を持っているということで、これも才能だろうね。
アキバ系!電脳空間カウボーイズのPodcastライブラリ
アキバ系!電脳空間カウボーイズ: [お知らせ]電脳空間カウボーイズの過去放送分一部を公開終了とさせていただきますの記事が出ている。危ないところだった。
[RDF] iCalendarとRDFical
iCalendarとRDFicalの変換ツールがあっても、RDFicalで動作するアプリケーションがなければ変換する意味がない。iCalendarで動作するアプリケーションがあるのだから、iCalendarを使うことになる。なかなか難しい問題だ。等価な変換であれば元のままのデータでよいということになる。RDFは、具体的にiCalendarの持たないデータと組み合わせる必要があるアプリケーションを考えなくてはならない。必然性が必要である。
[Semantic Web] セマンティックウェブに対するGoogleの疑問
スラッシュドット ジャパン | セマンティックウェブに対するGoogleの疑問ネタ。ちょっと質問がわけのわからないものだが・・・Webmasterって、サーバーの設定ができなかったり、HTMLも書けないものなの^^;知らなかった。
Semantic Web(RDF)が使われるかどうかは、これからの話だろう。何に使うのが便利なのか、思いつくことができれば、放っておいても使うだろう。RSS1.0も機能を拡張すべく改訂すればよいのに。今のままでは使われなくなるだろう。せっかく普及したRDFアプリケーションなのに、RSS 2.0とAtomのXMLアプリケーションになってしまいそうだ。
[Tips] OUT OF SCANとフラップ長
皆実22期会の2H世話人としての努めを果たすべく、案内状に簡単なメモを追加して、最後の案内を送付。宇品郵便局のゆうゆう窓口で出す。封筒に切手を貼って出してくれる。休日でも0-24時間受付だから便利。→ 窓口営業時間のご案内 広島県
Dell2マシンの17インチディスプレイはVista用に取り外し、元々Dell2マシンに付いていた15インチに戻していた。筆まめとインクジェットはこのマシンで使うようにしているので、起動するとOUT OF SCANの表示。XPもそこまでは賢くない。いつのまにか、寝てる間にディスプレィが差し替えられていたとは気が付くまい。逆は問題ないが。
結局、17インチを付け替えて、画面設定を15インチ用に設定しなおして、15インチに戻す。OK(^^)ディスプレィの電源を落とせば、交換はPCを止めるまでもない。もちろん自己責任でやらねばならないけどね(^^;)
案内送付用に準備された封筒の形式、長形3号(120×235)を選択するが、なぜか、差出人の印刷がずれてしまう。フラップ長の設定という項目があるのだが、関係があるのやら、なんのことやらわからない。ヘルプの検索窓に日本語が入力できなくなる症状で、ヘルプも役に立たない。こんなことよくあるよね。やれやれ、そこで、別のマシンでググると、ようやく封筒を閉じる折り曲げ部分の長さだとわかる。準備された封筒は横にフラップがあるので、封筒の長さには関係ない。20.0mmを0に設定する。それでもだめ。いや単に印刷を開始した後に設定を変えても反映されなかっただけ、ようやく気が付いて、印刷をキャンセルして、再度試みる。解決(^^)半日つぶしてしまった。
[Web Development] @media2006
これは一応チェックしておくべきだろう。しかし、日本発のトレンドも欲しいという感じがする。
[Web Development] Webを航海するために
「アキバ系!電脳空間カウボーイズ: 第五十回 電網栞(ブックマーク)とRSSとGoogle」のPodcastは大変おもしろかったというか、同じように感じているところが多いと思った。RSS/Atomの意義は、HTMLにある日記やブログ、ニュース、Wikiの記事要素を標準化し、共通のデータとして取り扱えるようにしたところにある。まだ、それをまともに利用したアプリケーションはない。しかし、RSSはWebをデータベースとして取り扱う端緒となったと後世の歴史家は言うだろう。
ブックマーク + RSS + Googleを越えるもの。ブックマークは今やWebにもあり、Googleはデスクトップに進出している。デスクトップの探し物はGoogleに任せよとも思う。おもしろいように見つかるね。従って、結局、答えはWebとデスクトップの融合にあると思う。Googleはそれをよく知っていると思う。我田引水気味でもあるのだが、自分に必要なものはデスクトップに集積されていくからである。後は地道な検索とブックマーク、そしてメーリングリストとフィードの購読である。それをデスクトップに集積することが大事かも。それをGDSが検索できるようにする。だから下手にバイナリデータベース化しないほうがよいのかもしれない。
次はMicroformatsでほぼ決まりじゃないか。RSS/Atomに続くものになるだろう。RSS/Atomの配信する記事はまだ詳細なメタ情報を持っていない。タイトル、要約、著者や更新日時、カテゴリ程度がメタ情報として使える程度のものだ。記事の具体的な構成要素についてはほとんど無力なのである。記事を構成する各要素について、Microformatsを考えよう。CodeZineの記事の第3回はこれをネタにするつもり。
[Web Development] ちず窓βを使ってみる
昭文社(地図とガイドブックの昭文社)のちず窓は極めて簡単に日記に埋め込むことができる。Google Videoのリンクなどと同じ要領で、生成されたリンクをHTMLに貼り付けるだけ。

問題は、クリックして表示される地図に出るマークの吹流しにサイトを自動的にクロールして勝手なリンクを張ること。いろいろ地図を置く位置を変えてみたが、「モーリス・ブランショ」の記事にリンクが張られてしまう。
Google Mapsは誰もが使えるわけではないけど、独自に様々な工夫が凝らせるのがよい。ちず窓は地図がわかりやすいというメリットがあるので、是非使いやすい仕様にしてほしい。
[Windows] Windows Vista Beta 2 Build 5384 Ⅱ
Windows Vistaワールド探検Ⅱ。
Windows VistaのGadgets
VistaのGadgetsサイドバーを使ってみる。Vistaマシンをテストするのが目的なので、当面必要ないGDSはアンインストール。Gadgetsはリッチなデザインで、Vistaにマッチしている。Macのリッチな雰囲気に似ている。タスクバーのタスクにカーソルを合わせると下から照明が照らす。しかし、期待していたウィンドウの3D表示はサポートされていない。グラフィック専用ボードもないマシンだから動かないだけかもしれない。システムにはWindows EditionはWindows Vista Ultimateとなっている。

「日曜プログラマのひとりごと」AtomフィードのIE 7による表示
AtomフィードをIE 7で表示させたところ、Atomフィードを解析して、並べ替えやカテゴリによるフィルタをサポートする。表示している形式のソースは表示されない。RSSについても同様の機能をサポートしている。

Windows Vistaマシン
15インチディスプレィはWindows Vistaには狭すぎる。1024×768ピクセル。
Windows Vista 1280×1024ピクセル
やはり、17インチディスプレィに変更。PC98時代から使っている年代物だ。これぐらいないと狭い感じがしてしまう。しかし、気に入っていたオーロラのスクリーンセーバーが「3Dハードウェアアクセラレータの機能うんぬん」というメッセージがうろうろと動き回るものに置き換えられてしまうのでがっくり(^^;)
更新: 2006-07-01T16:55:42+09:00
[Windows] Windows Vista Beta 2 Build 5384 Ⅲ
Windows XPとのデザイン以外の違いを探る。
もっとも大きな違いは、Windows Media Centerがあるということ。Mac のFront Rowのようなデザインだ。しかし、これを活かすにはPCに接続できるTVチューナー等の外部機器が必要だ。少し関連リンクを整理しておこう。
[Windows] Windows Vista Beta 2 Build 5384 Ⅳ
WindowsフォトギャラリーはPicasa対抗なのだろうが、そういうレベルで比較してはいけないのかもしれない。フォトギャラリーの写真の鮮明さ・質感には目を奪われた。MS、次の市場は画像処理--写真家へのアピールを強化 - CNET Japanの記事を見て、なるほどとも思った。しかし、まだ、写真のフォーマットはjpegのまま。久し振りに見るCRT画面の錯覚の可能性もある(^^;)単に元々良質の写真であるだけからかもしれない。うむ、XPのメインマシンから見てみよう。液晶のザラツキ感はあるが、元の写真が優れていると結論付けた方がよさそうだ(^^;)
wmvのサンプルのビデオは、「ビデオカードのハードウェア・アクセラレーションが必要なレベルにないか、ハードウェア・アクセラレーションが使えないかである」というメッセージが出て再生できない、と思ったら、Windows Media Playerで開くとキチンと再生できた。さすが、Betaだ。
更新: 2006-07-03T22:25:10+09:00
[Windows] IE 7 Beta 3 for XP
XP用のIE 7 Beta 3が出た。VistaのIE 7とそっくりで、RSS/Atomのブラウザが内蔵されている。ブラウザはこれに任せるという手もあるねと思うぐらいよい。しかし、新しいタブを開いたりするとよく落ちる。まだ、不安定。
IE 7 Beta 3 for XP
 glucose2のバージョン情報
glucose2のバージョン情報
 花火(1)
花火(1) 花火(2)
花火(2) 花火(3)
花火(3) 花火(4)
花火(4)