
 ���j�v���O���}�̂ЂƂ育�Ɓ@�@�X�V���L�C���f�b�N�X | �X�V���LURL�C���f�b�N�X | RSS 1.0
���j�v���O���}�̂ЂƂ育�Ɓ@�@�X�V���L�C���f�b�N�X | �X�V���LURL�C���f�b�N�X | RSS 1.0
�t�H�[�T�C�g4�����l�^�B�~�c����̃V���R���o���[����̎莆91�B�����瑤�̓O�[�O�����������Ă���悤�ȏ�d���B�����瑤�̓p�[�\�i���R���s���[�^�̂悤�Ȍl�̏�����u�B�ǂ��炪�������B�O�[�O���̂ق��������̂ŏ��̏d�S�͌l�̑����͏�d�����ɌX���Ƃ����̂��_�_���B�������A����͎g��������������Ƃ�������B�g�����̍H�v�A���邢�͌l�̏�����u�̐��\����ɗ͂𒍂��ׂ������B�n�[�h�I�ɂ̓z�[���O���b�h�Ƃ��A�p�[�\�i���O���b�h�Ƃ��A�N���ł��o���Ă���Ȃ����B�Ƃ����l����(^^;)�\�t�g�E�F�A�I�ɂ̓X�N���v�g����̊��p�Ƃ������ƂɂȂ�(^^)v
�X�V���L��3���N���}�������Ƃ�Y��Ă����B�n�߂����͂܂�blog�Ƃ����p����Ȃ��������A���L�͊��ɕ��y���Ă����B��ʓI�Ƃ͌����Ȃ�������������Ȃ����B�p���͗͂Ȃ�ŁA�����͐i�����邱�Ƃ����邾�낤�B���ꂩ����l�X�ȏ��̗��j������ł������Ƃ��낤�B
http://jarp.jin.gr.jp/diary/200403c.html#200403302
�킽�Ȃׂ����Just another Ruby porter,��RDF�����Ɛ��̃��[�_�[�ɃZ�b�g������A�j���[�X����э���ł����BActivePerl�͏o��̂��낤���E�E�E
/.org��ǂ�ł���ƁA�ŋߐV�����v���O���~���O����̘b�肪�������Bprototype-based object-oriented language���BProthon�ASlate�BProthon��Python��Self�����킹���͂����V���v���Ȍ���Ƃ����ӂꂱ�݂ł���BPython��metaclass�̓G�L�X�p�[�g�ł������ɂ��Ȃ�悤�Ȃ��̂炵���B����͎���ɕ��G�����A����ɗ��������������̂ɂȂ�B�����͕��G������A���ꂪ���G������͓̂��R���B�K�v�ȃ��W���[���������Ă���ƁA�����Ǝv���Ă��܂��B���W���[���̓u���b�N�{�b�N�X����(���g��ǂ߂������A�ʓ|����)�A���{��̏���������ꍇ�͎����ŏ������ق������S�Ƃ����ꍇ������B�ꉞ�A�����N���c���Ă������B
�\�t�g�E�F�A�f�U�C��4�����l�^�BD�����ւ̏��ҁB�܂��܂����悢�v���O���~���O��������߂ĖO���Ȃ��Nj��������̂ł���BD��C++�AJava�AC#�̌�p��_���BD���Љ�Ă�����̓Q�[���̃v���O���}�Ŏ��ۂ̎d���Ɏg���Ă���B�Q�[���̏ꍇ�̓��C�u���������삷��̂����ʂȂ̂ŁA�A���t�@�o�[�W�����ł����Ȃ��炵���B
Ruby��PDF��������@�����邩�ǂ������ׂ��B
PDF::Writer Technology Preview
zlib�̃��C�u�������g���̂ŁARuby��1.8�ȏオ�K�v�B�t�H���g��AFM(Adobe Font Metrics)���g���Ă���̂ŁA���{��̕����̐����Ɋւ��Ă͐����邾�낤�B�O�ɏЉ��PDFJ��Type1�ATrueType�t�H���g���T�|�[�g���Ă���B
�ŋ߂ł́AFPDF-J�̂悤��PHP�ł����{��PDF���g����B��ϕ֗��Ȑ��̒��ɂȂ��Ă����BPDF Writer�̓Y�t���������Ă���ƁAAdobe��PDF�֘A�̓������قƂ�ǃ��C�����e�B�[�t���[�Ń��C�Z���X���Ă���B�t�H�[�}�b�g�y�����邽�߂ɗL�������A�r�W�l�X�Ƃ��Ă���ϐ������Ă���B�A�h�r��1�l�������Z--PDF�D���Ŕ���E���v�Ƃ��ɑ啝����
Bayesian Analysis For RSS Reading �Ƃ����L�����ATPJ March 2004 �ɏo���BSimon Cozens �̎��M�ł���B�L���ɏo�Ă��郂�W���[�������X�g�A�b�v���Ă������B���\���ɗ������Ă���ɂ��Ȃ��̂��c�O�����A�ɂ��������Ƃ��Ă������ɂ͎��p�ɂȂ�Ȃ����낤�B�Ȃɂ���A�����Ώۂɂ��錾��͓��{��Ȃ̂�����B���N���̉ۑ�ɂ��Ă��悢���炢��������Ȃ��B
���o�o�C�g4�����L���l�^�B�Ȃ��Ȃ���邶��Ȃ��Ǝv�����B��\���I�f�[�^���ǂ̂悤�ɏW�ς��Ċ��p����̂��A���ꂪ��肾�B
�p�[�\�i�����x���ł́A���i�ɂ͋����͂Ȃ��B�t���[�̂��̂����X�g�A�b�v���悤�BPrevayler��Java�����łȂ��ARuby�APython�APerl�ACommonLisp�ASmalltalk�AC#���ł��g����B�X�N���v�^�Ȃ炱���炩�B
�������A���ⓖ����O�̃f�[�^�x�[�X�ł͂������낭�Ȃ��Ƃ����C������BRafal Bogacz�́uImplementing Knowledge Database in Neural Networks�v��1996�N�̕��������A�������낻�����B
XSL-FO�Ȃǂ̐V����XML������XML�u���E�U�ׂĂ݂��BDocZilla��BrownSauce RDF Browser�AX-Smiles��Google�̌����̍ŏ��̃y�[�W�ɕ��ԁB
DocZilla��Mozilla���x�[�X�ɂ��Ă��邾��������HTML�u���E�U���p�Ŏg����B�d�|����docset.xml�Ƃ����t�@�C���ɂ���A�T�C�h�o�[�ɃT�C�g�̍\�����c���[�\���ł���Bnote!�Ƃ����{�^���ɂ�钐�߂̓T�[�o�[���Ő������Ă���悤���Bindex.xml�̕`��ɂ�XML�̃X�^�C���V�[�gindex.css���g���Ă���B
BrownSauce RDF Browser��Jetty�Ƃ���Web Server & Servlet Container���g���Ă���BRSS��FOAF�Ȃǂ�RDF�̃f�[�^�������Ă���A���̂悤�Ȏd�g�݂����ڂ���邾�낤�B
X-Smiles�͂��̒��ł�SMIL(Synchronized Multimedia Integration Language)���g������̂Ƃ��Ē��ڂ����B�T���v�����������낢�̂Ŏ����Ă݂�Ƃ悢���낤�BJava�n�̃A�v���P�[�V�����ł���Ȃ���A�c�O�Ȃ�����{��͕\���ł��Ȃ������BPDF�̐����ɂ͂�͂�FOP���g���B
BayServer�ł�FOP���g���B�������AWindows��̃R�}���h���C���ł�xi�����܂������Ȃ��B���̊���Java�W�̃A�v�����C���X�g�[�����邽�тɈقȂ�o�[�W������Java���C���X�g�[�����ꑱ���Ă��邽�߂�������Ȃ��B�g���qfo��XiServlet���}�b�v��������@���悭�킩��Ȃ��BOXF�̏ꍇ�̓u���E�U��ł��̂܂ܓ��������{��͕\���ł��Ȃ��B����̓t�H���g�̖��Ǝv���邪�B
���������PDFJ�ɋv���Ԃ�ɐG���Ă݂��BPDFJ-0.73.zip��Cygwin���make����BPerl��5.8.2���Bdemo.pdf���폜���āAdemo.pl�����ƃX�N���v�g�̓V�t�gJIS�̂܂܂��Ǝv�������A������PDF�������o���オ��B�f���炵���BXML���������PDF���ł���Bxpdfj.pl�������߂ɂ́AXML::Parser���K�v�BCygwin�ɂ͕W���œ����Ă��Ȃ��̂ŁAperl -MCPAN -e '$ENV{FTP_PASSIVE} = 1; shell'��CPAN����̃C���X�g�[���������Ă݂��BCPAN���W���[���̐ݒ�̃v���Z�X�ł͂قƂ�ǂ��̂܂�YES��OK���B����܂��A�����ɓ����Ď����ŃC���X�g�[�����ꂽ�BActivePerl��PPM�ɗD��Ƃ����Ȃ��Bxpdfj.pl�����Ȃ��������BPDFJ��JIS X 4051�ɂقڏ����������{��g�Ń��[����g�ݍ���ł���̂������Ƃ������ƂȂ̂ŁAXSL-FO�ɑΉ����邱�Ƃ͂���قǓ���Ȃ���������Ȃ��BPDFJ�ɂ��Ă�CGI�ł��g���邾�낤���A�l�X�ȗp�r���l������B
XML��(XSLT)��XSL-FO�Ƃ���W3C�̕W�������i��ł��Ă���̂ŁA�����XSL-FO����āA�����o�͂�����APDF�̂悤�Ȉ���p������������A��ʏo�͂�������Ƃ����悤�ɂȂ�BXSL-FO�̐������ǂ�����������̂��Ƃ������͂���BXML-FO�pWYSIWYG�G�f�B�^���l����̂ł́A�t��H��悤�Ȃ��̂ŁA�������낭�Ȃ����낤�B�L�͂Ȉ�̕��@�ł͂��邪�A�f�[�^�x�[�X�I�ȌJ��Ԃ���Ƃɂ͌����Ȃ��BXML�͏璷�ňꗗ���ɖ�肪����̂ŁA��ʓI�ɂ͑��̉ǐ��̍����L�@�ւ̗v�������܂邾�낤�BXML/RDF�ɂ�N3����Ă���Ă���B�����I�ɕ��������邽�߂̕W������XML�Ƃ����e�L�X�g�x�[�X�Ői�ނ̂͑�ϑf���炵�����Ƃł���BXSL-FO������A�e�v���b�g�t�H�[���ɋ��ʂ̏o�͗p�f�[�^���ۏ����悤�ɂȂ�B�X�N���v�^�ɂƂ��Ă͊y���݂�������ɈႢ�Ȃ��B����͈ꎟ�f�[�^��(�X�N���v�g����)��XSL-FO�Ƃ����\�}�����R�L�蓾��B[modified: 2004-03-20]
XML�A�v���P�[�V�����̍Ő�[���o�����悤�Ǝv���A�T�[�o�[��XML����舵����V�X�e�����K�v�ɂȂ�B���܂��܌�����Orbeon��OXF(Open XML Framework)��30days trial���C���X�g�[�����Ă݂��BXForms�AXQuery��PDF�̐����Ȃǂ�������B���l�x�C�L�b�g���L���������Ȃ��Ǝv���o���ăC���X�g�[�����Ă݂��B���ꂼ��Axpl(XML Pipeline Language)��xi(eXtend It)�Ƃ���������g���̂��������B
�������AXML�������̂͑�ς��Ƃ������Ƃł���B������\�������邽�߂ɂ�HTML�ɕϊ�����K�v������킯�ŁAXML/XSL���g�����AXML/XPL���邢��XML/XI�̂悤�Ȃ��̂��g�����ƂɂȂ�BXML�n�̃v���O���~���O����͉ǐ����Ⴂ���A�e�L�X�g�����Ɍ����Ă���Ƃ͎v���Ȃ��BXML/Perl�Ƃ��AXML/Python�Ƃ��AXML/Ruby�Ƃ��A���̂悤�ȑI�����������ł͂Ǝv���̂����B
OXF�����ɂ́AstartOXF.bat�����̂悤�ɏ��������Ďg���Ƃ悢�BJava��Tomcat���܂ރZ�b�g�ŃC���X�g�[�������ꍇ�̗�ł���BJava�͂��낢��Ƒ��ɂ��C���X�g�[�����Ă�������ATomcat�����ɃC���X�g�[������Ă�����̂����邱�Ƃ��������낤�B������ɂ���A���̂܂܂ł͓����Ȃ��B
@echo off SETLOCAL set CD=C:\Program Files\OXF set JAVA_HOME=%CD%\jdk-1.4.2_01 set CATALINA_BASE=%CD%\tomcat-4.1.27 set CATALINA_HOME=%CD%\tomcat-4.1.27 set CATALINA_TMPDIR=%CD%\tomcat-4.1.27\temp cd %CD%\tomcat-4.1.27\bin echo Starting OXF... catalina.bat run
���ǂ�HTML�ŕ\������Ă���킯�ŁA���ׂĂ�XML���g���͕̂��G�ɂȂ邾���B�p�[�\�i���ȃ��x���ł̓����b�g�������Ȃ��Ƃ����̂������Ȋ��z�ł���B�f�[�^�̕W�����ɍi���Ďg���̂��悢�̂ł͂Ȃ����B�܂��A�܂��g������ł��Ȃ��̂ŁA�����b�g���������Ă���\���͂���B���炭�V��ł݂悤�BXForms��XQuery�����ۂɓ����̂����Ăǂ��������̂��m�F���������������Ȃ̂����A����͌���قǂ̂��̂ł͂Ȃ�������������Ȃ��B
/.�����̗���͖��f���p�����H�̋L���̌��L���A�l�C�E�F�u���O�͕p�ɂɁu���f���p�v�\�\�E�F�u���O�Ԃ̏��̗��������ɂ��郊���N�B
�o���̖����ɂ��ẮA�ǂ����Ă��ꎟ���݂̂ɂȂ�ꍇ�������B�j���[�X�T�C�g�̋L���܂ň��p���ׂ����ǂ��������ǁA�j���[�X�T�C�g�̋L���݂͂�Ȓm���Ă��邵�A�����킩�邱�Ƃł͂���B
��L�A�i���C�U�͗L�p�ł���B���_�A�ړI�̂��̂�������Ƃ������́A���l�^������\�͂̂���T�C�g�������邽�߂ɗL�p�Ƃ������ƂɂȂ�̂��낤�B�L���ɂǂ̂悤�ɕt�����l���t���Ă����������邽�߂ɂ́A�L���̗����ǂ��Č����悤�ɂ��Ăق����B�t�����l�̂ق����d�v�Ƃ����ꍇ���L�蓾�邾�낤�B
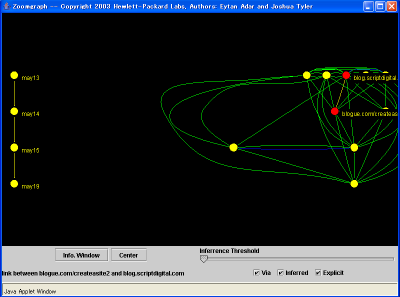 Blog Epidemic Analyzer��Zoomgraph
Blog Epidemic Analyzer��Zoomgraph�l�X�ȏ����L�q���邽�߂̌���Ƃ��āA���݁AXML�����W������B�����Machine Understandable���ړI�ł���B�ł�Human Understandable�Ȃ͓̂��R���R����ł��邪�A�v���O���}�u���ł͂Ȃ��BHTML�u���E�U(XML,XSL/XSLT) = ���R����I�\���Ƃ������ƂɂȂ�B���R����͔]�̒��ł̓v���O���}�u���Ƃ������A�](���R����) = �v�l�Ȃ�Ă��ƂɂȂ��Ă���Ǝv����B���������ϓ_����l����Ǝ��R�������舵�������Ƒ��̕��@�������Ă悢�悤�ȋC������B�]�͎����I���R����u���E�U�ł����āA���ꎩ�̂��v�l�ƂȂ�̂�����A���R����u���E�U����邱�Ƃ��ł���A����͔]�̂悤�Ȍ���@�\�����͂����B����͒m���̌��ѕt�����A�W�ς̎d������Ϗd�v�Ȃ̂ł͂Ǝv���B�܂��͈Ӗ���̍\���̂悤�Ȃ��̂��ł��āA�Ӗ��̂���A�N�Z�X���ł�������킯�����ǁA��̓I�ɂǂ̂悤�ȃA�v���P�[�V�������z�肳��邾�낤�BXML�Ɋւ��Č����A���[���̋L�q�E���_�̂悤�Ȃ��Ƃ��z�肳��Ă���̂ŁA����̓W�J�ɂ����ڂł���B���^�f�[�^���Ӗ�����`������ƍl���邱�Ƃ͂ł���B
���ǁA���̂悤��SF�I�v���͐������@�Ȃǂ̌���w�ւ̋����ɂȂ���B�`�����X�L�[����J���Ă��邮�炢������A����ȂɊȒP�ȉ�������͂����Ȃ��B
XML�Ŏg�p���郁�^�f�[�^�̕W�����ɂ��Ă�Dublin Core���L�������A����̕������Ƃ��ẮA���^�f�[�^�̎����̂悤�Ȃ��̂��K�v�ɂȂ�̂ł͂Ǝv���Ă���BRSS�Ȃǂ���舵���Ă��Ă��A�Ǝ����O��Ԃ̃��^�f�[�^���g���Ă��āA�����Ӗ��̗v�f�����݂��Ă���P�[�X��������B�����XML�����߂��邽�߂̃��^�f�[�^�̎��W�ƃV�\�[���X�̕K�v�������ɔ������Ă��邱�Ƃ��Ӗ����Ă���B
Welcome to "Why?�@Programming"
�����啪�ȑO�̂��ƂɂȂ�̂����A���N��10�����������AAransk����(�O���[�v���炵��)����FGALTS�ŃA�i�E���X�����������B�悤�₭�{�i�I�Ƀz�[���y�[�W��������Ƃ̂��Ƃ������B���͎��܃A�N�Z�X���Ă��āA�f���炵���̂����ꂽ�Ȃ��Ǝv���Ă����Ƃ��낾�����B�������܂��܌��ɍs�����̂ŁA�����N�������ɋL���Ă������BJava�Ɗ��^����ɋ���������Ȃ�A�`���Ă݂�Ƃ悢�B�ʏ�̃v���O���~���O�E�T�C�g�Ƃ͈ꖡ�����Ⴄ�����ǂނ��Ƃ��ł���B�肵�āA�N�w�I�v���O���~���O�ւ̏��ҁB
�v���O���~���O����ւ̊S�̂���������Ǝ��Ă��镔��������B�����̂���~�����v���Ă���̂́A�m�����L�q���邽�߂̃v���O���~���O����ł���BProlog�ւ̊S�������ɂ���̂����ALisp�����l�Ȑ����������Ă���̂��낤�Ǝv���B
AWAKENING Project�̃y�[�W�̃����N���C�������B���̑��A�v���W�F�N�g���\����AWAKENING Project�ɓ���B
http://www.technologyreview.com/articles/roush0304.asp
Technology Review�̋L���B�ŋ߁A�\�t�g�E�F�A�f�U�C������DIGITAL GADGET�ł��u�V������}���錟���Z�p�v�����W���ꂽ�B�Ⴆ�Agrokker2�͌������ʂ��J�e�S���C�Y���ăr�W���A���ɊK�w��\�������p�u���E�U�ł���B�������A���̂悤�ȃC���^�[�t�F�[�X���g���₷�����A�������ʂ�ǂݎ��₷�����A�K�v�ȏ��ɃA�N�Z�X���₷�����Ƃ����Ƌ^��ł���B�K�v�Ȃ̂͌��ǂ͌X�̒��g�Ȃ̂ł���B���[�U�[�����g��ǂނ܂ł͕K�v�ȏ�ǂ����킩��Ȃ��B�t�Ɍ��������܂ł킩��悤�ȃc�[�����]�܂�Ă���̂ł���B���[�U�[�͂��ꂾ�����Ƃ����ŏI�I�Ȍ��ʂ��������̂ł����āA�������ʂ̍\�����������킯�ł͂Ȃ��B�ǂ�����悢�����āA�����_�ł͌��������H�v���Ȃ���A�������J��Ԃ��ẮA�X�̏��̒��g���Ђ�����ǂނ����Ȃ��B���̂��߂ɂ́A���̂悤�ȃr�W���A���ȃC���^�[�t�F�[�X�͂ނ���ז��ɂȂ�B�ǂ��܂Ń`�F�b�N�������킩��ɂ�������ł���B
TR�̋L���ɂ�Google��Microsoft�̐}���Ŏ����㌟���Z�p�̊J���̌����|�[�g����Ă���B�挎���������Љ��Daphne Koller�̓X�^���t�H�[�h��w�����AGoogle�̋Z�p�f�B���N�^�[��Craig Silverstein���X�^���t�H�[�h��w�̃R���s���[�^�Ȋw�̃h�N�^�[�ŁA60�l��PhD���܂ސ�100�l�̌����҂�J���҂�����Ă���B���̃u���[�N�X���[��Google���琶�܂�邱�Ƃ�]��ł��邪�A���̕ۏ͂Ȃ��ƔF�߂Ă��邻�����B
grokker2�̃g���C�A���ł��C���X�g�[�����Ă݂��B���{�ꂪ���͂ł��Ȃ��͎̂d�����Ȃ��B���{�ꕶ�̃J�e�S���C�[�[�V�����������ȒP�ɂł���͂����Ȃ����ALonghorn�ɓ��ڂ����ƌ����錟���C���^�[�t�F�[�X���ȒP�ɈڐA�͂ł��Ȃ����낤�B�}��google�Ō����������ʁA���\�����ɓ����ĕ\�������B
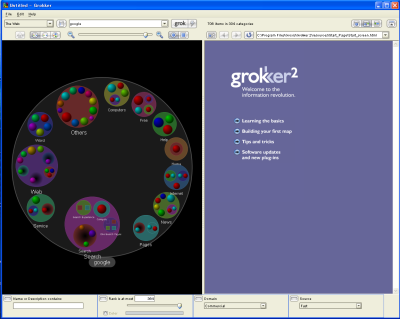 grokker2��google����������
grokker2��google����������TR�Ŏ��グ���Ă��錟���G���W�������X�g�A�b�v���Ă����B
Mooter��Web��ŕ��ނ����N���X�^�[���r�W���A���ɕ\���ł��邪�A������X�L�b�v���ĕ\�������邱�Ƃ��ł���B
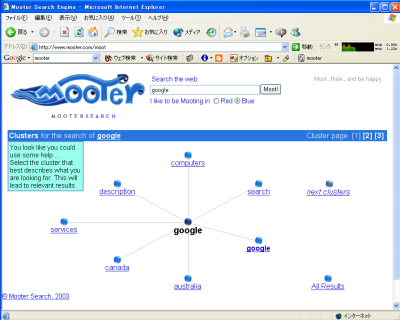 Mooter��google����������
Mooter��google����������AskMSR�ɂ��ẮAMicrosoft Research�Ō�������Ε����ɂ������邱�Ƃ��ł���BN-Gram���g���Ă���B
http://japan.linux.com/opensource/04/03/11/0147235.shtml?topic=1
�\�t�g�E�F�A�����̖��͑傫�����낤�B�����̊J���������̂̓`�F�b�N���Ȃ��Ƃ܂����̂����B�܂��o�肷��Ȃ�A��s�Z�p�͒������邱�ƂɂȂ邪�E�E�E
����w�͂�����10�N�ԂŔF�m�Ȋw�̈ꕪ�삩��l�Ԑ����w(human biology)�Ɉڂ��Ă����B30�N�O�͂܂��\�V���[���̍\����`����w�̐��E�������B���̍��͌���w�͂ƂĂ������w�ƌ��т��Ƃ͎v���Ă��Ȃ������ˁB���ꂩ��N�w���l�Ԑ����w�ɂȂ�̂��ȁB���w�́A���j�́A�Љ�w�́E�E�E�Ȃ��l���Ȋw�͑S���l�Ԑ����w�ɂȂ����肵��(^^;)���̍��A�u�������@�̊�āv�̊��z�B
�m�[���E�`�����X�L�[���A���䒼���E�Ҏq���ێq��A�u�������@�̊�āv�A��g���X�A2003�N�A365�y�[�W�A3600�~�B
��łƂȂ��Ă���20�N�ȏ�O�̑Βk(1982)�̕�����2002�N�H�ɍs��ꂽ�ŐV�C���^�r���[�Ƃ����킳�ꂽ�{�Ƃ��������[�����BGARY MARCUS�̖{�ƈꏏ�ɒ������Ă��܂����B�����ǂ�ł݂悤�B����قljɂ͂Ȃ��͂��Ȃ��E�E�E
�V�����ɂēǗ��B���̖{�u�]����݂��S�v(�Ӗ���̍\�� 2004/02/29)�͌����]�ɂ��ĕ�����ꍇ�ɕK�v�Ȕw�i�m����^���Ă����B�m�[���E�`�����X�L�[���A�����וF�E�����i�c�q��A�u����ƔF�m �S�I���݂Ƃ��Ă̌���v�A�G�p���[�A2004�N�A171�y�[�W�A1800�~�߂Ă���ƁA�����Ӗ����悭�킩��C������B���̖{�̌����́u�]����݂��S�v�Ɠ�������1987�N�ɏ�����Ă���B�]�̎����ɂ�錾��ւ̉e���ɂ��Ă̓`�����X�L�[�������S�������Ă��邵�A�u�`�T��ǂނƁA�����Ǝ����ɂ��ؖ��Ƃ������R�Ȋw�̎�@���\���Ɉӎ����Č��ꗝ�_���������Ă��邱�Ƃ��킩��B
NATURE|VOL427|19FEBURUARY2004|�l�^�BA recipe for the mind�Ƃ����^�C�g���ŁAAnthony P. Monaco��Gary Marcus�́uThe Birth of the Mind: How a Tiny Number of Genes Creates the Complexities of Human Thought�v�Ƃ����{�̏��]�������Ă���B�h���I�ȃ^�C�g�����BAnthony P. Monaco�̃I�b�N�X�t�H�[�h��̃z�[���y�[�W���h���I�ȃ^�C�g���������Ă���BNeurogenetics�B�]�ɂ���ĐS����������Ȃ�A�]�̐���������t�����`�q���S�̌`���ɉe������͂��Ƃ�������̉��Ɉ�`�q���������Ă���B���R�Ƃ����Γ��R�̘b�Ȃ̂����A�����|���悤�Șb�ł�����B�`�����X�L�[�̃R�����g��Marcus�̃z�[���y�[�W�ɍڂ��Ă���BAmazon�ɒ���������A���������̃��[�����͂����B�]�Ȋw�͐i�����Ă���(^^;)
�f���炵���R���e���c�BRadio in PC ���B�p��̃��X�j���O�̕�������Ȃ炱�������B�����̍D���ȃR���e���c���I�ׂ邵�A�ǎ��̉p������Ƃ��ł���B
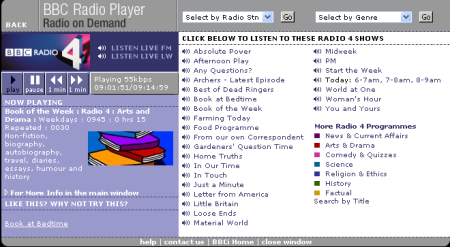 BBC Radio Player
BBC Radio PlayerPerl6�̐V����format�@�\�ɂ���13�y�[�W�ɓn��ڍׂȉ��������B��������format�BJPDB�ȗ��A�ŋ߂͎g��Ȃ���(^^;)���|�[�g�����͖{����Perl�̑��ݗ��R�ł���ƁE�E�EPerl��r��report�����̂ˁB
�v���Ԃ��Parrot��Cygwin��ŃA�b�v�f�[�g���Ă݂��Blanguages�f�B���N�g����`���ƁAruby�Apython�Atcl�̃f�B���N�g��������ˁB
jscripter@Dell2 /parrot/languages $ ls BASIC befunge converter.pl m4 perl6 ruby Befunge-93 bf forth miniperl plot scheme CVS cola imcc ook python tcl LANGUAGES.STATUS conversion jako parrot_compiler regex urm