 ���j�v���O���}�̂ЂƂ育��
���j�v���O���}�̂ЂƂ育��
�C�ے����~�J�����錾�B���ԁA�A�e���U��ambient�̉��x�\����35���������Ă���B
TSNET�ł̘b�������������iCalendar�����������ƂɂȂ����BRFC2445��RFC2446����������B���ꂼ��A148�y�[�W��109�y�[�W�BMozilla Calendar�̎����ɍ��킹�āAiCalendar�o�͂������l����̂��悢���A����A�����J�����_�[�Ɏ������Ă����������E�E�E�����J�����_�[�ɋ@�\����������Ȃ�AiCalendar�ɂ������K�v���Ȃ����E�E�E�j�Փ��̃}�[�L���O��iCalendar�f�[�^���g�����Ƃ��ł���̂̓����b�g�ɂȂ�E�E�E
�����J�����_�[�͓��t�ʂ̃����t�@�C����F�����āA���t�Ƀ����������N���Ă���̂����A�g��J�����_�[�����̂Ȃ�A�ʃ����̋L���^�C�g���̕\�����K�v���낤�B�j�Փ��́A�J�e�S���ɃC�x���g������āA�����ɏ������ނ����ł悢�B���̃����J�����_�[��������������A�X�V���L�ɂ��J�����_�[���������邱�Ƃ��ȒP�ɂł��邪�A���L�̃J�����_�[�ɂǂ�قǂ̈Ӗ�������̂��͋^�₾�B�����J�����_�[�́A���t�̃X�P�W���[���J�e�S���̃������쐬����t�H�[�������郊���N�������Ă���B
iCalendar��RDFical�̕ϊ��c�[���������Ă��ARDFical�œ��삷��A�v���P�[�V�������Ȃ���Εϊ�����Ӗ����Ȃ��BiCalendar�œ��삷��A�v���P�[�V����������̂�����AiCalendar���g�����ƂɂȂ�B�Ȃ��Ȃ������肾�B�����ȕϊ��ł���Ό��̂܂܂̃f�[�^�ł悢�Ƃ������ƂɂȂ�BRDF�́A��̓I��iCalendar�̎����Ȃ��f�[�^�Ƒg�ݍ��킹��K�v������A�v���P�[�V�������l���Ȃ��Ă͂Ȃ�Ȃ��B�K�R�����K�v�ł���B
Yahoo!�|�b�h�L���X�g - �A�L�o�n!�d�]��ԃJ�E�{�[�C�Y - ��\�O�� �d�ԑM���Z�p��(�t���b�V���E�e�b�N)�l�^�B
�P�C�X���������Љ�̂��������Y����T�����B
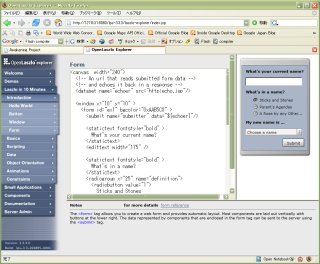 OpenLaszlo Explorer
OpenLaszlo Explorer�C���X�g�[������ƃ|�[�g�ԍ�:8080��Tomcat���N�����āAFirefox�ɕ\�������B����Ƃ���A���A�t���b�V���A����[�����������BXML�Ńt���b�V���̃v���O���~���O���ł���炵���B�{���I�ɂ́A�t���b�V���̋@�\�̒��ۉ����i��ł��āA���̃V�X�e���ɕϊ����e�Ղɂł���悤�ɂȂ�̂�������Ȃ��B���_�A���̃V�X�e���Ƃ͉����Ƃ������͂��邪�BWeb�u���E�U�̕\�����ǂ̕����Ɍ������̂��E�E�E
�V����Podcast��iTunes��Podcast�ɓo�^���āAiTunes�𗧂��グ�APodcast���X�V���邾���ł悢�̂����A�A�L�o�n!�d�]��ԃJ�E�{�[�C�Y��Podcast��l�������n�߂��̂͂��܂���50��ł���B�ȑO�̔ԑg�͂ǂ̂悤�ɂ��Ē�������悢�̂��낤�B�J�E�{�[�C�Y�̃T�C�g�����Ă������킩��Ȃ��B
�������Ē��ׂĂ݂�ƁAYahoo!�|�b�h�L���X�g�͑���̔ԑg�����Ƃ��ł���(�Ȃ������K60��ڂ͎��^����Ă��Ȃ���)�B�������_�E�����[�h����CD�ɏĂ��Ē����Ă����̂����ǁA�����悤�₭�ԊO�҂��܂߂āA63�̃��C�u�����������B�܂��A�������̂͑S�̂�3����1���z�����Ƃ���Ȃ̂ŁA���炭�y���߂������B
�ʋΎ��̍s���A��ɌJ��Ԃ��Ē����Ă���ƁA�l�Ԃ̋L���̞B�������悭�킩��B�������Ă��Ȃ��Ƃ��낪�킩��悤�ɂȂ邩�炾�B��N��10��3���ɑ�1�z�M����Ă��āA�܂����e�I�ɐV�N�BWeb�̃\�t�g�E�F�A�J���̍ŐV����悭�킩��B�Ƃɂ����������낢�̂�����肾���E�E�E�J��Ԃ��Ē����ɑ�����e�������Ă���Ƃ������ƂŁA������˔\���낤�ˁB
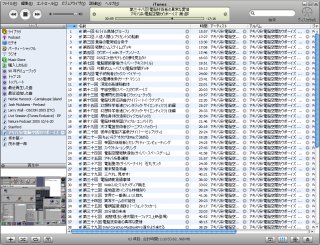 �A�L�o�n!�d�]��ԃJ�E�{�[�C�Y��Podcast���C�u����
�A�L�o�n!�d�]��ԃJ�E�{�[�C�Y��Podcast���C�u�����A�L�o�n!�d�]��ԃJ�E�{�[�C�Y: [���m�点]�d�]��ԃJ�E�{�[�C�Y�̉ߋ��������ꕔ�����J�I���Ƃ����Ă��������܂��̋L�����o�Ă���B��Ȃ��Ƃ��낾�����B
�����Œ��A���A�������Ȃ���W���X�R�Ɍ����ĕ������B�d�Ԓʂ肩�琉���̃o�X�ʂ�ւ̋Ȃ��蓹�̉��f�����ŋN�����炵����ʎ��̂̌��̏��������Ă���̂߂Ȃ���A�d���̉e�ɂ�����ĐM���̕ς��̂�҂B�Ă��Ƃ��Ƃ�����Ă����B
�������̐l�X���悯�Ȃ���A3�K�̃t�^�o�}���ɏオ��B�����ڂɂ����̂��A�w�l����l �n��4���N�L�O���W �����{�́u�l����l�v100�l100���x�B�l����l�͍ŏ��̔N�͍w�ǂ����̂����A�Ȃ��A���o������Ȃ���2�N�ڂ��璆�~�����̂����B100�l100����1�������Ǝv�������ǁA100�l���ꂼ�����Ƃ������ƁB����̓Ǐ��ɎQ�l�ɂȂ肻���B
���ɂ́A�{�V�搶�Ɠ��c���搶�̑Βk�A�u���_���l�A���t�̒�`�A���{�l���߂����āv�B�܂�Ȃ����_�������ȂƂ����̂́u�������܂�߂�ȁv�Ƃ����{�V�搶�̂��̌����̓��c�搶���\���B�f�X�N�g�b�v�ɂǂꂾ���䖝���ċ^����L���Ă����邩�B���ꂪ��Ƃ������ƁB����Ɍ��_���o���Ȃ��B
100�l100���ɂ��Ă̒ؓ��S�O���ƈ��͈ꎁ�̑Βk�w�u�l����v���߂�"�f�U��"�x�B���낢�뒲�ׂ���A�������肵�đf�U������Ȃ��ƍl�����i�܂Ȃ��B�����Ȃ��̂͂����ȒP�ɂ͏����Ȃ����̂��B
Text World��livedoor�V�C�\��̕ό`�ł��o�͂���CGI��u���āAGoogle Calendar����ǂ߂�悤�ɂ��Ă݂��B�܂������Ӗ����Ȃ��BURL:���ڂ���͕\���ł��Ȃ����炾�B���̂܂܂Ȃ�ADESCRIPTION�Ɋ܂܂��URL�Ƀ����N���ĕ\������B
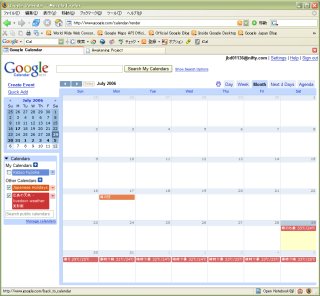 Google Calendar
Google Calendar���ǁA�t���̋@�\���g�����Ǝv���Ύ��삷�邵���Ȃ��B
livedoor�V�C�\��(iCal�V�C - Weather Hacks - livedoor �V�C���)��ical�`���f�[�^��DESCRIPTION�ɂ́A�V�C�\��̓��ʃy�[�W�ւ̃����N���܂܂�Ă���̂����AMozilla Calendar�́u�C�x���g��ҏW�v�E�C���h�E�ɂ���URL�̍��ڂɎ擾�ł��Ȃ��BDESCRIPTION:�s����URL���o���āAURL:�s�Ƃ��ďo�͂���CGI�X�N���v�g�B�f�X�N�g�b�vCGI�Ƃ��ē������悢�B
#!C:/Perl5.8/bin/perl.exe
use strict;
use warnings;
use LWP;
my @header = (
'UserAgent' => "libwww-perl/$LWP::VERSION",
);
my $browser = LWP::UserAgent->new;
use CGI qw(:cgi);
my $ics;
unless(param("ics")){
$ics = "http://weather.livedoor.com/forecast/ical/34/90.ics";
}
print "Content-type: text/calendar; charset=UTF-8\n\n";
my $res = $browser->get($ics,@header);
my $content = $res->content;
my @lines = split(/\n/,$content);
my $line;
foreach $line (@lines){
$line =~ s/^(DESCRIPTION:)(http:\/\/[^ ]+) (.+)$/$1$3\nURL:$2/;
print $line,"\n";
}
���H���pPerl�ō쐬���������J�����_�[�����ǂ���\�z�͈ȑO���玝���Ă���̂����AiCalendar�Ή��Ƃ����̂��ۑ�Ƃ��Ď��g�ނ̂��悢�̂�������Ȃ��B
TSNET�l�^����W�J�B�X�P�W���[�������łȂ��A���ԏ���iCalendar�`���ɕϊ����āA���Ɏg���邩�ׂ���A���낢��l�����B
�Վɂ���ɏЉ���������uiCal MEMO - �֘A�A�v�����v�̃y�[�W����A�J�����_�[���J�T�C�g�̃y�[�W�������āA�ڂ��������̂��ACalendar - �W���ɏ��������J�����_�[ �N���C�A���g �v���W�F�N�g�ł���B
�����AFirefox��Addin���C���X�g�[�������B�G���[���o�邯�ǁA�C���X�g�[���͂���Ă���B�N�����Ă݂�ƁA���Ȃ荂�@�\�Ȃ��̂̂悤���B�J�����_�[���T�[�o�[�Ɍ��J����@�\������B
���̃J�����_�[�ŁA���L����z�M���邱�Ƃ��\���낤�B�z���͂��h������A�v���P�[�V�����ł���B
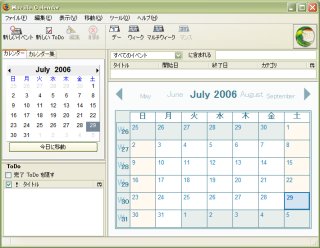 Mozilla Calendar
Mozilla Calendar��2�悤�₭���J���ꂽ�B��1���Atom���[�_�[�̂ق������킹�āA�ŐV�łɂ����BAtom���[�_�[����AAtom�z�M�A�����āA��3���Web���L���̂��̂̍쐬�z�M�ɂ��ď������Ǝv���B����ɏ��̌��ɑk��B
�L���̎��M�́A�����Ŏg���Ă���V�X�e���Ǝ����̃X�N���v�e�B���O�Z�ʂ����コ����h���C�r���O�t�H�[�X�ɂ��Ȃ�Ƃ������A�����łȂ��ƈӖ����Ȃ��Ƃ������B
�킽�������ł��邩�𐳊m�ɔF������K�v������Ƃ͎v���܂���B�l����d���ł̎�v�ȊS�́A�����̂����Ƃ͈قȂ�l�ԂɂȂ邱�Ƃł��B����{�������n�߂��Ƃ����_�ʼn����������������������Ă���Ƃ�����A���̖{�����������E�C���킭�A�Ȃ�čl�����܂����B���̂��������Ƃ�����W�ɂ��Ă͂܂鎖���͐l���ɂ��Ă����Ă͂܂�B�Q�[���́A�ŏI�I�ɂǂ��Ȃ邩������ʌ������Ă݂鉿�l������̂ł��B(�~�V�F���E�t�[�R�[�ق��u���Ȃ̃e�N�m���W�[ �t�[�R�[�E�Z�~�i�[�̋L�^�v�A��g���㕶�� �w�p116�A2�`3�y�[�W�A�u�T �^���E���́E���ȁv)
�X�V���L�ł́A���ȑg�D���}�b�v����^�[�M�����@�ȂǁA���낢���ꖂ��Ă݂Ă͊��ݍӂ����ɒI�グ�Ƃ������ƂɂȂ�B��̂ɂ����āA�_�����R�قǏW�߂Ă�(����C���^�[�l�b�g�̂������ʼn\�ɂȂ���)�A���ۂɃv���O�����ɏ���������Ƃ���܂œ��B���A�������Ӗ��̂�����̂ɂ���̂͑�ϕ~���������B�^�ǂ��Ȃɂ������������Ƃ����Ƃ���ɂ��Ă��A���p�I�ȈӖ������肻�����Ȃ��Ȃ��Ƃ����Ƃ���Ŏ~�܂��Ă��܂��B�����~���������B
�A�L�o�n!�d�]��ԃJ�E�{�[�C�Y�̃P�C�X����������k�ꂽ�u����]�v�搶�Ɓu�A�\�V�A�g�����v�̌��t����H��A���A�u�]�̏���v�A���W���A1997�N2��27����1�ő�1���A166�y�[�W�A3000�~�AISBN4-7856-3101-5�����w���B�{�������ች���ł��Ȃ���Ȃƍl���Ȃ���y�[�W������ƁA�uC�ł���]�̏��V�X�e���v(�ߑ�Ȋw�ЁA1995�N)����ɂ��邱�Ƃ��킩���āA�A�}�]���̃}�[�P�b�g�v���C�X�Ŏ�ɓ��ꂽ�B���́A�v���O������PC9800�p��Turbo C++�ŏ�����Ă��āA�v���O���������^�����t���b�s�[���Y�t����Ă��邱�Ƃ��B�t���b�s�[�͕������ĂȂ��Ə����Ă��邵�A�o���ω��͑��v���낤�B�Ȃ�Ƃ��Ȃ邳�ƍw�������f�����̂����A�����䂪�������̈��@PC9801BX2�͉e���`���Ȃ��B�}�[�P�b�g�v���C�X����̍w���ł��V�i���l�̑N�₩�ȐF�ʂ̖{�̕�����ăt���b�s�[�����o���BDell1(DIMENSION XPS H266)�@��Windows98�ł́A98�̃t���b�s�[���ǂ߂��悤�ȋC���E�E�EVista�@����f�B�X�v���C���͂�����Dell1�@�ɂȂ��ւ��ċN���B�����邨����t���b�s�[�����āA�G�N�X�v���[���̃h���C�u���N���b�N����Ƃ�������\�����ꂽ�B���̓l�b�g���[�N�o�R�ŃR�s�[�Ǝv�������A�Ȃ��Ȃ��l�b�g���[�N���猩���Ȃ��B�f���A���N����Windows 2000�ɐ�ւ��ċN������Ƃ�������Ȃ����āA���C���@��Dell3�ɃR�s�[�����B������[�A���P�u�Â��}�V���͕ۑ�����ׂ��v(^^)v
���̍Ō�̃T���v�����A�u�A�\�V�A�g�����̉��p�v�ƂȂ��Ă��āA�Ȃ�Ɓu���ꔭ�����{�b�g�v�ƃ^�C�g�������Ă���B�������ȁB���Ȃ�A���ꂪ�_���ڂ��낤���ǁE�E�E�E�E�E�ċx�ݍH��̉ۑ肪���܂�������(^^;)
�ŋ߂́A���ɖ{���Â����̂��Ĕł��铮�����o�Ă���悤���B�X�^�j�X���t�E�����̖{��2006�N3���̎������_�@�ɕ�������Ă���B2005�N���������������������\�A�}�����[: �����ܕ��ɕ����Ȃǂ̓����A�����h�b�g�R���Ƃ����d�g�݂��o�Ă��Ă���B
���f�B�A�Ƃ��Ă̖{���C���^�[�l�b�g�𗘗p���ēǎ҃j�[�Y��͂߂Ε����ł��邩������Ȃ��B�������A����Ȃ�ɔ���Ă����Ȃ��̂Ƃ��v������B�l�͑��������Ă���B�Ɠ�����{���a�C�ɜ���Ă����Ȃ��̂��Č����Ă��܂���(^^;)����A������A�{���{���ĂԂ̂Ŏd�����Ȃ����ē�����B�����A�X�����[���݂��b����ˁE�E�E(^^;)���̂����A�C���^�[�l�b�g�̂������Ŗ{�������悤�ɂȂ����Ƃ����b���o�Ă��邩������Ȃ��B�C���^�[�l�b�g�̏�{�̎��v�����N����悤�ɂȂ�Ƃ����b�B�{�̂悤�Ȏ��̓I���f�B�A�����͂�l�b�g���[�N��R���s���[�^��̃f�W�^�����Ǝ����I�ȃ����N�������Ă���B�l�Ԃ�}��Ƃ��Ăł��邪�E�E�E
�Â���q�˂ĐV������m��B�t�[�R�[���������u�|�[�g�E�����C�����̕��@�v�́AGrammaire Générale et Raisonnée�̕����o��(1969�N)�̏����ł���B���̖{�̓f�J���g�̎���10�N���o�߂���1660�N�ɏ�����Ă���B300�N��̕����Ƃ͂������B�`�����X�L�[�́u�f�J���g�h����w�v(1966�N)�́A�|�[�g�E�����C�������@�ɂ��Č������Ă���炵���B���������āA���݂ł��c�_�͐s���Ȃ��悤���B�����A�֘A����d�v�ȃ����N���E���Ă������BThe New York Review of Books�̋L���������炭���j�I�ɂ͏d�v�Ȃ��̂��낤�B���C�R�t���́A�F�m����w�̗������錾��w�҂ł���B���ǁA���́u�f�J���g�h����w�v��ǂ�ł݂Ȃ��ƂȂɂ������Ȃ����B
���A���Q�L�A�g�엘�O��A�u���̂ƈӖ� - �ό`���@���_�ƕ��w�v�A��C�ُ��X�A1974�N9��1������(1972�N5��1������)�A(Roderick A. Jacobs and Peter S. Rosenbaum; Transformation, Style, and Meaning; 1971)�A182�y�[�W�A1500�~�̂܂������ɂ́A����w�̗��j�Ɠ������v�̂悭�܂Ƃ߂��Ă���B�Ƃ����Ă��A1970�N�����̂��Ƃ��낤���A���݂̌���w���ǂ̂悤�ȏɂ���̂��́AWikipedia���Q�Ƃ���̂��悢�̂�������Ȃ��B
���A�u���R�Ȋw�Ƃ��Ă̌���w - �������@�Ƃ͉����v�A��C�ُ��X�A2001�N2��15����1�ŁA275�y�[�W�A2300�~�AISBN4-469-21265-2�ɂ́A���{�̗��_����w�̌���E������܂߂ď�����Ă���A���R�Ȋw�Ƃ��Ă̌���w��W�Ԃ���ȏ�A�`�����X�L�[�̗���ɗ����̂ł���B
web KADOKAWA�l�^�B�u�t�����V�X�E�|���W���v����A�����n���ЁbWeb�~�X�e���[�Y�I�i������ �Ǐ����L�y��R��z(1/3) ��Z�Z�Z�N�l���\�\�W�����E�����v���G�[���������ɂȂ�I�j�̋L���������|����A�u�������v���ĒN�ƌ������āA�������}�Ǝ��l�̉������ȑ�l :: Flash Viewer�̗����ǂ݂Ɏ���B����Flash Viewer�͂悭�ł��Ă���B�ȏ�A�����Ƃ������Ƃ��낾���E�E�E
�������A�����Ƃ��������āA���L���������낢�B�����̂ق��͋����͕ʂɂ��āAFlash Viewer�ł�����Ɠǂ��������ǁA�m���ɓV�˂��낤�ˁB���ς̘b�����L�ɏo�Ă���̂łف[���Ǝv�����̂����AProfile������Ə����ȂB�T�C�g�f�U�C�����܂߂Ĕ[��(^^;)���C�g�m�x�������łȂ��ăw�r�[�m�x���������Ăق����B
����͌����ɂ���āA���p�Ƃ�������q�\���̃����N��H���āA�َ��Ȃ������낢���̂ɂԂ��������ł���BWeb KADOKAWA�̃T�C�g���l�X�ȍH�v�����Ă���B���ڃL�[���[�h�������N�Ɏg���̂͂͂�肩�ȁB�������A�T�C�g�̑S�e���킩��₷��������̂͏��ʂ������Ȃ�ɂ�ē���Ȃ�B�����O�e�[�����ɂ���Ȃ�A�T�C�g�}�b�v�����܂����̂��d�v�ȋC������B�䂪�T�C�g�ł͍X�V���L�C���f�b�N�X�����̃T�C�g�}�b�v�ł͂���̂����B�X�V���L�����X�N���v�g����L�ɂ�������p�o�͂��ł���悤�ɉ������悤�Ƃ��Ă����̂��v���o�����B
���āA�����������Icon�u���ꉞ�����B�����������Icon�u�� - TSNETWiki�ɁA�X�V���L�C���f�b�N�X��Icon�J�e�S���̃����N���쐬���āA�A�N�Z�X�͊m�ۂ���(^^;) �������C���B�����Ԑ�̂��ƂɂȂ肻�������A������A�u�����܂Ƃ߂�Atom�Ŕz�M���邩�ȂƎv���Ă���B���ɍX�V���L�Ƃ��Ă͔z�M����Ă���̂����B
�u�f�X�N�g�b�vCGI�ɂ��f�X�N�g�b�v��Web�̗Z���v��CodeZine�̋L����2����悤�₭�Z�����I����āA���T�ɂ͌��J����邾�낤�B��3��̋L���̊��S�Ȍ��ʂ��͂܂��Ȃ��̂ŁA�����������𑱂��Ă��������Ȃ��BDiary Description Language(Diary Markup Language������)��Microformats��HTML�e���v���[�g�ƌ��ѕt���悤�Ƃ��Ă��邪�A��ѐ�������A���_��ȕ��@�_�Ƃ��āA�܂��܂Ƃ܂肻�����Ȃ��BPerl/Tk�ŃR���\�[������邩�ATeraPad��ł̕ҏW��O��Ƃ��邩�BSJIS��UTF-8���Bjperl��Perl 5.8���B���ǖ�������Ă��邱�Ƃ����������Ȃ��킯������(^^;)�����Ŏg�����ɂ́A����ł܂��������Ȃ��̂���^^;;;��3��͋N���]���̓]������A��P�肵�����Ƃ���B
���C�e�B���O�f�X�N�ɂ͗�ɂ���āA�V���ɍw�������{�Ɩ{�I�����������o�����{���͂��ς܂�Ă���B�X�^�j�X���t�E�����́u�\�����X�̗z�̂��ƂɁv�Ɓu�����̘f���v�AJ�EG�E�o���[�h�́u�R�J�C���E�i�C�g�v���V���ɉ�����Ă���B���̎O���́A�t�[�R�[�́u�t�[�R�[�E�R���N�V���� 3 �����E�\�ہv�ƈꏏ�ɍw���������̂��B���j���ɂ́A�g�{�����́u�����m�[�g�v��V���w�\���̃L�I�X�N�ōw���B�A�}�]������́A����]���A�u�]�̏���v���͂����BSF���������Ɠǂ݉����悤�ȗ]�T�̂���C�����ɂȂ��ƃn�b�s�[�Ȃ̂����E�E�E�`�����X�L�[�́u����Ɛ��_�v�̖|��҂̐�{�ΗY�����A�u���ƂƂ�����v(��g�V����988�A1976�N)�̒��҂��ƋC���t���āA���͂��Ԓ����ĕϐF�����y�[�W�������ēǂB�{�I�̔w�\�������āA�t�����V�X�E�|���W���̂��Ƃ��Ȃ����C�Ɋ|����B�E�E�E�����̂��Ƃɂ��悤�B
�����������Icon�u���B
�� TSfree > Icon�~�j�u�� ���܂�iprocedure�\���j�@�@������
���C�u���������̍ہA������ƗV��ł݂܂����̂ŁA���Q�l�ɁB�e�[�u�������X�g�̗v�f�ŎQ�Ƃ��� procedure�̂R�̗�ł��B
-----^ PROC01.ICN ( date:03-08-29 time:23:38 ) -------------<cut here
####################
# �e�[�u���Q�ƃv���O������
####################
# proc01.icn Rev.1.1 2003/08/29 windy ������ H.S.
# TS Network TSfree
# This file is in the public domain.
procedure main()
T := table() # table����
T["a"] := "AA" ; T["b"] := "BB" ; T["c"] := "CC" # �f�[�^�o�^
# ���f�[�^�P # ���f�[�^�Q
L := [["a","b","c"],["a","d","c"]] # �e�X�g�f�[�^
# procedure �̃e�X�g procedure�������ɂ��āAprocedure���ĂԁB
test(tbl_ref1,T,L)
test(tbl_ref2,T,L)
test(tbl_ref3,T,L)
end
# procedure�̃e�X�g
# arg [1]: procedure
# [2]: table �e�X�g�p table
# [3]: list �e�X�g�p list
procedure test(prcdr,T,L)
write(image(prcdr)) # procedure��
every L1 := !L do { # �e�X�g�p list����f�[�^�����o����
every writes(" ",!L1) # �����o��
writes(" -> ")
L2 := prcdr(T,L1) | ["error"] # ��������
every writes(" ",!L2) # �������ʏ����o��
write()
}
write("----- ----- -----") # �d�ؐ�
end
###################
# Table�Q�Ƃ��A���ʂ� list�A��
###################
# arg [1]: table key -> value
# [2]: list �Q�Ƃ���v�f�� list ��:["abc","def",...]
# value : list table�Q�ƌ��ʂ��i�[ ��:["ABC","DEF",...]
# Usage : L := tbl_ref(T,L)
# args[2]�� �v�f�̂����ꂩ�� table�ɑ��݂��Ȃ���Afail
# �������S�đ������ꍇ�������ʂ�Ԃ��i�����ꂩ�̏������������Ȃ������ꍇ�́A
# �S�̂� fail������B�j�ɂ́A���̕����� procedure�ɂ��邱�ƁB
# �ċA
procedure tbl_ref1(T,L) # �� \x�͑��݂�����̒l�A�Ȃ���� fail
return if *L = 1 then [ \T[ L[1] ] ] #��list�̍Ō�Ȃ�ċA�I��
else [ \T[ L[1] ] ] ||| tbl_ref1(T,L[2:0])
end # list�̘A�� �� ���Ō�łȂ���A�ċA
# every
procedure tbl_ref2(T,L) # <- ���̕ӂ�������₷�����ȁB
L1 := []
every x := !L do put(L1,\T[x]) | fail # �����ꂩ�����ɂȂ���Afail
return L1
end
# while���[�v
procedure tbl_ref3(T,L)
L1 := []
while x := get(L) do put(L1,\T[x]) | fail # �����ꂩ�����ɂȂ���Afail
return L1
end
-----$ PROC01.ICN ( lines:65 words:234 ) -------------------<cut here
�������Ƃ���ȕ��ł��B
-----^ PROC01 ( date:03-08-29 time:23:38 ) -----------------<cut here procedure tbl_ref1 a b c -> AA BB CC a d c -> error ----- ----- ----- procedure tbl_ref2 a b c -> AA BB CC a d c -> error ----- ----- ----- procedure tbl_ref3 a b c -> AA BB CC a d c -> error ----- ----- ----- -----$ PROC01 ( lines:12 words:51 ) ------------------------<cut here
�����������Icon�u���B
�� TSfree �� Icon�~�j�u�� ���܂��i�v���O�����̐����j�@�@������
�����̃v���O����������Ă��A���炭�o�ƁA����������ł��A�u��̉��̂��߂̃v���O�����������H�v�Ƃ��u��̉��̂��߂ɂ������������ɂ��Ă�낤�H�v�ƔY�ނ��Ƃ���R����܂��B���̃n�[�h�f�B�X�N�ɂ́A����Ȑ��̕s���̃v���O���������ӂ�Ă��܂��B
������g�������� procedure�̓��C�u�����[�ɂ��āA�Ɨ��v���O�����̓R�����g���[�����ĕۊǂ������B�Ƃ́A�v���Ă��܂����A�Ȃ��Ȃ��ł��Ȃ��ł��ˁB
����́A��������Ă������Ǝv���܂��B�܂��A���� Icon�̓��������Ă��Ȃ�����������܂��̂ŁA���������Ă݂܂����B
�����������P��
if member(T_dic,s_word) # �����e�[�u���ɂ��邩�`�F�b�N
then put(T_dic[s_word], word) # ����A���� list�ɒlj�
else T_dic[s_word] := [word] # ������Alist�ɓ���ēo�^
�Ƃ�������������܂��B
���� table�ɂ́A�Ⴆ�� key:"abc" �ɑΉ����� �l�Ƃ��āA�\�[�g���ď������������"abc"�ƂȂ�P���o�^���܂��B
���������P��͕�������\��������܂��̂ŁAkey:"abc"�ɑΉ����� �l�� list�Ƃ��āA���̒��� �����lj����Ă����܂��B
�@�@<1>�ŏ��@�l�� "ABC"��lj��@key:"abc" -> ["ABC"]�@�Ƃ������B �@�@�@�@�E�E�Ekey:"abc"��������Ԃ���lj� �@�@<2>���́@�l�� "BcA"��lj��@key:"abc" -> ["ABC","BcA"]�@�Ƃ������B �@�@�@�@�E�E�E���� key:"abc"�ɑΉ�����v�f "ABC"�������čX�� "BcA"��lj�
<1>�̏�ԁikey:"abc"��������ԁj�ŁAkey:"abc"�̒l�� list����������<2gt;�Ɠ��������ŁA�P���lj����悤�� list�ւ̒lj�����������ƁA�Y������ key�������Ƃ������ƂŁA�G���[���������܂��B
�@�@�@�@�@put(T_dic[s_word],word) �́A�G���[�������B �@�@�@�@�@�i�����^�C���G���[�F���݂��Ȃ��l(&null)�ɃA�N�Z�X���悤�Ƃ����B�j �i�⑫�Flist�̒lj������ŁA�lj���� list�������Ƃ����G���[������������������A �@table�� key�������Ƃ����G���[���悾�Ǝv���܂��B�j �@<2>�̏�ԂȂ� key:"abc"�͑��݂��āA�l�ɂ� list ["ABC"]�����݂��Ă��܂��̂ŁA �@�@����list�ւ̒lj������ŒP�ꂪ�lj��ł��܂��B �@�@�@�@�@put(T_dic[s_word],word) �ŁA�P�ꂪ�lj��ł���B <1>�̏�ԁikey:"abc"��������ԁj�Œl�ɒP���lj�����ꍇ�́A �@�@�@�@�@T_dic["abc"] := ["ABC"]�ŁA key:"abc"�̒l�ɗv�f���P�� list���Z�b�g ���Ȃ�������܂���B
����<1>��<2>�����̈Ⴂ�� if..then..else..�ŕ����Ă��܂��B
���āA�ikey:"abc"��������ԁj���`�F�b�N����ɂ́Amember(T_dic,"abc")�łł��܂����A���ۂ� key:"abc"�� table�ɃA�N�Z�X(T_dic["abc"])���ăG���[���������邩�ǂ����ł��`�F�b�N�ł��܂��B
�ł��A�����^�C���G���[����������ƃv���O�������~�܂��Ă��܂��܂��B����ł͍���̂ŁAIcon�ɂ́A���݂��Ȃ�(&null)���ǂ����肷��d�|��������܂��B
\T_dic["abc"] �́A���݂���� key:"abc"�ɑΉ����� T_dic�̒l���A���݂��Ȃ���A&fail�i�G���[��ԁj�ƂȂ�A�����^�C���G���[�ɂ͂Ȃ�܂���B
�����ŁAif member(T_dic,s_word) �́Aif \T_dic[s_word] �Ƃł��܂��̂ŁA
if \T_dic[s_word] # �����e�[�u���ɂ��邩�`�F�b�N
then put(T_dic[s_word], word) # ����A���� list�ɒlj�
else T_dic[s_word] := [word] # ������Alist�ɓ���ēo�^
�ƁA���������܂��B
key:"abc"��������Ԃł́Aput(T_dic["abc"],word)�́A�����^�C���G���[�����܂����Aput(\T_dic[["abc"],word)�́A�����^�C���G���[������ fail���āA�l�́A&fail�ƂȂ�܂��B
�����ŁA�X�ɁAif .. then .. else ..�����A
�@�@ put(\T_dic[s_word],word) | (T_dic[s_word] := [word])
�ƁA�P�s�ɂł��܂��B�@"|"�̍��ӂ� fail�����ꍇ�́A�E�ӂ̎��������āA(T_dic[s_word] := [word])�����s���铮��ƂȂ�Aif .. then .. else .. �Ɠ����̓���ƂȂ�܂��B
�����������Q��
ERR := &null # �����Q�ƃG���[�t���b�O���Z�b�g
Llresult := [] # �����������ʊi�[ list
every (ss := !Lword) & /ERR do { # �ו����������o���āA
# �����Ɏ����Q�ƃG���[���������Ă��Ȃ���A
# �ו������������ɑ��݂��邩�`�F�b�N
if member(T_dic,ss) then put(Llresult,T_dic[ss]) # ���ʃf�[�^�i�[
else ERR := "ERR" # �Q�ƃG���[�t���b�O�Z�b�g
}
�����́A��������������̊e�X�������ɑ��݂��邩�̃`�F�b�N�����Ă��܂��BERR �Ƃ����t���b�O�𗧂ĂĂ���̂��A����������܂���B����́A���� table�Q�Ɨp�̕� procedure�����ƁA
Llresult := tbl_ref(T_dic,Lword) | &null
# ���z�����S�Ď����ɂ���� �����Q�ƌ��ʂ��Z�b�g�B
# �����ꂩ�������ɂȂ���A&null�ŃN���A�B
�ƁA��s�ɂł��܂��B���̂悤�ɁAIcon�ł� "|"���g���ƁA�\�L���R���p�N�g�ɂȂ�ꍇ������܂��B
�������������̑���
���ʓI�� procedure�́A�ʃt�@�C���ɂ��āA���C���t�@�C������ link����悤�ɂ��Ă݂܂����B �܂��ϐ����͎�ύX���Ă���܂��B procedure�����P���ꂪ���ĂȂ������̂ŏC�����܂����B
link�w��́A���̃��C�u�����敪�ɏ]���Ă��܂������A�������ɂȂ�ꍇ���l���Č��̃t�@�C������K�v�ȕ����������������t�@�C�����쐬���A����� link���Ă���܂��B���C�u�������Aicont -c foo.icn �ƁA�\�߃R���p�C�����āA���ԃR�[�h�����Ă����A���̌�ɁAicont decrefp6.icn �ƁA����Ύ��s�t�@�C�����쐬�ł��܂��B
-----^ DICREFP6.ICN ( date:03-08-29 time:23:15 ) -----------<cut here
####################
# �N���X���[�h�p�Y���x��
####################
# dicrefp6.icn Rev.1.1 2003/08/29 windy ������ H.S.
####################
# �N���X���[�h�p�Y���x��
# �E�p�����̃N���X���[�h�p�Y�����܂������āA���̌�w��̏��ڂ̕�����
# �g�ݍ��킹�čŏI�I�ȒP���������B
# �E�ꕔ�����Ă��Ȃ����ڂ�����B
# �E�����t�@�C�����Q�ƁB�p��̒P�ꂪ�Y���b�ƕ��`���̎����t�@�C���B
# �E��F ����Ȃ������� .�ŕ\���ƁAa.ahviy.r �ƂȂ�B
# ���̏ꍇ�̐����i��j�́Aheavy rain �Ƃ����Q�̒P��̑g�����B
# �⑫
# �E�R�}���h���C����������A����������āA�������Q�Ƃ��A�����ɂ���Ώo�́B
# �s�������̂��߂̞B�������B�P��g�����̂��ߕ������B
# �E�����Q�Ǝ��ԒZ�k�̂��߁A������ǂݍ��ގ��ɁA�P����\�[�g�E�������ϊ�
# ���� key�����āAtable�Ɋi�[�B ���� table���Q�ƁB
# �E�����Ǎ����ԒZ�k�̂��߁A���������ɕ������ꂽ�����t�@�C������K�v�Ȏ�����
# �t�@�C���݂̂�Ǎ��ށB
# ���̎���(english.dic)�́A�X�y���`�F�b�N�p�̉p�P�ꂪ���ɕ����́B
# ���̃v���O�����̃e�X�g�ł́ADD SOFT SoundMixSpell�R���|�[�l���g
# Ver 0.3.0 �� �����̎����t�@�C�����g�p�B
# �E�����́A�\�ߕ��������ɁAe01,e02,...���ɕ������Ă����B�i�ʃv���O�����j
# �ETS Network TSabc,TSfree�֘A
# ����
# dicrefp5.icn���C���B�T�u procedure�� link�`���ɂ����B
# ������ �ϐ��� ���������B����: mscombd -> mscomb procedure���̕t�^�~�X
# This file is in the public domain.
link file_x, # �t�@�C���W f_name: ���s�t�@�C�����擾
string_x, # ������W mscomb: �p������d���g����
# expcomb: �p�����z�g����
number_x, # �����W ndivdf: �������̕����a(�~�� �������E�ŏ�����)
stringsx # ������W�iIcon��{���C�u���� BIPL�Ɋ܂܂����́j
# deletec: �p�����當�����폜
# csort: �p������̎������\�[�g
procedure main(args)
# �R�}���h���C�������`�F�b�N�B������� Usage�\��
Usage := " �p�P��(.�̓��C���h�J�[�h) �ő啪���� �ŒZ������"
if *args < 1 then stop(f_name(),Usage)
c_word := args[1] # �R�}���h���C���̉p������
# �����ӂ̎������s����A�E�ӂ̎���I��
ndiv := \args[2] | 1 # �������w�薳���́A�P�i���������j
nmin := \args[3] | *c_word # �ŏ��������w�薳���́A����������
# �R�}���h���C����������A�����p�^�[����
L_lpat := [] # �������p�^�[���i�[ list
every put(L_lpat,n_divdf(*c_word,ndiv,nmin)) # �����p�^�[���i�[
# L_lpat��:[[6],[3,3]]
# �K�v�ȕ������̐����i set�ɓ���āA�_�u�����폜�j
S_pat := set() # �������i�[ set�i�w�蕶�������߁j
every L := !L_lpat do every insert(S_pat,!L) # ��������S�� �i�[
# S_pat��: (6,3)
T_dic := table() # �����i�[ table����
every n_pat := !S_pat do {
# �����t�@�C��������
# ��right�́A�E�����킹��
dic := "e" || right(n_pat,2,"0") # �����t�@�C���� ��:"e06","e03"
# �����t�@�C���I�[�v��
dir := open(dic) | stop(" ",n_pat,"�����p�̎�����������܂���B")
writes(" ",n_pat,"�����p���� ",dic," ��Ǎ����ł��B�J�n:",&clock)
# �����Ǎ�
n_line := 0 # �����s���J�E���^
# �������P�s���ǂݍ���ŁA
while word := read(dir) do {
n_line +:= 1 # �����s���{�P
if n_line % 1000 = 0 then writes(&errout,"*") # �ǂݍ��ݏ\��
# �P����������ϊ����\�[�g�������̂� key�ɂ��Ċi�[�B
# ���ꕶ�����܂ޒP��͓��� key�ɑΉ����� value�� list�̌`���Ŋi�[�B
# table�� key����
# ��������\�[�g
s_word := csort(map(word)) # �������֕ϊ����\�[�g
# ���������ϊ� ��: "ACb" -> "abc"
# ���� table�֊i�[
put(\T_dic[s_word],word) | (T_dic[s_word] := [word])
# �i�[��: key:"abc" -> value: ["ACb","Bca","cab"]
} # end of while word ..
close(dir) # �����t�@�C���N���[�Y
write(&errout)
write(" �I��:",&clock," ",n_line,"�ꂠ��܂����B")
} # end of every n_pat ..
write("\n",c_word," ���A�ő啪���� ",ndiv,"�A�ŏ������� ",nmin,
" �ɂĕ������ă`�F�b�N�B�J�n:",&clock)
# �����Q��
n_comb := 0 # �g�������J�E���^
n_find := 0 # �����ɂ��錏���J�E���^
s_word := deletec(c_word,'.') # �R�}���h���C�������� '.'���폜
n_dot := *c_word -*s_word # '.'�̐�
# ���C���h�J�[�h�������� ��&lcase�͉p������ ����: a-z,aa-zz,aaa-zzz
every s_wild := mscomb(&lcase,n_dot) do { # ���C���h�J�[�h�������A
s_check := s_wild || map(s_word) # �R�}���h���C�������� "."�ȊO�ɑ����A
# ���z�������p�^�[�����o��
every Lpat:= !L_lpat do { # Lpat��: [6]�Ƃ��A[3,3]�Ƃ�
# ���������ʎ��o�� Lword��: ["sunday"]�Ƃ�,["day","sun"]�Ƃ�
every Lword := expcomb(s_check,Lpat) do { # ���z��������������o���āA
n_comb +:= 1 # �`�F�b�N�J�E���^�{�P
if n_comb % 1000 = 0 then writes(&errout,"*") # �`�F�b�N�\��
# �����Q�Ƃ��āA���z���ʂ��S�Ď����ɂ���AL_lout�ɃZ�b�g
L_lout := tbl_ref(T_dic,Lword) | &null # ���z�����S�Ď����ɂ���A
# �����Q�ƌ��ʂ��Z�b�g�B�����ꂩ�������ɂȂ���A&null�ŃN���A�B
# L_lout��: [["Day"],["day"],["Sun","sun","nus"]]
# ���z�����S�Ď����ɂ���A�����o��
if \L_lout then { # L_out�ɒl���Z�b�g����Ă����
n_find +:= 1 # �J�E���^�{�P
writes(&errout,"!") # ���v�\��
# "."���������̕��������o��
writes(s_word) #
if *s_wild >= 1 then writes(" + ",s_wild) # ���C���h�J�[�h����
writes(" ->") #
# �����������ʁi�Q�d list�j�̏����o��
every Lout := L_lout[i := 1 to *L_lout] do {
# �Q�ƌ��ʂ����o����
if i > 1 then writes(" +") # �擪�łȂ���A���}�[�N
every writes(" ",!Lout) # �Q�ƌ��ʂ������o��
} # end of Lout ..
write()
} # end of if \L_lout ..
} # end of every Lword ..
} # end of every Lpat ..
} # end of s_word ..
write(&errout)
write(n_comb," �ʂ�̑g�����̂����A",n_find," �ʂ肪�����ɂ���܂����B",
" �I��:",&clock)
end
###################
# Table�� list�v�f�ŎQ�Ƃ��A���ʂ� list�A��
###################
# arg [1]: table key: "abc" -> value: "ABC"
# [2]: list �Q�Ƃ���v�f�� list ��:["abc","def",...]
# value : list table�Q�ƌ��ʂ��i�[ ��:["ABC","DEF",...]
# Usage : L := tbl_ref(T,L)
# list�� �v�f�̂����ꂩ�� table�ɑ��݂��Ȃ���Afail
procedure tbl_ref(T,L) #
L1 := []
# �� L�̑S�Ă̗v�f�ɂ�
every x := !L do put(L1,\T[x]) | fail # �Q�� table�ɂȂ���� fail������B
return L1
end
# �������S�đ������ꍇ�������ʂ�Ԃ��i�����ꂩ�̏������������Ȃ������ꍇ�́A
# �S�̂� fail������B�j�ɂ́A���̕����� �T�u procedure�ɂ��邱�ƁB
-----$ DICREFP6.ICN ( lines:151 words:589 ) ----------------<cut here
tbl_ref()�́A������܂����̂ŁA���� dicrefp6.icn�ɓ���Ă���܂����A�ėp�I�� procedure�ł��̂ŁA���ʃ��C�u�����Ɉڂ��\��ł��B
������ƒ����ł����A���C�u�������甲�������t�@�C����t���܂��B
-----^ FILE_X.ICN ( date:03-08-29 time:23:17 ) -------------<cut here
####################
# file����W procedure
####################
# file_x.icn Rev.1.1 2003/08/29 windy ������ H.S.
# file_e.icn ���甲���B
# This file is in the public domain.
link string_x # top_get,top_cut
# f_name(file_name) # �g���q�������t�@�C��������(������)
# F_name(file_name) # �g���q�������t�@�C��������(�啶��)
####################
# �g���q�������t�@�C������
####################
# Usage�� file�������R��� �h�����߂̍쐬
# f_name(),F_name() 1997/12/27 windy �啶���A�������Ή��ɕ�����B
# f_name() 1997/08/15 windy exe_name() -> f_name()
# exe_name() 1997/06/02 windy ������ H.S.
# args : �t�@�C����
# value: string
# Icon����u���S Icon��蓹�i�S�j
procedure f_name(file_name)
/file_name := &progname # default�́A���s�t�@�C����
return map(top_get('.',top_cut('\\',file_name)))
end
procedure F_name(file_name)
/file_name := &progname # default�́A���s�t�@�C����
return map(top_get('.',top_cut('\\',file_name)),&lcase,&ucase)
end
-----$ FILE_X.ICN ( lines:31 words:91 ) --------------------<cut here
-----^ NUMBER_X.ICN ( date:03-08-29 time:22:49 ) -----------<cut here
####################
# �����W�⏕ procedure
####################
# number_x.icn Rev1.1 2003/08/29 windy ������ H.S.
# number_e.icn���甲��
# This file is in the public domein.
# n_divd(r,max) # �������̕����i�~���̂݁j genarator
# n_divdf(r,ndiv,nmin) # �������̕����i�~���A�������E�ŏ��������jgenerator
####################
# ���������� generator�i�~���̂݁j
####################
# 5=3+2 ���ɕ�������B�����͍~���̂����B�i�� 5=2+3�͏��O�j
# arg [1]: ��������錳�̐��i�ċA�̏ꍇ�́A�O�̏����̗]��j
# [2]: �ő吔 �i5=2+2+1 �̏ꍇ�ɁA�ŏ��� 2�̎� 3���]�邪�A�ċA���� 3��
# �������n�߂鎞�A3����ł͂Ȃ� 2����n�߂邽�߂̍H�B�~���蓖�B�j
# value : �������ʂ̐��Blist�Ɋi�[
# Usage : every L := n_divd(r) do ...
# Icon�~�j�u���R
# (4) -> [4],[3,1],[2,2],[2,1,1],[1,1,1,1]
procedure n_divd(r,max)
/max := r # �w�薳���́A��������錳�̐����̂���
if r < 1 then fail # �O�̂���
if r = 1 then return [1] # �ċA�I��
# r >= 2 �̏ꍇ
if r > max then rs := max # �����i��苎��j���̍ő吔�̐ݒ�B
else rs := r # ��������鐔�� �ő吔�w��� ��������
every i := rs to 1 by -1 do { # ��L�w�萔�`�P���A���Ɂ|�P���Ȃ���
rr := r -i # �V���ȗ]��
if rr = 0 then suspend [i] # �]�肪�������
# �]�肪����A�ċA����
else if rr > i then suspend [i] ||| n_divd(rr,i) # �]�肪�傫�߂��鎞
else suspend [i] ||| n_divd(rr)
}
end
####################
# ���������� generator�i�t�B���^�[�j
####################
# 5=3+2 ���ɐ�����������B���� procedure�� n_divd���Ăуt�B���^�[���|���Ă���B
# �����p�^�[�����������鎞�ɁA�����������邽�߂Ɏg�p�B
# arg [1]: �������錳�̐�
# [2]: �ő啪����
# [3]: �ŏ���
# value : list
# Usage : every L := n_divdf(r,ndiv,nmin) do ..
# Icon�~�j�u���S
# (4,2,2) -> [4],[2,2]
procedure n_divdf(r,ndiv,nmin)
every L := n_divd(r) do { # r �̕������ʂ����o��
if *L <= ndiv then { # �������`�F�b�N�ilist�̃T�C�Y�`�F�b�N�j
if L[*L] >= nmin then suspend L # �ŏ����`�F�b�N�i�~���ɓ����Ă���̂�
} # �����̗v�f���`�F�b�N�j
}
end
-----$ NUMBER_X.ICN ( lines:60 words:243 ) -----------------<cut here
-----^ STRING_X.ICN ( date:03-08-29 time:23:18 ) -----------<cut here
####################
# ������ procedure
####################
# string_x.icn Rev.1.1 2003/09/29 windy ������ H.S.
# string_e.icn ���甲��
# This file is in the public domain.
link stringsx # BIPL csort
# ssub(s1,s2) # ������̈����Z
# top_cut(c,s) # �擪�폜�i�Œ���v�폜�j
# top_get(c,s) # �擪��o���i�ŒZ��v��o���j
# �g�����W
# exscomb(s,m) # �����̑g���������i���ꕶ���Ή��j generator
# mscomb(s,m) # �����̑g�������� nHm�i�d�����o���j genarator
# ����E�g��������
# new_pos(s) # �����ʒu���� �i���ꕶ���Ή��p�j generator
# �g�������z
# pcomb(s,L) # �����̑g������ ���z generator
# expcomb(s,L,s_ref) # �����̑g������ ���z�i���ꕶ�� ���ꐔ�jgenerator
####################
# ������̈����Z
####################
# arg [1]: string ��폜������
# [2]: string �폜������
# value : string ���ʕ�����
# ������ s1�̐擪����A������ s2�̕������폜�B�P�F�P�ō폜�B
# ("abcabc","abd") -> "cabc" s2�ɂ��镶���ŁAs1�ɖ��������͖��������B
# Icon�~�j�u���X
procedure ssub(s1,s2)
every c := !s2 do { # s2����P���������o����
ss := "" # ��L�������폜��̕�����̊i�[�G���A
s1 ? { # s1�𑖍��ΏۂƂ��āA
if ss ||:= tab(upto(c)) then { # ������������� �������̕������
# ss�ɑ�������
move(1) # �P�����X�L�b�v
ss ||:= tab(0) # �c��̕�����𑫂�����
s1 := ss # s1�X�V
}
}
}
return s1
end
####################
# ������� �擪������蕶���܂ł̕��� ����苎��B�Œ���������苎��B
####################
# arg : cset
# value : string
# Usage : top_cut(c,s)
# Icon����u���Q�i�T�j
procedure top_cut(c,s)
/s := &subject # s�̎w�肪�Ȃ���� &subject
/c := ' \t' # c�̎w�肪�Ȃ���� space�� tab
s ? { # s�𑖍��ΏۂƂ���B
while tab(upto(c)) do tab(many(c)) # c�����������A�����ʒu��
# ���̕����̌�Ɉړ��B
return tab(0) # �c��̕������Ԃ��B
}
end
####################
# ������� �擪������蕶���܂ł̕��� ��B�ŒZ������B
####################
# arg : cset
# value : string
# Usage : top_get(c,s)
# Icon����u���Q�i�T�j
procedure top_get(c,s)
/s := &subject # s�̎w�肪�Ȃ���� &subject
/c := ' \t' # c�̎w�肪�Ȃ���� space�� tab
s ? { # s�𑖍��ΏۂƂ���B
return tab(upto(c) | 0) # c�܂ő����ʒu���ړ������̊Ԃ�
} # �������Ԃ��Bc���݂���Ȃ�
# ��A�����܂ŕԂ��B
end
####################
# �g�����W
####################
####################
# ������̑g���� ���ꕶ���w������� n������ m��I�ԑg���� generator
####################
# string�̑g�ݍ��킹
# n����Am��I�ԁB�i���ꕶ���w��Ή��j
# arg: [1]: s: string
# [2]: m: integer
# value: string
# Usage: every ss := exscomb(s,m) do ...
# Icon����u���R�i�P�P�jscomb()�ꕶ���w��Ή��Ɋg���B�@Icon�~�j�u���X
# ("abca",3) -> "aab","aac","abc"
procedure exscomb(s,m)
initial {
/m := *s # �f�t�H���g nCn (n = m = *s)
s := csort(s) # ��������\�[�g����B(BIPL:strings.icn)
}
if m = 0 then return "" # m�����J�E���^�[�Ɏg���B
# 0�ɂɂȂ�����A�ċA�I���B
suspend s[i := new_pos(s)] || exscomb(s[i+1 : 0], m -1)
#�� �P�����I�� �� �����O�őI�����ȍ~ ���w�蕶������
# �b �̕�����ɑ����� �������}��
# �b �������s���B �邽�߂̃J�E
# ������̘A�� ���^�[
end
#############################
# ������� nHm n������A�d������ m��I�ԑg���� generator
#############################
# n���� �d�����āAm��I�ԁB
# arg [1]: string
# [2]: integer
# value : string
# Usage : every ss := mscomb(s,m) do ..
# ("abc",2) -> "aa","ab","ac","bb","bc","cc"
procedure mscomb(s,m)
initial {
/m := *s
}
if m =0 then return "" # �ċA�I��
every i := 1 to *s do { # �P�`�����܂�
# �� i�Ԗڂ̕��������o����
suspend s[i] || mscomb(s[i:0],m-1)
} # �����̕����ȍ~�̕����Ƒg�ݍ��킹��B
end
####################
# ����E�g��������
####################
####################
# �\�[�g���ꂽ�p������ s�̍��͂�����A���ɕ����ʒu���o�͂��� generator�B
####################
# ��O�̕����Ɠ���Ȃ�X�L�b�v����B
# arg [1]: s string
# value: integer
# Usage: every i := new_pos(s) do ...
procedure new_pos(s)
ss := "" # ��O�̕������L�����Ă����ϐ�
every i := 1 to *s do {
if ss ~== s[i] then { # ��O�̕����ƈ���Ă�����
ss := s[i] # ��O�������X�V
suspend i # i ��Ԃ��B
}
}
end
####################
# ���z�̑g�����i���ꕶ���w��E���ꕶ�����w��Ή��j
####################
# arg [1]: string ���z����p������F���z�p�^�[���̃g�[�^���ɍ����Ă邱�ƁB
# [2]: list ���z�p�^�[���i�~���� list�j
# [3]: string �O�̕�����i���ꕶ�����w��̏ꍇ�ɍ~����I�Ԃ��߂̎Q�Ɨp�j
# value : list �������ꂽ������i�~���̑g�����̂݁j�i list�Ɋi�[�j
# Usage : every LL := expcomb(s,L) do ..
# ("abc", [2,1]) -> ["ab","c"], ["ac","b"], ["bc","a"]
# ("abcd",[2,2]) -> ["ab","cd"],["ac","bd"],["ad","bc"]
# ���z�p�^�[�������ɁAnumber_e.icn�� n_div(),n_divd(),n_divdf()���g���邩���B
# Icon�~�j�u���X
procedure expcomb(s,L,s_ref)
/s_ref := "" # �w��Ȃ���A��
s := csort(s) # ������\�[�g
if *L = 1 then { # �p�^�[���v�f�̍Ō�ŁA
if L[1] = *s_ref then { # �O��ƕ������������ŁA
if s << s_ref then return &fail # �������őO�Ȃ�A���s������B
}
return [s] # ���ŁA������A�������Ԃ��B
} # ������ɂɂ��Ă��A�ċA�I���B
# �P�����̕�����w��Ȃ�A��́A���ɂP�������� list�ɓ���邾��
if L[1] = 1 then { # �P�����̕�����w��Ȃ�A
# ��́A���ɂP�������� list�ɓ���邾��
return [s[1]] ||| expcomb(s[2:0], L[2:0])
} # ���擪���� ���c�蕶���� ���c��̃��X�g
# �Q�����ȏ�̕�����w��Ȃ�A
every ss := exscomb(s,L[1]) do { # �����̑g�����������
if *ss = *s_ref then { # �O��ƕ������������Ȃ�A
if ss << s_ref then return &fail # �~���Ŗ�����A���s������B
} # ���Q�Ɨp������
suspend [ss] ||| expcomb(ssub(s,ss),L[2:0],ss)
} # ���g�������� ���c�蕶���� ���c��̃��X�g
end
-----$ STRING_X.ICN ( lines:198 words:657 ) ----------------<cut here
-----^ STRINGSX.ICN ( date:03-08-29 time:23:13 ) -----------<cut here
####################
# ������ procedure BIPL(Icon��{���C�u�����[)���
####################
# stringsx.icn Rev.1.1 2003/08/29 windy ������ H.S.
# BIPL strings.icn ���甲��
# This file is in the public domain.
####################
# strings.icn�Ɋ܂܂�� �����̃\�[�g procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ���[�J���ϐ��錾�i�����Ă��ǂ��j
s1 := "" # �����l�N���A
every c := !cset(s) do # ������ cset(�����W��)�֕ϊ������Ɏ��o���B
every find(c, s) do # ���o���������ŁA������������������A
s1 ||:= c # ������x�ɁA������ s1�ɑ������ށB
return s1
end
# cset���� !�ŗv�f�����o�����ɂ́A�A���t�@�x�b�g���Ɏ��o����B
####################
# strings.icn�Ɋ܂܂�� �����̍폜 procedure
####################
procedure deletec(s, c) #: delete characters
local result # ���[�J���錾�i�����Ă��ǂ��j
result := "" # �폜��̕�����i�[�G���A
s ? { # s�𑖍��ΏۂƂ��āA
while result ||:= tab(upto(c)) do # c�������閘�̕�����𑫂������
tab(many(c)) # c�ȊO�̕����܂ŃX�L�b�v
return result ||:= tab(0) # �]��̕����𑫂�����
}
end
-----$ STRINGSX.ICN ( lines:32 words:117 ) -----------------<cut here
�����������Icon�u���B
�� TSfree �� Icon�~�j�u���P�O�i���������Ŏ����Q�Ɓj�@�@������
���āA�܂Ƃ߂ŁA�t���X�y�b�N�̃v���O�����ɂ܂Ƃ߂܂��傤�B
�Ƃ����Ƃ���ŁA�܂Ƃ߂�Ǝ��̂悤�ɂȂ�܂��B
���A�����Ē����₷���悤�ɁA�S�Ă� procedure���P�̃t�@�C���ɂ��Ă��܂����A�T�u procedure���A�ʂ̃t�@�C���ɂ��āAmain�t�@�C������ link����悤�ɂ��ł��܂��B
-----^ DICREFP5.ICN ( date:03-08-25 time:20:05 ) -----------<cut here
####################
# ������̑g�����ŁA�����Q�ƁB�B�������B���������B���C���h�J�[�h���Ή�
####################
# dicrefp5.icn Rev.1.0 2003/08/25 windy ������ H.S.
####################
# Usage dicrefp5 �p������(.�̓��C���h�J�[�h)
# ���������ɕ������ꂽ�����t�@�C�����g�p�B english.dic���B
# english.dic�́A�X�y���`�F�b�N�p�̉p�P�ꂪ���ɕ����́B
# ���̃v���O�����̃e�X�g�ł́ADD SOFT SoundMixSpell�R���|�[�l���g
# Ver 0.3.0 �� �����̎����t�@�C�����g�p�B
# This file is in the public domain.
procedure main(args)
# �R�}���h���C�������`�F�b�N�B������� Usage�\��
if *args < 1 then stop("dicrefp5 �p�P��(.�̓��C���h�J�[�h)",
" �ő啪���� �ŏ�������")
# �R�}���h���C���̈�������A������Ǎ�
c_word := args[1] # �R�}���h���C���̉p������
ndiv := \args[2] | 1 # �������w�薳���́A�P�i���������j
nmin := \args[3] | *c_word # �ŏ��������w�薳���́A����������
# �����p�^�[���i�[
L_lpat := [] # �������p�^�[���i�[ list
every put(L_lpat,n_divdf(*c_word,ndiv,nmin)) # �����p�^�[���i�[
# �K�v�ȕ������ɑΉ����鎫���̓Ǎ�
S_pat := set() # �������i�[ set�i�w�蕶���������Ǎ��̂��߁j
every L := !L_lpat do every insert(S_pat,!L) # ��������S�� �i�[
T_dic := table() # �����i�[ table����
every n_pat := !S_pat do {
# ���E�����킹��
dic := "e" || right(n_pat,2,"0") # �����t�@�C����
dir := open(dic) | stop(" ",n_pat,"�����p�̎�����������܂���B")
# �����t�@�C���I�[�v��
writes(" ",n_pat,"�����p���� ",dic," ��Ǎ����ł��B�J�n:",&clock)
n := 0 # �����s���J�E���^
while word := read(dir) do { # �������P�s���ǂݍ���ŁA
n +:= 1
if n % 1000 = 0 then writes(&errout,"*") # �ǂݍ��ݏ\��
# �P����������ϊ����\�[�g�������̂��C���f�b�N�X�ɂ��Ċi�[
# ���ꕶ�����܂ޒP��͓����C���f�b�N�X�� list�̗v�f�Ƃ��Ċi�[�����B
# ��������\�[�g
s_word := csort(map(word)) # �������֕ϊ����A�\�[�g����
# ���������ϊ�
if member(T_dic,s_word) # �����e�[�u���ɂ��邩�`�F�b�N
then put(T_dic[s_word], word) # ����A���� list�ɒlj�
else T_dic[s_word] := [word] # ������Alist�ɓ���ēo�^
}
close(dir) # �����t�@�C���N���[�Y
write(&errout)
write(" �I��:",&clock," ",n,"�ꂠ��܂����B")
}
write("\n",c_word," ���A�ő啪���� ",ndiv,"�A�ŏ������� ",nmin,
" �ɂĕ������ă`�F�b�N�B�J�n:",&clock)
# �����Q��
n_comb := 0 # �g�������J�E���^
n_find := 0 # �����ɂ��錏���J�E���^
s_word := deletec(c_word,'.') # �R�}���h���C�������� '.'���폜
n_dot := *c_word -*s_word # '.'�̐�
# ���p������
every s_wild := mscombd(string(&lcase),n_dot) do { # ���C���h�J�[�h�������A
s_check := s_wild || map(s_word) # �R�}���h���C�������� '.'�ȊO�ɑ����A
every Lpat:= !L_lpat do { # ���z�������p�^�[�����珇�����o���āA
every Lword := expcomb(s_check,Lpat) do { # ���z���ʂ��������o���āA
n_comb +:= 1 # �`�F�b�N�J�E���^�{�P
if n_comb % 1000 = 0 then writes(&errout,"*") # �`�F�b�N�\��
ERR := &null # �����Q�ƃG���[�t���b�O���Z�b�g
Llresult := [] # �����������ʊi�[ list
every (ss := !Lword) & /ERR do { # �ו����������o���āA
# �����Ɏ����Q�ƃG���[���������Ă��Ȃ���A
# �ו������������ɑ��݂��邩�`�F�b�N
if member(T_dic,ss) then put(Llresult,T_dic[ss]) # ���ʃf�[�^�i�[
else ERR := "ERR" # �Q�ƃG���[�t���b�O�Z�b�g
}
# �ו������S�Ď����ɂ���A�����o��
if /ERR then { # �G���[�t���b�O�������Ă��Ȃ����
n_find +:= 1 # �J�E���^�{�P
writes(&errout,"!") # ���v�\��
writes(s_word) #
if *s_wild >= 1 then writes(" + ",s_wild)
writes(" ->") #
nn := 0 # �ו������Q�J�E���^
every Lstr := !Llresult do { # �ו������Q�����o����
nn +:= 1 # �J�E���^�{�P
if nn > 1 then writes(" +") # �擪�łȂ���A���}�[�N
every writes(" ",!Lstr) # �����Q�������o��
}
write()
}
}
}
}
write(&errout)
write(n_comb," �ʂ�̑g�����̂����A",n_find," �ʂ肪�����ɂ���܂����B",
" �I��:",&clock)
end
####################
# ���z�̑g����
####################
# arg [1]: string ���z����p������F���z�p�^�[���̃g�[�^���ɍ����Ă邱�ƁB
# [2]: list ���z�p�^�[���i�~���� list�j
# [3]: string �O�̕�����i���ꕶ�����w��̏ꍇ�ɍ~���̂��̂����I�Ԃ��߂́j
# value : list �������ꂽ������i list�Ɋi�[�j
# Usage : every LL := expcomb(s,L) do ..
# ("abc", [2,1]) -> ["ab","c"], ["ac","b"], ["bc","a"]
# ("abcd",[2,2]) -> ["ab","cd"],["ac","bd"],["ad","bc"]
procedure expcomb(s,L,s_ref)
/s_ref := "" # �w��Ȃ���A��
s := csort(s) # ������\�[�g
if *L = 1 then { # �p�^�[���v�f�̍Ō�ŁA
if L[1] = *s_ref then { # �O��ƕ������������ŁA
if s << s_ref then return &fail # �������őO�Ȃ�A���s������B
}
return [s] # ���ŁA������A�������Ԃ��B
}
# �P�����̕�����w��Ȃ�A��́A���ɂP�������� list�ɓ���邾��
if L[1] = 1 then { # �P�����̕�����w��Ȃ�A
# ��́A���ɂP�������� list�ɓ���邾��
return [s[1]] ||| expcomb(s[2:0], L[2:0])
} # ���擪���� ���c�蕶���� ���c��̃��X�g
# �Q�����ȏ�̕�����w��Ȃ�A
every ss := exscomb(s,L[1]) do { # �����̑g�����������
if *ss = *s_ref then { # �O��ƕ������������ŁA
if ss << s_ref then return &fail # �������őO�Ȃ�A���s������B
} # ���Q�Ɨp������
suspend [ss] ||| expcomb(ssub(s,ss),L[2:0],ss)
} # ���g�������� ���c�蕶���� ���c��̃��X�g
end
####################
# ������̈����Z
####################
# arg [1]: string ��폜������
# [2]: string �폜������
# value : string ���ʕ�����
# ������ s1�̐擪����A������ s2�̕������폜�B�P�F�P�ō폜�B
# ("abcabc","abd") -> "cabc" s2�ɂ��镶���ŁAs1�ɖ��������͖��������B
procedure ssub(s1,s2)
every c := !s2 do { # s2����P���������o����
ss := "" # ��L�������폜��̕�����̊i�[�G���A
s1 ? { # s1�𑖍��ΏۂƂ��āA
if ss ||:= tab(upto(c)) then { # ������������� �������̕������
# ss�ɑ�������
move(1) # �P�����X�L�b�v
ss ||:= tab(0) # �c��̕�����𑫂�����
s1 := ss # s1�X�V
}
}
}
return s1
end
####################
# ������� nCm (n = *s) n������Am������I�ԁB generator
####################
# string�̑g�ݍ��킹
# nCm (n = *s) n�̂��̂���Am��I�ԁB
# arg: [1]: s: string
# [2]: m: integer
# value: string
# Usage: every ss := exscomb(s,m) do ...
# Icon����u���R�i�P�P�jscomb()�ꕶ���w��Ή��Ɋg��
procedure exscomb(s,m)
initial {
s := csort(s) # ��������\�[�g����B(BIPL:strings.icn)
/m := *s # �f�t�H���g nCn (n = m = *s)
}
if m = 0 then return "" # m�����J�E���^�[�Ɏg���B
# �O�Ȃ�����A�����őł��~�߁B
suspend s[i := new_pos(s)] || exscomb(s[i+1 : 0], m -1)
#�� �P�����I�� �� �����O�őI�����ȍ~ ���w�蕶������
# �b �̕�����ɑ����� �������}��
# �b �������s���B �邽�߂̃J�E
# ������̘A�� ���^�[
end
####################
# �\�[�g���ꂽ������ s�̍��͂�����A���ɕ����ʒu���o�͂��� generator�B
####################
# ��O�̕����Ɠ���Ȃ�X�L�b�v����B
# arg [1]: s string
# value: integer
# Usage: every i := new_pos(s) do ...
procedure new_pos(s)
ss := "" # ��O�̕������L�����Ă����ϐ�
every i := 1 to *s do {
if ss ~== s[i] then { # ��O�̕����ƈ���Ă�����
ss := s[i] # ��O�������X�V
suspend i # i ��Ԃ��B
}
}
end
#############################
# ������d�����āA���A�~���̂��̂����o�� generator
#############################
# arg [1]: string
# [2]: integer
# value : string
# Usage : every ss := mscombd(s,n) do ..
# ("abc",2) -> "aa","ab","ac","bb","bc","cc"
procedure mscombd(s,n)
if n =0 then return "" # �ċA�I��
every i := 1 to *s do { # �P�`�����܂�
# �� i�Ԗڂ̕��������o����
suspend s[i] || mscombd(s[i:0],n-1)
} # ������ȍ~�̕����Ƒg�ݍ��킹��
end
####################
# ���������� generator
####################
# 5=3+2 ���ɐ�����������B���� procedure�� n_divd���Ăуt�B���^�[���|���Ă���B
# �����p�^�[�����������鎞�ɁA�����������邽�߂Ɏg�p�B
# arg [1]: �������錳�̐�
# [2]: �ő啪����
# [3]: �ŏ���
# value : list
procedure n_divdf(r,ndiv,nmin)
every L := n_divd(r) do { # r �̕������ʂ����o��
if *L <= ndiv then { # �������`�F�b�N�ilist�̃T�C�Y�`�F�b�N�j
if L[*L] >= nmin then suspend L # �ŏ����`�F�b�N�i�~���ɓ����Ă���̂�
} # �����̗v�f���`�F�b�N�j
}
end
####################
# ���������� generator
####################
# 5=3+2 ���ɕ�������B�����͍~���̂����B�i�� 5=2+3�͏��O�j
# arg [1]: ��������錳�̐��i�ċA�̏ꍇ�́A�O�̏����̗]��j
# [2]: �ő吔 �i5=2+2+1 �̏ꍇ�ɁA�ŏ��� 2�̎� 3���]�邪�A�ċA���� 3��
# �������n�߂鎞�A3����ł͂Ȃ� 2����n�߂邽�߂̍H�B�~���蓖�B�j
# value : �������ʂ̐��Blist�Ɋi�[
# Usage : every L := n_divd(r) do ...
procedure n_divd(r,max)
/max := r # �w�薳���́A��������錳�̐����̂���
if r < 1 then fail # �O�̂���
if r = 1 then return [1] # �ċA�I��
# r >= 2 �̏ꍇ
if r > max then rs := max # �����i��苎��j���̍ő吔�̐ݒ�B
else rs := r # ��������鐔�� �ő吔�w��� ��������
every i := rs to 1 by -1 do { # ��L�w�萔�`�P���A���Ɂ|�P���Ȃ���
rr := r -i # �V���ȗ]��
if rr = 0 then suspend [i] # �]�肪�������
# �]�肪����A�ċA����
else if rr > i then suspend [i] ||| n_divd(rr,i) # �]�肪�傫�߂��鎞
else suspend [i] ||| n_divd(rr)
}
end
# BIPL(Icon��{���C�u�����[)���
####################
# strings.icn�Ɋ܂܂�� �����̃\�[�g procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ���[�J���ϐ��錾�i�����Ă��ǂ��j
s1 := "" # �����l�N���A
every c := !cset(s) do # ������ cset(�����W��)�֕ϊ������Ɏ��o���B
every find(c, s) do # ���o���������ŁA������������������A
s1 ||:= c # ������x�ɁA������ s1�ɑ������ށB
return s1
end
# cset���� !�ŗv�f�����o�����ɂ́A�A���t�@�x�b�g���Ɏ��o����B
####################
# strings.icn�Ɋ܂܂�� �����̍폜 procedure
####################
procedure deletec(s, c) #: delete characters
local result # ���[�J���錾�i�����Ă��ǂ��j
result := "" # �폜��̕�����i�[�G���A
s ? { # s�𑖍��ΏۂƂ��āA
while result ||:= tab(upto(c)) do # c�������閘�̕�����𑫂������
tab(many(c)) # c�ȊO�̕����܂ŃX�L�b�v
return result ||:= tab(0) # �]��̕����𑫂�����
}
end
-----$ DICREFP5.ICN ( lines:290 words:1124 ) ---------------<cut here
�i�NjL�@�R�����g�� �u���C���h�J�[�h���Ή��v�́A�폜�R��ł��B���C���h�J�[�h�ɑΉ����Ă��܂��B�j
�B�������w�肪�����ꍇ�̗�����P�Bdicrefp5 heavyrain 2 4 >kkk �Ƃ��܂��ƁA���̂悤�ɂȂ�܂��B
-----^ KKK ( date:03-08-25 time:20:56 ) --------------------<cut here 5�����p���� e05 ��Ǎ����ł��B�J�n:20:56:50 �I��:20:56:50 12483�ꂠ��܂����B 4�����p���� e04 ��Ǎ����ł��B�J�n:20:56:50 �I��:20:56:51 5881�ꂠ��܂����B 9�����p���� e09 ��Ǎ����ł��B�J�n:20:56:51 �I��:20:56:55 38640�ꂠ��܂����B heavyrain ���A�ő啪���� 2�A�ŏ������� 4 �ɂĕ������ă`�F�b�N�B�J�n:20:56:55 heavyrain -> rayah + nevi vein vine heavyrain -> Aryan + hive heavyrain -> hiera + navy Navy heavyrain -> haven + airy Iyar heavyrain -> hyena + riva vair heavyrain -> haver + ayin heavyrain -> hayer + vain vina heavyrain -> heavy Yahve + airn Arni Iran rain rani heavyrain -> raven + hiya Yahi heavyrain -> hairy + Evan nave vane vena heavyrain -> Invar invar ravin Vanir + yeah heavyrain -> rainy + have heavyrain -> hiver + Yana heavyrain -> nervi riven viner + ayah heavyrain -> veiny + haar 92 �ʂ�̑g�����̂����A15 �ʂ肪�����ɂ���܂����B �I��:20:56:55 -----$ KKK ( lines:21 words:119 ) --------------------------<cut here
���ĕs���������Q����P�[�X���ƁAdicrefp5 a.ahviy.r 2 4 >lll �Ƃ��܂��ƁA����Ȍ��ʂɂȂ�܂��B
-----^ LLL ( date:03-08-25 time:20:59 ) --------------------<cut here 5�����p���� e05 ��Ǎ����ł��B�J�n:20:59:10 �I��:20:59:10 12483�ꂠ��܂����B 4�����p���� e04 ��Ǎ����ł��B�J�n:20:59:10 �I��:20:59:11 5881�ꂠ��܂����B 9�����p���� e09 ��Ǎ����ł��B�J�n:20:59:11 �I��:20:59:15 38640�ꂠ��܂����B a.ahviy.r ���A�ő啪���� 2�A�ŏ������� 4 �ɂĕ������ă`�F�b�N�B�J�n:20:59:15 aahviyr + aa -> Avahi + raya aahviyr + aa -> varia + ayah aahviyr + ab -> Bahai + vary aahviyr + ab -> brava + hiya Yahi aahviyr + ab -> Avahi + bray Brya �i�����j aahviyr + en -> hayer + vain vina aahviyr + en -> heavy Yahve + airn Arni Iran rain rani aahviyr + en -> raven + hiya Yahi aahviyr + en -> hairy + Evan nave vane vena aahviyr + en -> Invar invar ravin Vanir + yeah �i�����j aahviyr + uy -> hairy + Vayu aahviyr + vx -> hyrax + viva aahviyr + wy -> hairy + wavy aahviyr + xx -> rayah + xxiv XXIV xxvi XXVI aahviyr + xz -> varix + hazy 27602 �ʂ�̑g�����̂����A943 �ʂ肪�����ɂ���܂����B �I��:20:59:20 -----$ LLL ( lines:949 words:7467 ) ------------------------<cut here
���\�A���v������̂�����܂��̂ŁA�r���𗪂��Ă���܂��B�X�S�R�����ƌ��ʂ̃`�F�b�N�Ɏ��Ԃ������肻���ł��B
������ƒ������܂������A���傤�ǂP�O��ڂƂ������ƂŁAIcon�~�j�u���́A�I���ɂ��܂��B�i�錾���Ă����Ȃ��ƁA�����܂����������Ȃ̂ŁB�j�����ɂ������������܂��āA�L���������܂��B
�����������Icon�u���B
�� TSfree �� Icon�~�j�u���X�i���z�g�����j�@�@������
������ŁA�����Q�Ƃ�����Ƃ��ɁA�����̑g��������낤�Ǝv���̂ł����A�Ⴆ��
-----^ PCOMB1.ICN ( date:03-08-25 time:20:43 ) -------------<cut here
####################
# �����z�v���O�����̏K��P
####################
# pcomb1.icn Rev.1.0 2003/08/25 windy ������ H.S.
####################
# This file is in the public domain.
procedure main()
L := [[4],[3,1],[2,2],[2,1,1],[1,1,1,1]] # �����z�p�^�[���i�������j
s := "abcd" # �e�X�g������
write(s)
every LL := !L do { # ���z�������p�^�[�����珇�����o���āA
write("---") # �\���p
every LLL := pcomb(s,LL) do { # ���z���ʂ��������o���āA
writes(" ->") # �\���p
every writes(" ",!LLL) # �o�͂���B
write()
}
}
end
####################
# ���z�̑g����
####################
# arg [1]: string ���z����p������F���z�p�^�[���̃g�[�^���ɍ����Ă邱�ƁB
# [2]: list ���z�p�^�[���i�~���� list�j
# value : list �������ꂽ������
# Usage : every LL := pcomb(s,L) do ..
# ("abc",[2,1]) -> ["ab","c"],["ac","b"],["bc","a"]
# ���ꕪ�z������������ꍇ�́A���ʂ�������B
# �@��F("abcd",[2,2])�̏ꍇ�ɁA["ab","cd"] �� ["cd","ab"]�̗������o��B
procedure pcomb(s,L)
if *L = 1 then return [s] # �ċA�I��
if L[1] = 1 then { # ��́A���ɂP�������� list�ɓ���邾��
return [s[1]] ||| pcomb(s[2:0], L[2:0]) #
} # ���擪���� ���c�蕶���� ���c��̃��X�g
# �Q�����ȏ�̎w��Ȃ�A
every ss := scomb(s,L[1]) do { # �����̑g�����������
suspend [ss] ||| pcomb(ssub(s,ss),L[2:0]) # �c��̕����̂��ߍċA
} # ���g�������� ���c�蕶���� ���c��̃��X�g
end
####################
# ������̈����Z
####################
# arg [1]: string ��폜������
# [2]: string �폜������
# value : string ���ʕ�����
# ������ s1�̐擪����A������ s2�̕������폜�B�P�F�P�ō폜�B
# ("abcabc","abd") -> "cabc" s1�ɖ��������͖��������B
procedure ssub(s1,s2)
every c := !s2 do { # s2����P���������o����
ss := "" # ��L�������폜��̕�����̊i�[�G���A
s1 ? { # s1�𑖍��ΏۂƂ��āA
if ss ||:= tab(upto(c)) then { # ������������� �������̕������
# ss�ɑ�������
move(1) # �P�����X�L�b�v
ss ||:= tab(0) # �c��̕�����𑫂�����
s1 := ss # s1�X�V
}
}
}
return s1
end
####################
# ������� nCm (n = *s) n������Am������I�ԁB generator
####################
# 1998/04/16 windy ���̕ύX comb -> scomb (BIPL�ƃ_�u���̂Łj
# string�̑g�ݍ��킹
# nCm (n = *s) n�̂��̂���Am��I�ԁB
# arg: [1]: s: string
# [2]: m: integer
# value: string
# Usage: every ss := scomb(s,m) do ...
# Icon����u���R�i�P�P�j
procedure scomb(s,m)
/m := *s # �f�t�H���g nCn (n = m = *s)
if m = 0 then return "" # m�����J�E���^�[�Ɏg���B
# �O�Ȃ�����A�����őł��~�߁B
suspend s[i := 1 to *s] || scomb(s[i+1 : 0], m -1)
#�� �P�����I�� �� �����O�őI�����ȍ~ ���w�蕶������
# �b �̕�����ɑ����� �������}��
# �b �������s���B �邽�߂̃J�E
# ������̘A�� ���^�[
end
-----$ PCOMB1.ICN ( lines:88 words:334 ) -------------------<cut here
pcomb1 > iii �Ƃ���ƁA�����Ȃ�܂��B
-----^ III ( date:03-08-25 time:20:45 ) --------------------<cut here abcd --- -> abcd --- -> abc d -> abd c -> acd b -> bcd a --- -> ab cd -> ac bd -> ad bc -> bc ad -> bd ac -> cd ab --- -> ab c d -> ac b d -> ad b c -> bc a d -> bd a c -> cd a b --- -> a b c d -----$ III ( lines:24 words:67 ) ---------------------------<cut here
���ʂ����Ă݂܂��ƁA������������A�����Ď��o���i�Q�������Q��j���ɁA["ab","cd"] �� ["cd","ab"]���A�����łĂ��܂��B����́A�Е������ŗǂ��̂ł��B�@�悭����ƁA�s�v�ȃP�[�X�́A���ʂ̕��т��A�~���ɂȂ��Ă��Ȃ��P�[�X�݂����ł��B�����ŁA�~���̑g���킹�������o���悤�ɁA�C�����Ă݂܂����B������̔�r���ŁA<< �Ƃ����L�����o�Ă��܂����A����͕����������Ő悩�ォ�̔�r���s�����̂ł��B������g������ scomb���A���ꕶ���w��ɑΉ����Ă��܂���ł����̂ŁA�Ή�����exscomb�����܂����B
-----^ PCOMB2.ICN ( date:03-08-25 time:20:44 ) -------------<cut here
####################
# �����z�v���O�����̏K��Q
####################
# pcomb2.icn Rev.1.0 2003/08/25 windy ������ H.S.
####################
# This file is in the public domain.
procedure main()
L := [[4],[3,1],[2,2],[2,1,1],[1,1,1,1]] # �����z�p�^�[���i�������j
s := "abcd" # �e�X�g������
write(s)
every LL := !L do { # ���z�������p�^�[�����珇�����o���āA
write("---") # �\���p
every LLL := expcomb(s,LL) do { # ���z���ʂ��������o���āA
writes(" ->") # �\���p
every writes(" ",!LLL) # �o�͂���B
write()
}
}
end
####################
# ���z�̑g����
####################
# arg [1]: string ���z����p������F���z�p�^�[���̃g�[�^���ɍ����Ă邱�ƁB
# [2]: list ���z�p�^�[���i�~���� list�j
# [3]: string �O�̕�����i���ꕶ�����w��̏ꍇ�ɍ~���̂��̂����I�Ԃ��߂́j
# value : list �������ꂽ������i list�Ɋi�[�j
# Usage : every LL := expcomb(s,L) do ..
# ("abc", [2,1]) -> ["ab","c"], ["ac","b"], ["bc","a"]
# ("abcd",[2,2]) -> ["ab","cd"],["ac","bd"],["ad","bc"]
procedure expcomb(s,L,s_ref)
/s_ref := "" # �w��Ȃ���A��
s := csort(s) # ������\�[�g
if *L = 1 then { # �p�^�[���v�f�̍Ō�ŁA
if L[1] = *s_ref then { # �O��ƕ������������ŁA
if s << s_ref then return &fail # �������őO�Ȃ�A���s������B
}
return [s] # ���ŁA������A�������Ԃ��B
}
# �P�����̕�����w��Ȃ�A��́A���ɂP�������� list�ɓ���邾��
if L[1] = 1 then { # �P�����̕�����w��Ȃ�A
# ��́A���ɂP�������� list�ɓ���邾��
return [s[1]] ||| expcomb(s[2:0], L[2:0])
} # ���擪���� ���c�蕶���� ���c��̃��X�g
# �Q�����ȏ�̕�����w��Ȃ�A
every ss := exscomb(s,L[1]) do { # �����̑g�����������
if *ss = *s_ref then { # �O��ƕ������������ŁA
if ss << s_ref then return &fail # �������őO�Ȃ�A���s������B
} # ���Q�Ɨp������
suspend [ss] ||| expcomb(ssub(s,ss),L[2:0],ss)
} # ���g�������� ���c�蕶���� ���c��̃��X�g
end
####################
# ������̈����Z
####################
# arg [1]: string ��폜������
# [2]: string �폜������
# value : string ���ʕ�����
# ������ s1�̐擪����A������ s2�̕������폜�B�P�F�P�ō폜�B
# ("abcabc","abd") -> "cabc" s2�ɂ��镶���ŁAs1�ɖ��������͖��������B
procedure ssub(s1,s2)
every c := !s2 do { # s2����P���������o����
ss := "" # ��L�������폜��̕�����̊i�[�G���A
s1 ? { # s1�𑖍��ΏۂƂ��āA
if ss ||:= tab(upto(c)) then { # ������������� �������̕������
# ss�ɑ�������
move(1) # �P�����X�L�b�v
ss ||:= tab(0) # �c��̕�����𑫂�����
s1 := ss # s1�X�V
}
}
}
return s1
end
####################
# ������� nCm (n = *s) n������Am������I�ԁB generator
####################
# string�̑g�ݍ��킹
# nCm (n = *s) n�̂��̂���Am��I�ԁB
# arg: [1]: s: string
# [2]: m: integer
# value: string
# Usage: every ss := exscomb(s,m) do ...
# Icon����u���R�i�P�P�jscomb()�ꕶ���w��Ή��Ɋg��
procedure exscomb(s,m)
initial {
s := csort(s) # ��������\�[�g����B(BIPL:strings.icn)
/m := *s # �f�t�H���g nCn (n = m = *s)
}
if m = 0 then return "" # m�����J�E���^�[�Ɏg���B
# �O�Ȃ�����A�����őł��~�߁B
suspend s[i := new_pos(s)] || exscomb(s[i+1 : 0], m -1)
#�� �P�����I�� �� �����O�őI�����ȍ~ ���w�蕶������
# �b �̕�����ɑ����� �������}��
# �b �������s���B �邽�߂̃J�E
# ������̘A�� ���^�[
end
####################
# �\�[�g���ꂽ������ s�̍��͂�����A���ɕ����ʒu���o�͂��� generator�B
####################
# ��O�̕����Ɠ���Ȃ�X�L�b�v����B
# arg [1]: s string
# value: integer
# Usage: every i := new_pos(s) do ...
procedure new_pos(s)
ss := "" # ��O�̕������L�����Ă����ϐ�
every i := 1 to *s do {
if ss ~== s[i] then { # ��O�̕����ƈ���Ă�����
ss := s[i] # ��O�������X�V
suspend i # i ��Ԃ��B
}
}
end
####################
# BIPL(Icon��{���C�u�����[)�� strings.icn�Ɋ܂܂�� �����̃\�[�g procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ���[�J���ϐ��錾�i�����Ă��ǂ��j
s1 := "" # �����l�N���A
every c := !cset(s) do # ������ cset(�����W��)�֕ϊ������Ɏ��o���B
every find(c, s) do # ���o���������ŁA������������������A
s1 ||:= c # ������x�ɁA������ s1�ɑ������ށB
return s1
end
# cset���� !�ŗv�f�����o�����ɂ́A�A���t�@�x�b�g���Ɏ��o����B
-----$ PCOMB2.ICN ( lines:136 words:501 ) ------------------<cut here
pcomb2 > jjj �Ƃ���Ƃ����Ȃ�܂��B�Q�������Q����o�����ł̏d�����Ȃ��Ȃ�܂����B�@�Ȃ�Ƃ��A�P�[�X�����点���݂����ł��B
-----^ JJJ ( date:03-08-25 time:20:44 ) --------------------<cut here abcd --- -> abcd --- -> abc d -> abd c -> acd b -> bcd a --- -> ab cd -> ac bd -> ad bc --- -> ab c d -> ac b d -> ad b c -> bc a d -> bd a c -> cd a b --- -> a b c d -----$ JJJ ( lines:21 words:58 ) ---------------------------<cut here
�����������Icon�u���B
�� TSfree �� Icon�~�j�u���W�i���������j�@�@������
�����ɃC���f�b�N�X��t���Ċi�[����悤�ɂ��������ŁA�����Ǎ����S�O�b�ȏ�ɂȂ��Ă��܂��܂����B���ɁA�҂����Ԃ��c���C�̂ŁA��������K�v�Ȏ����̕��������A�ǂݍ��ނ悤�ɂ��܂����B�������A�܂����������̃t�@�C���ɕ������܂��B�������A�P��̕��������ɁA�e�[�u���ɓǍ��݂܂��B���ɕ��������̃t�@�C���ɏo�͂��܂��B�����̃_�u���`�F�b�N������āA�o�̓t�@�C���̓_�u�������܂��B
english.dic T_dic
+----------+ +-----------------------------+
|���� | |�e�[�u�� |
|�t�@�C�� |--->|key:1 ->value:[a,i] |---> �t�@�C�� e01�֏����o��
| | |key:2 ->value:[AA,Ab,AB,...] |---> �t�@�C�� e02�֏����o��
+----------+ | |
+-----------------------------+
-----^ DICDIV.ICN ( date:03-08-24 time:12:27 ) -------------<cut here
####################
# �����������ɕ���
####################
# dicdiv.icn Rev.1.0 2003/08/24 windy ������ H.S.
####################
# Usage dicdiv dictionary_name
# �������t�@�C���Ǎ��������̂��߁A�������ɕ�������̂Ɏg�p
# english.dic�́A�X�y���`�F�b�N�p�̉p�P�ꂪ���ɕ����́B
# ���̃v���O�����̃e�X�g�ł́ADD SOFT SoundMixSpell�R���|�[�l���g
# Ver 0.3.0 �� �����̎����t�@�C�����g�p�B
# This file is in the public domain.
procedure main(args)
if *args < 1 then stop("dicdiv dictionary_name")
dic := args[1]
# �����Ǎ�
dir := open(dic) | stop(dic," ��������܂���") # �t�@�C���I�[�v��
n := 0 # �t�@�C���s���J�E���^
S_dic := set() # �_�u���`�F�b�N�p set����
T_dic := table() # �������t�@�C���i�[ table����
write(&errout,dic," ��Ǎ����ł��B") # �t�@�C���ǂݍ���
write(&errout,"�J�n:",&clock)
while word := read(dir) do { # �t�@�C�����P�s���ǂݍ���ŁA
n +:= 1
if n % 1000 = 0 then writes(&errout,"*") # �ǂݍ��ݏ\��
if member(S_dic,word) then writes(&errout,"?") # �o�^�ς݂Ȃ�G���[�\��
else {
insert(S_dic,word) # set�ɓo�^
# �������� key�Ƃ����e�[�u���� list�`���Ŋi�[
if member(T_dic,*word) # �e�[�u���ɂ��邩�`�F�b�N
then put(T_dic[*word], word) # ����A���� list�ɒlj�
else T_dic[*word] := [word] # ������Alist�ɓ���ēo�^
}
}
close(dir) # �t�@�C���N���[�Y
write(&errout)
write(&errout,"�I��:",&clock)
write(&errout,dic," �̓Ǎ����I���܂����B�@�@",*S_dic," �ꂠ��܂����B")
# ���������� �����o��
write(&errout,"�����̕������ʕ������n�߂܂��B")
write(&errout,"�J�n:",&clock)
every x := key(T_dic) do {
# ���E�����킹��
f_out := dic[1] || right(x,2,"0") # �o�̓t�@�C�����F ���̃t�@�C������
# �擪�P���{����
# ���������[�h�Ńt�@�C���I�[�v��
dir := open(f_out,"w") | stop(f_out,"�t�@�C�����J���܂���B")
write(&errout,x,"��: ",f_out,": ",*T_dic[x]," �ꂠ��܂��B")
every write(dir,!T_dic[x]) # x���� list�v�f��S����o��
close(dir)
}
write(&errout,"�I��:",&clock)
write(&errout,"�����̕��������̕������I���܂����B")
end
-----$ DICDIV.ICN ( lines:59 words:187 ) -------------------<cut here
dicdiv english.dic �Ƃ��܂��ƁA���̂悤�ɕ�������܂��B
-----^ DIR.E ( date:03-08-24 time:12:41 ) ------------------<cut here
�h���C�u D: �̃{�����[�����x���� DATA
�{�����[���V���A���ԍ��� 112D-12DF
�f�B���N�g���� D:\2003\Unicon\TS_NW\CROSS\CROSS9
E01 6 03-08-24 12:28 E01
E02 1,444 03-08-24 12:28 E02
E03 9,070 03-08-24 12:28 E03
E04 35,286 03-08-24 12:28 E04
E05 87,381 03-08-24 12:28 E05
E06 172,848 03-08-24 12:28 E06
E07 286,461 03-08-24 12:28 E07
E08 386,510 03-08-24 12:28 E08
E09 425,040 03-08-24 12:28 E09
E10 399,012 03-08-24 12:28 E10
E11 329,615 03-08-24 12:28 E11
E12 248,346 03-08-24 12:28 E12
E13 176,520 03-08-24 12:28 E13
E14 122,784 03-08-24 12:28 E14
E15 79,084 03-08-24 12:28 E15
E16 49,194 03-08-24 12:28 E16
E17 29,716 03-08-24 12:28 E17
E18 17,500 03-08-24 12:28 E18
E19 9,093 03-08-24 12:28 E19
E20 3,916 03-08-24 12:28 E20
E21 1,932 03-08-24 12:28 E21
E22 912 03-08-24 12:28 E22
E23 450 03-08-24 12:28 E23
E24 338 03-08-24 12:28 E24
E25 54 03-08-24 12:28 E25
E27 29 03-08-24 12:28 E27
E28 30 03-08-24 12:28 E28
E29 31 03-08-24 12:28 E29
E30 32 03-08-24 12:28 E30
E31 33 03-08-24 12:28 E31
E32 34 03-08-24 12:28 E32
ENGLISH DIC 2,875,008 03-07-21 9:33 ENGLISH.DIC
32 �� 5,747,709 �o�C�g�̃t�@�C��������܂�.
0 �f�B���N�g�� 1,183,285,248 �o�C�g�̋�����܂�.
-----$ DIR.E ( lines:39 words:177 ) ------------------------<cut here
��Ԓ����P��́A�R�Q�����ŁAdichlorodiphenyltrichloroethanes �ł����A�Ȃ�Ƃ����Ӗ��Ȃ�ł��傤�ˁB�����Q�Ƃ��A���̕��������̕K�v�ȃt�@�C�������ǂݍ��ނ悤�ɁA�ύX���܂����B
-----^ DICREFP3.ICN ( date:03-08-24 time:12:48 ) -----------<cut here
####################
# �����Ǎ��E�g�p�����했�̕��ނ����������Q�ƂŁA�B�������Ή��B
####################
# dicrep3.icn Rev.1.0 2003/08/23 windy ������ H.S.
####################
# Usage dicrefp3 �p������(.�̓��C���h�J�[�h)
# ���������ɕ������ꂽ�����t�@�C�����g�p�B english.dic���B
# english.dic�́A�X�y���`�F�b�N�p�̉p�P�ꂪ���ɕ����́B
# ���̃v���O�����̃e�X�g�ł́ADD SOFT SoundMixSpell�R���|�[�l���g
# Ver 0.3.0 �� �����̎����t�@�C�����g�p�B
# This file is in the public domain.
procedure main(args)
# �R�}���h���C�������`�F�b�N�B������� Usage�\��
if *args < 1 then stop("dicrefp3 �p�P�� ( . �̓��C���h�J�[�h)")
# �����Ǎ�
n_dic := *args[1] # �����̕�����
# ���E�����킹��
dic := "e" || right(n_dic,2,"0") # �����t�@�C����
dir := open(dic) | stop("���̕������̎����͌�����܂���")
# �����t�@�C���I�[�v��
T_dic := table() # �����i�[ table����
write(" ",n_dic,"�����p���� ",dic," ��Ǎ����ł��B") # �����ǂݍ���
write("�J�n:",&clock)
n := 0 # �����s���J�E���^
while word := read(dir) do { # �������P�s���ǂݍ���ŁA
n +:= 1
if n % 1000 = 0 then writes(&errout,"*") # �ǂݍ��ݏ\��
# �P����������ϊ����\�[�g�������̂��C���f�b�N�X�ɂ��Ċi�[
# ���ꕶ�����܂ޒP��͓����C���f�b�N�X�� list�̗v�f�Ƃ��Ċi�[�����B
# ��������\�[�g
s_word := csort(map(word)) # �������֕ϊ����A�\�[�g����
# ���������ϊ�
if member(T_dic,s_word) # �����e�[�u���ɂ��邩�`�F�b�N
then put(T_dic[s_word], word) # ����A���� list�ɒlj�
else T_dic[s_word] := [word] # ������Alist�ɓ���ēo�^
}
close(dir) # �����t�@�C���N���[�Y
write(&errout)
write("�I��:",&clock)
write(" ",n_dic,"�����p���� ",dic," �̓Ǎ����I���܂����B",n," �ꂠ��܂����B")
write("���ꕶ���ō\\�������P����܂Ƃ߂�ƁA",*T_dic," ��ނƂȂ�܂��B")
# ��Shift-JIS�ł́A0x5c���܂ނ̂ŁA"\"��⊮�B
# �����Q�ƃe�X�g
# �R�}���h���C���̈����ɂāA�������Q��
c_word := args[1]
s_word := deletec(c_word,'.') # �R�}���h���C�������� '.'���폜
n := *c_word -*s_word # '.'�̐�
n_comb := 0 # �g�������J�E���^
n_find := 0 # �����ɂ��錏���J�E���^
write(c_word," �̑g�����������ɂ��邩�`�F�b�N���ł��B")
write("�J�n:",&clock)
every s := mscombd(string(&lcase),n) do { # ���C���h�J�[�h�Ή����������o��
n_comb +:= 1 # �g�������J�E���^�{�P
ss := csort(map(s || s_word)) # �R�}���h���C�������� '.'�ȊO�̕����ɑ���
# �������ϊ����A�\�[�g����
if member(T_dic,ss) # �����ɂ����
then {
n_find +:= 1 # �����ɂ��錏���J�E���^�{�P
writes(&errout,"!") # �����\��
writes(ss,": ") # �ϊ��O�̃f�[�^�������o��
every writes(" ",!T_dic[ss]) # �������e�������o��
write()
}
}
write(&errout)
write("�I��:",&clock)
write(n_comb," �ʂ�̑g�����̂����A",n_find," �ʂ肪�����ɂ���܂����B")
end
#############################
# ������d�����āA���A�~���̂��̂����o�� generator
#############################
# arg [1]: string
# [2]: integer
# value : string
# Usage : every ss := mscombd(s,n) do ..
# ("abc",2) -> "aa","ab","ac","bb","bc","cc"
procedure mscombd(s,n)
if n =0 then return "" # �ċA�I��
every i := 1 to *s do { # �P�`�����܂�
# �� i�Ԗڂ̕��������o����
suspend s[i] || mscombd(s[i:0],n-1)
} # ������ȍ~�̕����Ƒg�ݍ��킹��
end
# BIPL(Icon��{���C�u�����[)���
####################
# strings.icn�Ɋ܂܂�� �����̃\�[�g procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ���[�J���ϐ��錾�i�����Ă��ǂ��j
s1 := "" # �����l�N���A
every c := !cset(s) do # ������ cset(�����W��)�֕ϊ������Ɏ��o���B
every find(c, s) do # ���o���������ŁA������������������A
s1 ||:= c # ������x�ɁA������ s1�ɑ������ށB
return s1
end
# cset���� !�ŗv�f�����o�����ɂ́A�A���t�@�x�b�g���Ɏ��o����B
####################
# strings.icn�Ɋ܂܂�� �����̍폜 procedure
####################
procedure deletec(s, c) #: delete characters
local result # ���[�J���錾�i�����Ă��ǂ��j
result := "" # �폜��̕�����i�[�G���A
s ? { # s�𑖍��ΏۂƂ��āA
while result ||:= tab(upto(c)) do # c�������閘�̕�����𑫂������
tab(many(c)) # c�ȊO�̕����܂ŃX�L�b�v
return result ||:= tab(0) # �]��̕����𑫂�����
}
end
-----$ DICREFP3.ICN ( lines:120 words:401 ) ----------------<cut here
�i�NjL�@mscombd�Ƃ��������͊Ԉ���Ă��܂��ˁB�Ō�� d�͍~���Ƃ����Ӗ��Ȃ̂ł����A�����̒ʂ�A�\�[�g��������Ă��܂���̂ŁA�~���ɂ͂Ȃ�܂���B���� procedure�ɑ��閼�O�́Amscomb���������̂ł��B�j
dicrefp3 mi.nigh. >hhh �Ƃ���ƁA���̂悤�Ȍ��ʂɂȂ�܂��B�����ԁA�����Ǎ����Ԃ��Z���Ȃ�܂����B
-----^ HHH ( date:03-08-24 time:14:13 ) --------------------<cut here 8�����p���� e08 ��Ǎ����ł��B �J�n:14:13:51 �I��:14:13:54 8�����p���� e08 �̓Ǎ����I���܂����B38651 �ꂠ��܂����B ���ꕶ���ō\�������P����܂Ƃ߂�ƁA32836 ��ނƂȂ�܂��B mi.nigh. �̑g�����������ɂ��邩�`�F�b�N���ł��B �J�n:14:13:54 acghiimn: Michigan cghiimnr: chirming cghiimns: michings cghiimnt: mitching dghiimnt: midnight ghiimmns: shimming ghiimmnw: whimming ghiimnnu: inhuming ghiimnst: smithing �I��:14:13:54 351 �ʂ�̑g�����̂����A9 �ʂ肪�����ɂ���܂����B -----$ HHH ( lines:18 words:36 ) ---------------------------<cut here
�����������Icon�u���B
�� TSfree �� Icon�~�j�u���V�i�B���Q�Ɓj�@�@������
��߂��Ȃ��E�~�܂�Ȃ��G�r�Z���̎��̂��߁A�����~�j�u���̑������l���Ă��܂��܂��B�@�B�����������Ă݂܂����B�R�}���h���C������A�p����������w�肵�Ď����������s���܂����A'.'�����C���h�J�[�h (a-z)�ƌ��Ȃ���悤�ɂ��Ă݂܂����B'.'���Q�����ȏ�̏ꍇ�́A"ab"�� "ba"�̂悤�Ȃ��̂́A�ʂɌ������Ȃ��悤�ɍH�����܂����B&lcase�́A�p�������ɑΉ�����g���L�[���[�h�ł��B
-----^ DICREFP2.ICN ( date:03-08-23 time:21:51 ) -----------<cut here
####################
# �����Ǎ��E�g�p�����했�̕��ނ����������Q�ƂŁA�B�������Ή��B
####################
# dicrep2.icn Rev.1.0 2003/08/23 windy ������ H.S.
####################
# Usage dicrefp2 �p������(.�̓��C���h�J�[�h)
# english.dic�́A�X�y���`�F�b�N�p�̉p�P�ꂪ���ɕ����́B
# ���̃v���O�����̃e�X�g�ł́ADD SOFT SoundMixSpell�R���|�[�l���g
# Ver 0.3.0 �� �����̎����t�@�C�����g�p�B
# This file is in the public domain.
procedure main(args)
# �R�}���h���C�������`�F�b�N�B������� Usage�\��
if *args < 1 then stop("dicrefp2 �p�P�� ( . �̓��C���h�J�[�h)")
# �����Ǎ�
dic := "english.dic" # �����t�@�C����
dir := open(dic) | stop(dic," ��������܂���") # �����t�@�C���I�[�v��
S_dic := set() # �����_�u���`�F�b�N�p set����
T_dic := table() # �����i�[ table����
write(dic," ��Ǎ����ł��B") # �����ǂݍ���
write("�J�n:",&clock)
n := 0 # �����s���J�E���^
while word := read(dir) do { # �������P�s���ǂݍ���ŁA
n +:= 1
if n % 1000 = 0 then writes(&errout,"*") # �ǂݍ��ݏ\��
if member(S_dic,word) then writes(&errout,"?") # �o�^�ς݂Ȃ�G���[�\��
else {
insert(S_dic,word) # set�ɓo�^
# �P����������ϊ����\�[�g�������̂��C���f�b�N�X�ɂ��Ċi�[
# ���ꕶ�����܂ޒP��͓����C���f�b�N�X�� list�̗v�f�Ƃ��Ċi�[�����B
# ��������\�[�g
s_word := csort(map(word)) # �������֕ϊ����A�\�[�g����
# ���������ϊ�
if member(T_dic,s_word) # �����e�[�u���ɂ��邩�`�F�b�N
then put(T_dic[s_word], word) # ����A���� list�ɒlj�
else T_dic[s_word] := [word] # ������Alist�ɓ���ēo�^
}
}
close(dir) # �����t�@�C���N���[�Y
write(&errout)
write("�I��:",&clock)
write(dic," �̓Ǎ����I���܂����B�@�@",*S_dic," �ꂠ��܂����B")
write("���ꕶ���ō\\�������P����܂Ƃ߂�ƁA",*T_dic," ��ނƂȂ�܂��B")
# ��Shift-JIS�ł́A0x5c���܂ނ̂ŁA"\"��⊮�B
# �����Q�ƃe�X�g
# �R�}���h���C���̈����ɂāA�������Q��
c_word := args[1]
s_word := deletec(c_word,'.') # �R�}���h���C�������� '.'���폜
n := *c_word -*s_word # '.'�̐�
n_comb := 0 # �g�������J�E���^
n_find := 0 # �����ɂ��錏���J�E���^
write(c_word," �̑g�����������ɂ��邩�`�F�b�N���ł��B")
write("�J�n:",&clock)
every s := mscombd(string(&lcase),n) do { # ���C���h�J�[�h�Ή����������o��
n_comb +:= 1 # �g�������J�E���^�{�P
ss := csort(map(s || s_word)) # �R�}���h���C�������� '.'�ȊO�̕����ɑ���
# �������ϊ����A�\�[�g����
if member(T_dic,ss) # �����ɂ����
then {
n_find +:= 1 # �����ɂ��錏���J�E���^�{�P
writes(&errout,"!") # �����\��
writes(ss,": ") # �ϊ��O�̃f�[�^�������o��
every writes(" ",!T_dic[ss]) # �������e�������o��
write()
}
}
write(&errout)
write("�I��:",&clock)
write(n_comb," �ʂ�̑g�����̂����A",n_find," �ʂ肪�����ɂ���܂����B")
end
#############################
# ������d�����āA���A�~���̂��̂����o�� generator
#############################
# arg [1]: string
# [2]: integer
# value : string
# Usage : every ss := mscombd(s,n) do ..
# ("abc",2) -> "aa","ab","ac","bb","bc","cc"
procedure mscombd(s,n)
if n =0 then return "" # �ċA�I��
every i := 1 to *s do { # �P�`�����܂�
# �� i�Ԗڂ̕��������o����
suspend s[i] || mscombd(s[i:0],n-1)
} # ������ȍ~�̕����Ƒg�ݍ��킹��
end
# BIPL(Icon��{���C�u�����[)���
####################
# strings.icn�Ɋ܂܂�� �����̃\�[�g procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ���[�J���ϐ��錾�i�����Ă��ǂ��j
s1 := "" # �����l�N���A
every c := !cset(s) do # ������ cset(�����W��)�֕ϊ������Ɏ��o���B
every find(c, s) do # ���o���������ŁA������������������A
s1 ||:= c # ������x�ɁA������ s1�ɑ������ށB
return s1
end
# cset���� !�ŗv�f�����o�����ɂ́A�A���t�@�x�b�g���Ɏ��o����B
####################
# strings.icn�Ɋ܂܂�� �����̍폜 procedure
####################
procedure deletec(s, c) #: delete characters
local result # ���[�J���錾�i�����Ă��ǂ��j
result := "" # �폜��̕�����i�[�G���A
s ? { # s�𑖍��ΏۂƂ��āA
while result ||:= tab(upto(c)) do # c�������閘�̕�����𑫂������
tab(many(c)) # c�ȊO�̕����܂ŃX�L�b�v
return result ||:= tab(0) # �]��̕����𑫂�����
}
end
-----$ DICREFP2.ICN ( lines:123 words:404 ) ----------------<cut here
dicrefp2 sunris. >ggg �ƁA���C���h�J�[�h���@�P���ꂽ�ꍇ�͂���Ȍ��ʂɂȂ�܂��B
-----^ GGG ( date:03-08-23 time:21:52 ) --------------------<cut here english.dic ��Ǎ����ł��B �J�n:21:51:57 �I��:21:52:40 english.dic �̓Ǎ����I���܂����B�@�@257650 �ꂠ��܂����B ���ꕶ���ō\�������P����܂Ƃ߂�ƁA223704 ��ނƂȂ�܂��B sunris. �̑g�����������ɂ��邩�`�F�b�N���ł��B �J�n:21:52:40 ainrssu: Russian Surnias dinrssu: sundris einrssu: insures Serinus sunrise �I��:21:52:40 26 �ʂ�̑g�����̂����A3 �ʂ肪�����ɂ���܂����B -----$ GGG ( lines:12 words:25 ) ---------------------------<cut here
�����������Icon�u���B
�� TSfree �� Icon�~�j�u���U�i�����Q�Ƃ̕ʕ����j�@�@������
�O��ŁA�~�j�u���͏I���������ł����̂ł����A�����Q�Ƃ��ǂ����X�b�L�����܂���̂ŁA�c���c���l���Ă��܂����B�i�V�c�R�C�I�j
���蕶�����g�����P����X�o���N��������̂�������A�X�o���C�����ɂ́Aset�� table���g���̂��ǂ��B���ꕶ�����g����������ɁA�������ʂ̃C���f�b�N�X��t���āA�e�[�u���ɓo�^���Ă����A�X�o���N�����ł���B
�Ƃ������ƂŁA�����̒P��̕�������\�[�g�������̂ŁA�C���f�b�N�X������Ă����āA���ꕶ�����g�p�����P����܂Ƃ߂āA�e�[�u���ɓo�^���Ă����A������������������\�[�g�������̂ŁA�e�[�u�����Q�Ƃ���A���̎Q�ƂŁA���̒P��Q��������B�ƁA�C���t���܂����B
�Ⴆ�A"abcd"�� "cdab"�� "dcab"�Ƃ����P�ꂪ�������Ƃ��āA�F�\�[�g����ƁA"abcd"�ƂȂ�܂��B�\�[�g���� "abcd"�� �C���f�b�N�X�iIcon�ł� key�ƌ����܂��B�j�Ƃ��āA�l�� list�`���ŁA["abcd","cdab","dcab"]�Ɗi�[���Ă����A"abcd"�ŎQ�Ƃ���A�����̔z������ւ����ꍇ�̌�₪�A�ꋓ�ɏo�Ă��܂��B
���̕����ł��ƁA�s���������A�P�`�Q��������� 26�{�Ƃ��A26^2�{���x�ɏ����������Ă��A�K�}���ł��鎞�Ԃŏ������ł������ł��B
�@�@�@�@�@�@�@�@���\�[�g
�@���� "abcd" ----> �e�[�u��
"cdab" ----> key: "abcd" ->value: ["abcd","cdab","dcab"]
"dcab" ----> ��
�b�Q��
�@�������� --->�\�[�g---------
�Ƃ����l���ŁA�����Ǎ��E�Q�Ƃ̃v���O�������C�����Ă݂܂����B
�����̓o�^�����Ƀ_�u��������܂��Bset�ɓo�^����ꍇ�͖��͋N���Ȃ��̂ł����e�[�u���ɓo�^���鎞�� value�Ń_�u���Ƃ����Ȃ��̂ŁA�`�F�b�N�����Ă���܂��B
�܂� key�́A�������ɓ��ꂵ�ď�������悤�ɂ��܂����B
-----^ DICREF2.ICN ( date:03-08-23 time:11:12 ) ------------<cut here
####################
# �����Ǎ��E�g�p�����했�̕��ނ����������Q�Ƃ̏K��B
####################
# dicref2.icn Rev.1.0 2003/08/23 windy ������ H.S.
####################
# Usage dicref2
# english.dic�́A�X�y���`�F�b�N�p�̉p�P�ꂪ���ɕ����́B
# ���̃v���O�����̃e�X�g�ł́ADD SOFT SoundMixSpell�R���|�[�l���g
# Ver 0.3.0 �� �����̎����t�@�C�����g�p�B
# This file is in the public domain.
procedure main()
# �����Ǎ�
dic := "english.dic" # �����t�@�C����
dir := open(dic) | stop(dic," ��������܂���") # �����t�@�C���I�[�v��
S_dic := set() # �����_�u���`�F�b�N�p set����
T_dic := table() # �����i�[ table����
write(dic," ��Ǎ����ł��B") # �����ǂݍ���
write("�J�n:",&clock)
n := 0 # �����s���J�E���^
while word := read(dir) do { # �������P�s���ǂݍ���ŁA
n +:= 1
if n % 1000 = 0 then writes(&errout,"*") # �ǂݍ��ݏ\��
if member(S_dic,word) then writes(&errout,"?") # �o�^�ς݂Ȃ�G���[�\��
else {
insert(S_dic,word) # set�ɓo�^
# �P����������ϊ����\�[�g�������̂��C���f�b�N�X�ɂ��Ċi�[
# ���ꕶ�����܂ޒP��͓����C���f�b�N�X�� list�̗v�f�Ƃ��Ċi�[�����B
# ��������\�[�g
s_word := csort(map(word)) # �������֕ϊ����A�\�[�g����
# ���������ϊ�
if member(T_dic,s_word) # �����e�[�u���ɂ��邩�`�F�b�N
then put(T_dic[s_word], word) # ����A���� list�ɒlj�
else T_dic[s_word] := [word] # ������Alist�ɓ���ēo�^
}
}
close(dir) # �����t�@�C���N���[�Y
write(&errout)
write("�I��:",&clock)
write(dic," �̓Ǎ����I���܂����B�@�@",*S_dic," �ꂠ��܂����B")
write("���ꕶ���ō\\�������P����܂Ƃ߂�ƁA",*T_dic," ��ނƂȂ�܂��B")
# ��Shift-JIS�ł́A0x5c���܂ނ̂ŁA"\"��⊮�B
# �����Q�ƃe�X�g
L := ["heavy","rain","yveah","niar","noword"] # �e�X�g�f�[�^
write("�Q�ƃe�X�g���J�n���܂��B")
write("�J�n:",&clock)
every s := !L do { # �e�X�g�f�[�^�������ǂݏo��
ss := csort(map(s)) # �e�X�g�f�[�^���A�������ϊ����A�\�[�g����
writes(s,": ") # �ϊ��O�̃f�[�^�������o��
if member(T_dic,ss) # �����ɂ����
then {
every writes(" ",!T_dic[ss]) # �������e�������o��
write()
}
else write("�����ɂ���܂���B")
}
write("�I��:",&clock)
write("�Q�ƃe�X�g���I���܂����B")
end
####################
# BIPL(Icon��{���C�u�����[)�� strings.icn�Ɋ܂܂�� �����̃\�[�g procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ���[�J���ϐ��錾�i�����Ă��ǂ��j
s1 := "" # �����l�N���A
every c := !cset(s) do # ������ cset(�����W��)�֕ϊ������Ɏ��o���B
every find(c, s) do # ���o���������ŁA������������������A
s1 ||:= c # ������x�ɁA������ s1�ɑ������ށB
return s1
end
# cset���� !�ŗv�f�����o�����ɂ́A�A���t�@�x�b�g���Ɏ��o����B
-----$ DICREF2.ICN ( lines:76 words:243 ) ------------------<cut here
dicref2 >fff �Ƃ���ƁA�����������ʂɂȂ�܂��B�@�����Ǎ��̍ۂɁA���H�����Ă��܂��̂ŁA�Ǎ����Ԃ��@�S�Q�b�ɑ����Ă��܂��B
-----^ FFF ( date:03-08-23 time:11:13 ) --------------------<cut here english.dic ��Ǎ����ł��B �J�n:11:12:25 �I��:11:13:07 english.dic �̓Ǎ����I���܂����B�@�@257650 �ꂠ��܂����B ���ꕶ���ō\�������P����܂Ƃ߂�ƁA223704 ��ނƂȂ�܂��B �Q�ƃe�X�g���J�n���܂��B �J�n:11:13:07 heavy: heavy Yahve rain: airn Arni Iran rain rani yveah: heavy Yahve niar: airn Arni Iran rain rani noword: �����ɂ���܂���B �I��:11:13:07 �Q�ƃe�X�g���I���܂����B -----$ FFF ( lines:14 words:33 ) ---------------------------<cut here
���̃v���O�����ł́Atable�̒l�� list�����Ă��܂����AIcon�ł́Atable�̒l�� table�Ƃ��Alist�̒l�� table�� list�Ƃ��A���ƕ��G�ȃf�[�^�\�����r�I�ȒP�Ɏ����ł��܂��B
�������͐��Q�łЂǂ���ԁB�V�C�\��ł͉J�͖����������~��炵���B��Q���������Ȃ���悢���B�����́A�L���͂Ȃ����A�䂪���Ă����B��N�Ȃ炻�낻��~�J�������Ă��悢�������B�����͉F�i�ԉΑ��B���N�͂ł��邾���߂Â��Č��悤�ƃj�`���C�̑q�ɂ̓�܂ŕ������B
 �ԉ�(1) �ԉ�(1) |  �ԉ�(2) �ԉ�(2) |
 �ԉ�(3) �ԉ�(3) |  �ԉ�(4) �ԉ�(4) |
�X���b�V���h�b�g �W���p�� | �Z�}���e�B�b�N�E�F�u�ɑ���Google�̋^���l�^�B������Ǝ��₪�킯�̂킩��Ȃ����̂����E�E�EWebmaster���āA�T�[�o�[�̐ݒ肪�ł��Ȃ�������AHTML�������Ȃ����̂Ȃ�^^;�m��Ȃ������B
Semantic Web(RDF)���g���邩�ǂ����́A���ꂩ��̘b���낤�B���Ɏg���̂��֗��Ȃ̂��A�v�������Ƃ��ł���A�����Ă����Ă��g�����낤�BRSS1.0���@�\���g�����ׂ���������悢�̂ɁB���̂܂܂ł͎g���Ȃ��Ȃ邾�낤�B�����������y����RDF�A�v���P�[�V�����Ȃ̂ɁARSS 2.0��Atom��XML�A�v���P�[�V�����ɂȂ��Ă��܂��������B
�`�����X�L�[�ōX�V���L����������ƁA�ɋy�Ԃ��炢�̋L�����o�Ă���B����搶�́u����̔]�Ȋw�v�����������Ƃ��Ă����A�S���̃��X�g�ɖ߂��Ă����B�l�̊S���͓��R?�Ȃ̂��낤���ǁA�X���[�����[���h���`�����Ă��āA�u�t�[�R�[�E�R���N�V���� 3 �����E�\�ہv�́u6. �w�|�[���E�����C�����̕��@�x�̏����v�Ƀ`�����X�L�[�ɂ��Ă̋L�ڂ��������B
<�f�J���g�h����w>�̌�����ʂ��āA�`�����X�L�[�͂������ČÓT�h�̕��@�������̌���w�ɋ߂Â��Ă��Ȃ��B�ނ���A���҂̖����ƂȂ�A�����̋��ʂ̏����悤�Ƃ���ЂƂ̕��@���o�������߂悤�Ƃ��Ă���̂��B���Ȃ킿�A���Ƃ𗣎U�I�v�f�̏W���Ƃ��Ăł͂Ȃ��A�n���I�����Ƃ��ĕ��͂���悤�ȕ��@�A�\�w�ɂ����Ă����ڂɂ�����̂��܂��܂Ȃ������̉��ɐ[�w�\�����`�����悤�ȕ��@�A���֘A�̒P���ȋL�q�������I���͂̓����ōČ������悤�ȁA�����āA����̑̌n��������K�������߂闝���̋�g�ƕs���ł���悤�ȕ��@�ł���B����̌���w�ɂƂ��ăf�J���g�h���@�́A���͂₽��ɂ��̑Ώۂ�菇�ɂ��ĂȂ����V��ȁA�����\���ł�����肩�A����ŗL�̗��j�ɎQ�^���A���̕ϗe�̋L�^�ɖ����L�����̂Ȃ̂��B(�~�V�F���E�t�[�R�[�A�u�t�[�R�[�E�R���N�V���� 3 �����E�\�ہv�A�u6. �w�|�[���E�����C�����̕��@�x�̏����v�A1969�N�A211-212�y�[�W)
�t�[�R�[���`�����X�L�[�̎d���̉��߂Ƃ��čl���Ă��邱�Ƃ́A���炪�~���Ă��邱�Ƃ̂悤�Ɏv���邪�A�`�����X�L�[�Ɠ��N��̃t�[�R�[�̓`�����X�L�[�̕ό`�������@�̖����ɑz���͂���点�Ă�����������Ȃ��BChomsky��Foucault����ׂāA�O�O���CHOMSKY.INFO�̓��_�̋L���������|�������B�t�[�R�[�̌�N�̌����̑�ނ͓��Ƀ`�����X�L�[�̉e�����Ă���\��������B
���{��ɂ��`�����X�L�[�̉���́A�u����@�ӓ���w�̂��U���i�}�b�Nde�L���_�j���@Rideo, ergo sum.�@�v�ɂ�����̂��悳�����B
�ȒP�Ɍ����A�ό`�������@�́A����̐[�w�\����L���̐��̋K���ŕό`����ƁA������\�w�\���邱�Ƃ��ł���Ƃ������Ƃł���B�]���āA�[�w�\���ƕό`�K������A������\�w�\��������ł���K�v������B���ꂪ�ؖ��ł���A�[�w�\���ƕό`�K���̎d�g�݂��]�Ɍ�����͂��ł���B���ꂾ�����ƁA������ƒP�������邩������Ȃ��B����̐[�w�\���͈ӎ����ɂ���ƍl�����A�L���Ƃ��Đ₦���ω����Ă���͂������A����ƋL���Ƃ̊W�͂܂������c�_����Ă��Ȃ��B�L���̕ێ������\�����̂��킩���Ă��Ȃ��ǂ��납�A�L�������������킩���Ă��Ȃ��̂�����A�����_�ł́A�l���Ă����������Ȃ��̂�������Ȃ��B���o��g�̂Ƃ̌��ѕt��������͂������A�[�w�\���Ƃ͒P���Ȍ�̏W���Ƃ��Ă̍\���ł͂Ȃ��悤�Ɏv����B���ꂪ�w�K����A�ێ�����鐶���I�\���Ƃ͂ǂ̂悤�Ȃ��̂��낤���B
���A�u����w�Ƃ͉����v�A��g���X�A��g�V��(�V�Ԕ�)303�A2003�N9��25����1�ő�15��(1993�N10��20����1��)�A229�y�[�W�A740�AISBN4-00-430303-6�ɂ́A�`�����X�L�[�ᔻ���W�J����Ă��邪�A�`�����X�L�[�͎����̂���Ă��邱�Ƃ͂悭�킩���Ă���Ǝv���B�Ӗ��I�ɂ͐[�w�\�������ɂȂ�킯�ŁA�P�ɕ\�w�\���̑��l��������ł����Ƃ��Ă��A���ꂪ���@�̖ړI�ł��邩�炻���ڎw���͓̂��R�ł��邪�A�Ӗ���Nj�����̂́A�[�w�\���ɂ����Ăł���B�\�w�\�����������錴����Njy���邱�Ƃɂ���āA�[�w�\�������炩�ɂȂ��Ă����Ƃ����t���[�����[�N������Ƃ���ɕό`�������@�̉��l������̂ł͂Ȃ��̂��낤���ƁA�f�l�Ȃ���v���Ă݂���E�E�E�t�[�R�[���q�ׂĂ���̂����̂悤�Ȃ��Ƃ��낤�B
���Ƀ��^�f�[�^��t�^���āA�@�B�ɗ��������悤�Ƃ��Ă���l�ԂƂ͉����낤�Ǝv�����A�悭�l�����1940�N��ɃR���s���[�^���o�ꂵ�Ĉȗ��A�@�B��ő���A�l�X�Ȍ��ꂪ�o�����Ă���킯�ŁA���^�f�[�^�����߂���f�[�^�x�[�X(�L���ɑ�������)�ɂ���āA���^�f�[�^��t�^���������@�B�̏��L�Ӗ��ɑ���A����͔]�̌���I�\�����V�~�����[�g�������̂Ƃ����邩������Ȃ��B�v���O���~���O�̌����́A�]�̌���I�����ɍł��߂��Ƃ���ɂ���̂�������Ȃ��B
���T�̃T�C�o�[�X�y�[�X�E�J�E�{�[�C�Y�l�^�B�O�҂̓J���I�P��F�������̂ŁA�I�C�I�C�Ǝv�������A��҂͂������납�����ˁB�ł�����オ�肫��Ȃ��������ȁB�����o�͑S�J�ł͔��Ă��܂�����A����ȂƂ���ŁB50��ȍ~�S��CD-R�ɃR�s�[���Ė��������Ă���B����[�A���x�����Ă��������낢�B�ЂƂ�Ńj���j�����Ȃ���Ԃ��^�]���Ă���B���̎Ԃ��猩����s�C���Ȃ��ƊԈႢ�Ȃ�(^^;)
�䂪�T�C�g�̉ċx�݃l�^�B�J�E�{�[�C�l�^����o����ŁA�ċx�ݍH��Ɂu�]�v�ł���邩�Ȃ�Ďv���Ă���B���āAC�̃\�[�X���͂�����AVC++������ɈڐA���Ă݂悤���B�ꍇ�ɂ���ẮAPerl�Œ��ڏ����Ă����������E�E�E�����ł��邩�ǂ����͕s�������A�G���Ă݂Ȃ��ƁE�E�E
�X���b�V���h�b�g �W���p�� | ��������}���فA���{�̋ߑ�j�����I�����C�����J�l�^�B
�C���^�[�l�b�g�̂������B���ƂłȂ��Ă��A�n���ɏZ��ł��Ă��A�����ɃA�N�Z�X�ł���悤�ɂȂ�B�f���炵�����ƁB
�z���͂��h������u���Ԏ��v���߂��鎎�� - CNET Japan�l�^�B
Piggy-Bank��David Huynh��(MIT Haystack team)������Ă���B�l�����j�l�^������̂ŁA�N�\����肽���ȂƎv���Ă����B�\�[�X���I�[�v���Ȃ̂ŎQ�l�ɂȂ肻�����B
�����������Icon�u���B
�� TSfree �� Icon�~�j�u�����T�i�������E�����Q�Ɓj�@�@������
�����́A���n�ł́A�ߑO���͓��������Ă��܂������A�ߌ�ɉ_���L�����ē܋�ɁB���������Ɏア���ɂ́A�������čD�s���Ȃ̂ł����B
���č���́A���܂ł̂܂Ƃ߂ŁA��������������̂Ŏ������Q�Ƃ��鏈�������܂��B�@�v���O�����́A�����Q�Ƃ̏��ŁA�������p�^�[���i��o��������̒����j�����o���Ă��āA����ɏ]�����ɕ���������Ŏ������Q�Ƃ��܂��B
move()�Ƃ������o�Ă��܂����A����͕�����ɑ���|�C���^�[�������̂ł��B
���̂悤�ɁA�����珇�Ɏw�蒷�̕�������������o�����Ƃ��ł��܂��B
-----^ DICREFPD.ICN ( date:03-08-21 time:19:10 ) -----------<cut here
####################
# �����Ǎ��E�������^�����E�����Q��
####################
# dicrefpd.icn Rev.1.0 2003/08/21 windy ������ H.S.
####################
# Usage dicrefpd �p������ �ő啪���� �ŏ�������
# english.dic�́A�X�y���`�F�b�N�p�̉p�P�ꂪ���ɕ����́B
# ���̃v���O�����̃e�X�g�ł́ADD SOFT SoundMixSpell�R���|�[�l���g
# Ver 0.3.0 �� �����̎����t�@�C�����g�p�B
# 5�����̕�������A5=2+2+1�ɕ����������� 2�̂Ƃ���ŁA�_�u����������B
# �Ⴆ�A"ab"�A"cd"�A"e"�������ɂ���� ab cd e �� cd ab e���o�͂����B
# This file is in the public domain.
procedure main(args)
# �R�}���h���C�������`�F�b�N�B������� Usage�\��
if *args < 1 then stop("dicrefpd ������ �ő啪���� �ŏ�������")
# �����Ǎ�
dic := "english.dic" # �����t�@�C����
dir := open(dic) | stop(dic," ��������܂���") # �����t�@�C���I�[�v��
S_dic := set() # �����i�[ set����
# write(&errout,dic," ��Ǎ����ł��B") # �����ǂݍ���
write(dic," ��Ǎ����ł��B") # �����ǂݍ���
# write(&errout,"�J�n:",&clock)
write("�J�n:",&clock)
n_line := 0 # �����s���J�E���^
while word := read(dir) do { # �������P�s���ǂݍ���ŁA
insert(S_dic,word) # set�ɓo�^
n_line +:= 1
if n_line % 1000 = 0 then writes(&errout,"*") # �ǂݍ��ݏ\��
}
close(dir) # �����t�@�C���N���[�Y
write(&errout)
# write(&errout,"�I��:",&clock)
write("�I��:",&clock)
# write(&errout,dic," �̓Ǎ����I���܂����B\n",*S_dic," �ꂠ��܂����B")
write(dic," �̓Ǎ����I���܂����B\n",*S_dic," �ꂠ��܂����B")
# �R�}���h���C���̈����̏�������A�������Q��
c_word := args[1]
ndiv := \args[2] | 1 # �������w�薳���́A�P�i���������j
nmin := \args[3] | *c_word # �ŏ��������w�薳���́A����������
n_comb := 0 # �g�������J�E���^
n_find := 0 # �����ɂ��錏���J�E���^
L_pat := [] # �������p�^�[���i�[ list
every put(L_pat,n_divdf(*c_word,ndiv,nmin)) # �����p�^�[���i�[
# write(&errout,"\n",c_word," ���A�ő啪���� ",ndiv,"�A�ŏ������� ",nmin,
# " �ɂĕ������āA���̑S�Ă������ɂ��邩�`�F�b�N���B")
write("\n",c_word," ���A�ő啪���� ",ndiv,"�A�ŏ������� ",nmin,
" �ɂĕ������āA���̑S�Ă������ɂ��邩�`�F�b�N���B")
# write(&errout,"�J�n:",&clock)
write("�J�n:",&clock)
# ���R�}���h���C��������̑g�������������o��
every s := exsperm(c_word) do {
every L := !L_pat do { # ��������ו�����f�[�^�����o����
ERR := &null # �����Q�ƃG���[�t���b�O���Z�b�g
ss := "" # �ו���̕�����i�[�G���A
s ? { # s�𑖍��ΏۂƂ��āA
every (length := !L ) & /ERR do { # �ו������������o���āA
# �����Ɏ����Q�ƃG���[���������Ă��Ȃ���A
n_comb +:= 1 # �`�F�b�N�J�E���^�{�P
if n_comb % 1000 = 0 then writes(&errout,"*") # �`�F�b�N�\��
sss := move(length) # �ו�������̎��o��
# �ו������������ɑ��݂��邩�`�F�b�N
if member(S_dic,sss) then ss ||:= (sss || " ") # �f�[�^��������
else ERR := "ERR" # �Q�ƃG���[�t���b�O�Z�b�g
}
# �ו������S�Ď����ɂ���A�����o��
if /ERR then { # �G���[�t���b�O�������Ă��Ȃ����
n_find +:= 1 # �J�E���^�{�P
write(s," -> ",ss) # �g����������o��
writes(&errout,"!") # ���v�\��
}
}
}
}
write(&errout)
# write(&errout,"�I��:",&clock)
write("�I��:",&clock)
# write(&errout,n_comb," �ʂ�̑g�����̂����A",n_find," �ʂ肪�����ɂ���܂����B")
write(n_comb," �ʂ�̑g�����̂����A",n_find," �ʂ肪�����ɂ���܂����B")
end
####################
# ���������� generator
####################
# 5=3+2 ���ɐ�����������B���� procedure�� n_divd���Ăуt�B���^�[���|���Ă���B
# �����p�^�[�����������鎞�ɁA�����������邽�߂Ɏg�p�B
# arg [1]: �������錳�̐�
# [2]: �ő啪����
# [3]: �ŏ���
# value : list
procedure n_divdf(r,ndiv,nmin)
every L := n_divd(r) do { # r �̕������ʂ����o��
if *L <= ndiv then { # �������`�F�b�N�ilist�̃T�C�Y�`�F�b�N�j
if L[*L] >= nmin then suspend L # �ŏ����`�F�b�N�i�~���ɓ����Ă���̂�
} # �����̗v�f���`�F�b�N�j
}
end
####################
# ���������� generator
####################
# 5=3+2 ���ɕ�������B�����͍~���̂����B�i�� 5=2+3�͏��O�j
# arg [1]: ��������錳�̐��i�ċA�̏ꍇ�́A�O�̏����̗]��j
# [2]: �ő吔 �i5=2+2+1 �̏ꍇ�ɁA�ŏ��� 2�̎� 3���]�邪�A�ċA���� 3��
# �������n�߂鎞�A3����ł͂Ȃ� 2����n�߂邽�߂̍H�B�~���蓖�B�j
# value : �������ʂ̐��Blist�Ɋi�[
# Usage : every L := n_divd(r) do ...
procedure n_divd(r,max)
/max := r # �w�薳���́A��������錳�̐����̂���
if r < 1 then fail # �O�̂���
if r = 1 then return [1] # �ċA�I��
# r >= 2 �̏ꍇ
if r > max then rs := max # �����i��苎��j���̍ő吔�̐ݒ�B
else rs := r # ��������鐔�� �ő吔�w��� ��������
every i := rs to 1 by -1 do { # ��L�w�萔�`�P���A���Ɂ|�P���Ȃ���
rr := r -i # �V���ȗ]��
if rr = 0 then suspend [i] # �]�肪�������
# �]�肪����A�ċA����
else if rr > i then suspend [i] ||| n_divd(rr,i) # �]�肪�傫�߂��鎞
else suspend [i] ||| n_divd(rr)
}
end
# �ȉ��́AIcon����u��������p
####################
# �p�����̑g�ݍ��킹�i���ꕶ���w��Ή��j
####################
# ���̕ύX expermute -> exsperm
# arg [1]: s string
# value: string
# Usage: every ss := exsperm(s) do ...
# Icon����u���Q�i�P�W�j
procedure exsperm(s) # string permutations
if *s = 0 then return "" #
ss := csort(s) # ��������\�[�g����B(strings.icn)
suspend ss[i := new_pos(ss)] || exsperm(ss[1:i] || ss[i+1:0])
# �����ꕶ���̓X�L�b�v����
end
####################
# �\�[�g���ꂽ������ s�̍��͂�����A���ɕ����ʒu���o�͂��� generator�B
####################
# ��O�̕����Ɠ���Ȃ�X�L�b�v����B
# arg [1]: s string
# value: integer
# Usage: every i := new_pos(s) do ...
procedure new_pos(s)
ss := "" # ��O�̕������L�����Ă����ϐ�
every i := 1 to *s do {
if ss ~== s[i] then { # ��O�̕����ƈ���Ă�����
ss := s[i] # ��O�������X�V
suspend i # i ��Ԃ��B
}
}
end
####################
# BIPL(Icon��{���C�u�����[)�� strings.icn�Ɋ܂܂�� �����̃\�[�g procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ���[�J���ϐ��錾�i�����Ă��ǂ��j
s1 := "" # �����l�N���A
every c := !cset(s) do # ������ cset(�����W��)�֕ϊ������Ɏ��o���B
every find(c, s) do # ���o���������ŁA������������������A
s1 ||:= c # ������x�ɁA������ s1�ɑ������ށB
return s1
end
# cset���� !�ŗv�f�����o�����ɂ́A�A���t�@�x�b�g���Ɏ��o����B
-----$ DICREFPD.ICN ( lines:176 words:675 ) ----------------<cut here
dicrefpd sunburn 2 3 >e723 �Ƃ��܂��ƁA���ʂ͂����Ȃ�܂��B�m��Ȃ��P�ꂪ��R�łĂ��܂��B
-----^ E723 ( date:03-08-21 time:19:15 ) -------------------<cut here english.dic ��Ǎ����ł��B �J�n:19:15:50 �I��:19:15:59 english.dic �̓Ǎ����I���܂����B 257650 �ꂠ��܂����B sunburn ���A�ő啪���� 2�A�ŏ������� 3 �ɂĕ������āA���̑S�Ă������ɂ��邩�`�F�b�N���B �J�n:19:15:59 bunsnur -> buns nur bunsrun -> buns run bunsurn -> buns urn burnnus -> burn nus burnsun -> burn sun bursnun -> burs nun nubsnur -> nubs nur nubsrun -> nubs run nubsurn -> nubs urn nunsbur -> nuns bur nunsrub -> nuns rub nunsurb -> nuns urb nursbun -> nurs bun nursnub -> nurs nub rubsnun -> rubs nun runsbun -> runs bun runsnub -> runs nub snubnur -> snub nur snubrun -> snub run snuburn -> snub urn sunburn -> sunburn sunnbur -> sunn bur sunnrub -> sunn rub sunnurb -> sunn urb urbsnun -> urbs nun urnsbun -> urns bun urnsnub -> urns nub �I��:19:15:59 2592 �ʂ�̑g�����̂����A27 �ʂ肪�����ɂ���܂����B -----$ E723 ( lines:37 words:125 ) -------------------------<cut here
dicrefpd midnight 2 3 >e823 �Ƃ��܂��ƁA���ʂ͂����Ȃ�܂��B
-----^ E823 ( date:03-08-21 time:19:16 ) -------------------<cut here english.dic ��Ǎ����ł��B �J�n:19:16:14 �I��:19:16:22 english.dic �̓Ǎ����I���܂����B 257650 �ꂠ��܂����B midnight ���A�ő啪���� 2�A�ŏ������� 3 �ɂĕ������āA���̑S�Ă������ɂ��邩�`�F�b�N���B �J�n:19:16:23 dightmin -> dight min dightnim -> dight nim midnight -> midnight mightdin -> might din mightnid -> might nid mindthig -> mind thig nightdim -> night dim nightmid -> night mid thigmind -> thig mind thingdim -> thing dim thingmid -> thing mid �I��:19:16:26 60954 �ʂ�̑g�����̂����A11 �ʂ肪�����ɂ���܂����B -----$ E823 ( lines:21 words:61 ) --------------------------<cut here
�W�������S�����{�S�����ɕ������ꍇ�ɁA�����g�������Q�x�o�Ă��܂��Bmindthig -> mind thig �Ɓ@thigmind -> thig mind �̂Ƃ���ł��B����́A�Ƃ肠�������Ȃ��������ƂɁB�i���j
dicrefpd heavyrain 2 4 >e923 �Ƃ��܂��ƁA���ʂ͂����Ȃ�܂��B
-----^ E923 ( date:03-08-21 time:19:17 ) -------------------<cut here english.dic ��Ǎ����ł��B �J�n:19:16:40 �I��:19:16:48 english.dic �̓Ǎ����I���܂����B 257650 �ꂠ��܂����B heavyrain ���A�ő啪���� 2�A�ŏ������� 3 �ɂĕ������āA���̑S�Ă������ɂ��邩�`�F�b�N���B �J�n:19:16:48 aviaryhen -> aviary hen hairynave -> hairy nave hairyvane -> hairy vane hairyvena -> hairy vena havenairy -> haven airy haverayin -> haver ayin hayervain -> hayer vain hayervina -> hayer vina heavyairn -> heavy airn heavyrain -> heavy rain heavyrani -> heavy rani hieranavy -> hiera navy hyenariva -> hyena riva hyenavair -> hyena vair invaryeah -> invar yeah naiverhay -> naiver hay naiveryah -> naiver yah navierhay -> navier hay navieryah -> navier yah nerviayah -> nervi ayah rainyhave -> rainy have ravenhiya -> raven hiya ravinehay -> ravine hay ravineyah -> ravine yah ravinyeah -> ravin yeah rayahnevi -> rayah nevi rayahvein -> rayah vein rayahvine -> rayah vine rivenayah -> riven ayah vahineray -> vahine ray vahinerya -> vahine rya vahineyar -> vahine yar vainerhay -> vainer hay vaineryah -> vainer yah veinyhaar -> veiny haar viharanye -> vihara nye viharayen -> vihara yen vinerayah -> viner ayah vineryaah -> vinery aah vineryaha -> vinery aha �I��:19:17:21 545145 �ʂ�̑g�����̂����A40 �ʂ肪�����ɂ���܂����B -----$ E923 ( lines:50 words:178 ) -------------------------<cut here
���̏ꍇ�A545145 �ʂ�ŁA�R�R�b�������Ă��܂��B�@����ɂP�����̞B���������ł���悤�ɂɂ���ƁA�P���ɍ��Ɓ@�Q�U�{������v���O�����ɂȂ肻���ȋC�����܂��B�Q�����̞B�������ɂ���ƁA�X�ɂ��̂Q�U�{�H�B������������̂ł�����A�������������{�I�ɍl�������������ǂ������ł��Bheavyrain�̗�ł��ƁA'a'���Q�A'ehinrvy'�̊e�������P���̒P��������͒P��̑g�����������ɂ��邩�H�@�Ƃ������ŁA��@�͐F�X����Ǝv���܂��B
�X�����̕�����łT�S���ʂ�Ƃ����ƁA�����P�ꐔ�Q�U������z���Ă��܂��̂ŁA����ȏ�̕�������ΏۂƂ���ɂ́A�������l�������������ǂ����낤�Ǝv���܂��B���̃v���O�����̍H�v�ł������Ȃ�Ƃ͎v���܂����B�@���邢�́A�}�V���𑬂����ɂ����胁�����[���݂���Ƃ����������܂����A�旧���̂��D�D�D
���炭�AIcon�����Ă��܂���ł������A�ʔ�����ނ���Ē��������A�ŁA���� Icon�̃��n�r�����ł��܂����B���肪�Ƃ��������܂��B
Icon�́A���̑�ނ̂悤�ȕ������������܂킷�����̂��߂ɍ��ꂽ����ł��B���������������ɂȂ�����������������A���ꂵ���ł��B
���A���эN�v/�Γc�p�h/���Y���P�ҁA�Γc�p�h/���Y���P����A�u�t�[�R�[�E�R���N�V���� 3 �����E�\���v�A�}�����[�A�����܊w�|�����t 12 4�A2006�N7��10����1�ő�1��(DITS ET ECRITS, Editions Gallimard, 1994)�A460�y�[�W�A1400�~�AISBN4-480-08993-4�B
�u�s�J�\�E���f�B���A�[�j�̎���v�������A��ɁA�v���U��ɂ�����6F�̋I�ɍ������X�Ɋ��B�o�����Ƃ͒m���Ă�������A���ǁA�w���B�����A�ŋ߂̘b��Ɋ֘A����d�v�������s�b�N�A�b�v���Ă������B
---�������A���̌\�N�ȏ�O����A�L�q�Ƃ����d�������j�w�A�����w�A����w�̂悤�ȗ̈�ł͖{���I�Ȃ��̂ƂȂ��Ă����A�Ƃ������Ƃ͒m���Ă��܂��B������ɂ��Ă��A�K�����I�ƃj���[�g���ȗ��A���w�I����́A���R�̐����Ƃ��Ăł͂Ȃ��A�v���Z�X�̋L�q�Ƃ��ċ@�\���Ă���̂ł��B���j�w�̂悤�Ȍ`��������Ă��Ȃ��w��ɑ��āA�L�q�̊�{�I�ȔC�����s�����Ƃ��錠����F�߂Ȃ��Ƃ����̂͗����ł��Ȃ��B
---���̊�{�I�ȔC���Ƃ����̂́A���@�I�ɂ͂ǂ̂悤�ȕ����������̂��Ƃ��l���ł���?
---���ɁA�����A�킽�������������Ƃ���������A�킽��������Ȃ��������e�N�X�g���A�K�v�ȕό`�������A�����}���ɂ��������Đ��m�ɐ����E���͂ł���͂����Ƃ������ƁB
���ɁA�킽�������y�������e�N�X�g�Ƃ킽������舵�����f�ގ��̂ɑ��Ă��A������������ݒ�������A�ʂ̃����F���Ɉʒu����悤�ȋL�q���ł��邱�ƂɂȂ�܂��B�Ⴆ�A���j�w�I�m�̍l�Êw���s�����Ƃ���Ȃ�A���R�A���ꊈ���ɂ��Ă̏��e�N�X�g��V���ɗp���Ȃ���Ȃ�Ȃ��ł��傤���A�������A���߂⌹��ᔻ�̈�A�̃e�N�j�b�N��A�����Đ����Ɨ��j�I�`���ɂ�����邷�ׂĂ̒m�ƊW�Â��Ȃ���Ȃ�Ȃ��ł��傤�B���̎��A���ꊈ���ɂ��Ă̏��e�N�X�g�̋L�q�͈�������̂ɂȂ�ł��傤�B�������A�����̋L�q�́A���ꂪ���m�Ȃ��̂ł���A����L�q����ʂ̋L�q�ւƈڍs���邱�Ƃ��\�ɂ��Ă����ό`���`���邱�Ƃ��ł���悤�Ȃ��̂ł���͂��Ȃ̂ł��B
����Ӗ��ŁA�L�q�͂��������Ė����ł����A�܂��ʂ̈Ӗ��ł́A�����ΏۂƂȂ鏔�����̂������ɑ��݂��鏔�W��������邱�Ƃ̂ł��闝�_�I���f�����m�����悤�Ƃ������ɂ����āA�L�q�͕����Ă�����킯�ł��B(�~�V�F���E�t�[�R�[���A�u�t�[�R�[�E�R���N�V���� 3 �����E�\�ہv�A�}�����[�A2006�N: 86�y�[�W�A�u3 ���j�̏������ɂ��āv�AR�E�x���[���Ƃ̑Βk�A1967�N)
���̕����́AClosed world machine���ǂ̂悤�ɐ������邩�m�ɏq�ׂĂ��邪�A���̂悤�Ɉӎ��I�Ƀe�N�X�g��ǂނ̂͑�ς��낤�Ǝv���B���R����e�N�X�g���v���O�����̃R�[�h��H��悤�ɓǂނƂ����̌������Ă݂�̂������[����������Ȃ��B�Βk�́u���t�ƕ��v�ɂ��čs���Ă���B��͂�u���t�ƕ��v��ǂ܂˂Θb�ɂȂ�Ȃ��B
�~�V�F���E�t�[�R�[�͎��̂悤�ɂ������Ă���B�����A���ꂩ��40�N���o�߂��悤�Ƃ��Ă���̂����E�E�E
�E�E�E�Ƃ��ɘ_���w�҂̑��A���b�Z���⃔�B�g�Q���V���^�C���̒�q�����̑��ł́A���ꊈ���͂��̋�̓I�ȓ������l���ɓ����̂łȂ���A�`���I�����ɂ����ĕ��͂��邱�Ƃ͂ł��Ȃ��Ƃ������Ƃ��C�Â���n�߂Ă��܂��B
����̌n �͏��X�̍\���̑��̂ł��B�������A�����̕��͓����̒P�ʂł���A���ꊈ����S�̂Ƃ��ĕ��͂��悤�Ƃ���Ȃ�A���̂悤�Ȗ{���I�ȗv���ɕK�����ʂ���������Ȃ��B�E�E�E(��99�y�[�W)
����Ɂu���E�̎U���v�Ƃ����u���t�ƕ��v�̑�2�͂̂��ƂɂȂ����e�N�X�g������p���Ă������B�n�C�p�[�����N�A�n�C�p�[�e�L�X�g�Ƃ͉������l��������B
�������̋L�������Č�点�A���̈Ӗ��̔������\�ɂ���悤�Ȓm����Z�p�̑��̂��A���ߊw�ƌĂڂ��B����A�ǂꂪ�L���������ʂ��A�����̋L�����L���Ƃ��č\�����Ă�����̂��K�肵�āA�L���ǂ����̊֘A��A���̖@���̔F���ւƓ����Ă����悤�Ȓm����Z�p�̑��̂��A�L���w�ƌĂԂ��Ƃɂ��悤�B���������ꍇ�A�\�Z���I�Ƃ́A���ߊw�ƋL���w�Ƃ��Ƃ����`�Ԃ̂����ɏd�ˍ��킹�Ă�������Ȃ̂ł������B�Ӗ���T�����ƁA����͗ގ����𖾂�݂ɏo�����Ƃ������B�E�E�E�E�E(��64�y�[�W�A�u���E�̎U���v�A1966�N)
�^�O�t���Ƃ͉����Ƃ������ƂɂȂ�B����A�n�C�p�[�����N���ގ����̈��p�Ȃ̂ł���B����ȏ�͂����Ŏ~�߂Ă������B�����ɖ{������������Ă���B���̖{�����E�E�E�悭�l���Ă݂Ȃ��ƁB
������(�n�}�ƃK�C�h�u�b�N�̏�����)�̂������͋ɂ߂ĊȒP�ɓ��L�ɖ��ߍ��ނ��Ƃ��ł���BGoogle Video�̃����N�ȂǂƓ����v�̂ŁA�������ꂽ�����N��HTML�ɓ\��t���邾���B
���́A�N���b�N���ĕ\�������n�}�ɏo��}�[�N�̐������ɃT�C�g�������I�ɃN���[�����ď���ȃ����N�邱�ƁB���낢��n�}��u���ʒu��ς��Ă݂����A�u���[���X�E�u�����V���v�̋L���Ƀ����N�������Ă��܂��B
Google Maps�͒N�����g����킯�ł͂Ȃ����ǁA�Ǝ��ɗl�X�ȍH�v���Â点��̂��悢�B�������͒n�}���킩��₷���Ƃ��������b�g������̂ŁA����g���₷���d�l�ɂ��Ăق����B
toggleVisibility��Google Maps API��ver.2�̑g�ݍ��킹�����܂������Ȃ��̂ŁA�������ȂƎv���Ă����̂����A�����A�X�N���v�g���Č������Ă���ƁAGLatLng��GlatLng�ɂȂ��Ă���̂ɋC���t����(^^;)������Ɠ����n�߂��B
�ȑO��API ver.1���g���Ă���L����ver.2�ɏ�����������Aver.2�����܂������Ȃ��̂ō��܂��Ă����ʐ^�ƒn�}��A��������Microformat(viewpoint)�̓�����Ƃ��J�n�����Bver.2�͉q���摜�\�����g����̂ŁA�f���炵���B�����A����A��ɕ{�t�߂̒n�}���������A��B���������ق��L�ڂ���Ă��Ȃ��B�����n�}�͌Â����A�킩��ɂ����������B
���[���ߑ���p�ُ����̊G��𒆐S�Ƃ����W����ŏI���B�Ђ낵�ܔ��p�فB
�܂��A���͏��Ȃ��������A�s�J�\��f�B���A�[�j�����爫���낤�͂��͂Ȃ��B���������Ƃ��Ȃ���Ƃ̍�i������A�߂��炵���ȂƂ������̂��������B�������O�͂킷�ꂿ��������B�Ђ낵�ܔ��p�ُ����i�Ő������̊����B�Ђ낵�ܔ��p�ق̓��ӕ���ł����邩��A���R���B��ݓW�́A�W����ɔ������������A�������Ƃ̂Ȃ��ʂ̏����i����������o�Ă���A���m�A�[���̕��i��2�_�ƃr���t�F�̐Ԃ��Ƃ��ڂ��������B
 �s�J�\�E���f�B���A�[�j�̎���
�s�J�\�E���f�B���A�[�j�̎���Google Maps API��troubleshooting�����āA���낢��Ɗ���ς���Ȃǂ��Ă݂����ǁAIE 6�ł͒n�}��\���ł��Ȃ��BFirefox�ł͕\���ł���B
���[���X�E�u�����V���ɂ��āA�����������������B
�Ō�̍�ƁA�Ō�̐l �~�V�F���E�t�[�R�[�̓u�����V�����u�Ō�̍�Ɓv�ƌĂB�u�����V�������́A�����Ȃ����I��Ԃɂ��Ҍ��ł��Ȃ����́u���w��ԁv���A���m���w�̂��ׂĂ̑��i(�Ƃ�킯�\��A��\���I�̍�i)�ɂ��Ĕ�ނȂ��݂��ƂɌ�邱�Ƃ�ʂ��āA����I�Ɉʒu�Â����l�ł���Ƃ����̂��B���̈Ӗ��ŁA�u�����V�������m���w�̗��j�ɑ��Ă͂����Ă�������́A���m�̃��^�t�B�W�b�N�̗��j�ɂ����ăw�[�Q�����͂���������ɂ�����ƁB
�������A�ƃt�[�R�[�͌����A�w�[�Q�����L���ɂ���Đ��E�j�̂��ׂĂ���݉��A�Č��݉����邱�Ƃ�ނ̓N�w�̌����Ƃ����̂ɑ��A�u�����V���͂��̑��G�_�ɂ���B���w��i�̌���A�����Ĉ�ʂ�
�� �Ƃ������̂��A����̂�<�O>�ł���Ƃ������ƁA�p���[�������Č�炵�߂���́A������̌����Ȃ��������Y�p�ɂق��Ȃ�Ȃ��Ƃ������Ƃ��u�����V���͎��X�ɁA�N��Ɏ����Ă���̂��B(���[���X�E�u�����V�����A�L������A�u�Ō�̐l/���� �Y�p�v�A1971�N�A������: 289�y�[�W�A��҂��Ƃ���)
��҂̖L����ꎁ�͂����ԑO�ɖS���Ȃ�ꂽ�̂��Ȃ��B���E�N���W�I�̖�҂Ƃ��Đe���݂��������̂����B�X���[�����[���h���o�R���ē��c���搶�̌������ɓ���B�t�����X���w�Ȃ���ŁA����A�L�����Ō������āA�b���ʂ̂Ƃ���ɗ��Ă��܂����B���N���u�����V�����a100�N�Ȃ̂��BRSS/Atom���}�[�N���āA�����l����B����ŁA�w�[�Q���͂ǂ��ʒu�Â���̂��B
�����ꂽ�e�L�X�g�ɓ��݂��Ă��鏬���Ȑ܂���Ԃ͎��X�ɊJ����Ă����B�A�z����Ԃ̔����J���̂��B�A�z�Ƃ́A���Ȃ킿��N���ꂽ�L���ł���B�e�L�X�g���Ӗ������̂́A�ӎ�-�L���Ƒ��ݍ�p����ߒ��ɂ����Ăł���A������Ă��邻�̂��̂��Ӗ������̂ł͂Ȃ��B�Ӗ��̓e�L�X�g��ǂސl�̈ӎ�-�L���̒��ɐ�������̂ł���B
�u��(�p���[��)�Ƃ������̂��A����̂̊O�ł���v�Ƃ������Ƃ͂��̂悤�ȈӖ��ɂ��v���邪�A�����m�M�������Č����郌�x���ł͂Ȃ��悤�ȋC������B�Ȃ��A�u�p���[�������Č�炵�߂���́A������̌����Ȃ��������Y�p�ɂق��Ȃ�Ȃ��v�̂��B�����������낢��Ɠǂ�ł݂悤�B�w�[�Q���I�Șb�͒����I�ɂ悭�킩��b�ł���A�u�l�Ԑ��E�̓����}�v�I���E�ς͗ގ��������̂��낤�B�u�����V���́A�I���g���W�[�I���z�Ő��E���c���ł���͂����Ƃ����y�ϓI�Ȍ����ɑ��āA�ًc�������Ă���ƌ����邩������Ȃ��B
�u����t�����X�����j�v���班�����p���Ă������B
����́A���ꂪ���Â�����̂�ے肷��B�u�����A���̏��A�ƌ������邽�߂ɂ́A�����ꂩ�̂����ŁA�������̏����炻�̍��Ɠ��̌�����D������A���ǂ��̏��������ɑ��݂��Ȃ����̂Ƃ��A���̏��E���Ȃ���Ȃ�Ȃ��B��������
�� �͎��ɑ��݂���������B�������� �͎��ɁA�����I�ȑ��ݐ���D��ꂽ���̂Ƃ��Ă̑��݂���������ɂ����Ȃ��̂��B������A���݂Ƃ́A���̑��݂̔�݂��̂��́A���̑��݂̋����A���̑��݂��^�̎��ݐ����������Ƃ��ɂ����Ɏc����̂ɂ����Ȃ��B����������A���݂��Ȃ��Ƃ����B��̎����ɂق��Ȃ�Ȃ��̂ł���B�v�����猾��Ƃ͔ے�ł���A�j��ł���B���ꂪ����̋@�\�̑��i�K�ł���B�������A���̒i�K�Ƃ��āA����͌���Ƃ��Ď������A����̎����݂̂������āA����͍m�肷��B���ꂪ���i�K�ł���B���ꂪ���B�����O�i�K�́A���̂������̂��̂����A�ے肷�邱�̍m��(����)�ƁA�m�肷�邱�̔ے�(����)�Ƃ���������B�܂��������ꂱ���́A����̂����{�I�ȓ�`���ł���A���ꂪ���w�̂����ɂ������ށs�ЂƂɊҌ��ł��Ȃ���d�̈Ӗ��t�ł���A�܂��Ƃ�I�ދ�Y�̍����Ȃ̂ł���B�u�����V���͕��w�̎��H�̂Ȃ��ɁA���ɓ��B���邱�Ƃ��s�\�Ȃ�����A���݂ɓ��B���邱�Ƃ��s�\���Ƃ������������o���悤�Ƃ��铭�������Ă���B�u���́v�Ɣނ͏����Ă���B�u�l�Ԃ̉\���ł���A�l�Ԃ̎��`�����X�ł���B�����́A���łɊ������Ă��܂������E�̖������c����Ă���̂́A���������Ă��B���́A�l�Ԃ����̍ő�̊�]�ł���A�l�Ԃ����Ɏc���ꂽ�B��̊�]�ł���B�v(���[���X�E�i�h�[���A�c�_��Y��A�u����t�����X�����j�v�A�݂������[�A1976�N: 157�y�[�W�A�^�╄��ł��ꂽ�����A���[���X�E�u�����V��)
�ǂ߂Γǂނ����A�V���ȋ^��ނ��A�e�L�X�g�𗝉����邱�Ƃ́A����ȂɊȒP�Ȃ��̂ł͂Ȃ��B�I���g���W�[�̍���͂����ɂ���B�����̏ꍇ�́A���ɋ��\�ł��邱�Ƃ��O��Ȃ̂ŁA�����I�ɖ�������Ă���ƌ����邪�A�m���t�B�N�V�����Ƃ����O�������Ƃ��Ă��A���������邪�܂܂Ɍ���ɒ蒅�ł��邩�Ƃ����ƁA����͓��l�̌����ŗ����邾�낤�B
�����ŁA�l�Ԑ��E�̓����}�鎎�݂́A���_�A�l�Ԑ��E�̒m���̒n�}�悤�Ƃ�����]�ł���A�ŏI�I�ɂ͒m���̋��L���A���̕\���Ƃ��Ă�RDF/XML���ɂ߂悤�Ƃ��������Ɍ��ѕt�������ƍl���Ă���B�^�O�t���A���邢�̓I���g���W�[�I�����́A��A���邢�͘A��A���߁A���邢�͕��A���邢�͒i���A���邢�͏��߁A�́A�����ꂽ���̑S�̂ɑ��čs���邾�낤�B�������A�Ȃ��^�O�t�����s���K�v������̂��B���X�AMachine-readable�ɂ���Ƃ��������I�ȖړI������B�ǂ̂悤�Ɏg���̂��A���������������̂��ɂ���āA�^�O�̕t�������͕ς���Ă��邾�낤�B
���̂Ƃ���AWeb�ɂ�����m���\���ɂ�����v�V�I�ȃA�C�f�A�́AHTML�ɂ��n�C�p�[�e�L�X�g�����ł���B�d�q�I�Ȉ��p�ɂ���Č����������ǂ���ɕ\����������A�����Ăяo�����Ƃ��\�ɂȂ�BRSS/Atom�̂悤�ȋL���̍\���v�f�ƃf�[�^�x�[�X�����ӎ�����id�v�f�Ȃǂ̃^�O�̕t�^�́A�e�L�X�g���f�[�^�x�[�X�������Ƃɑ��Ȃ�Ȃ��B�����炭�����I�ȃe�L�X�g�̃f�[�^�x�[�X�͑��w���邢�̓��U�C�N�̍\���������̂ɂȂ�Ɨ\�z�����B
���S�ɒ�`���ꂽ�f�[�^����舵���Ȃ�]���̃f�[�^�x�[�X�Z�p���g���悢�̂ł͂Ǝv���B���͒P��RDF/XML�ƃf�[�^�x�[�X�̑��ݕϊ��̂悤�ȋZ�p�ɋA������B�����b�g�͋K�i�����ꂽ�f�[�^�̑��ݗ��p�Ƃ������ƂɂȂ�B�����ōl���悤�Ƃ��Ă���̂͂����ƕʂ̎����̘b�ŁA�Ⴆ�A�e�L�X�g�t�H�[�}�b�^����̘A�z�ł���A�e�L�X�g���͗��Ă��ēǂ݂₷���悤�ɐ��`������A�C���f�b�N�X��ڎ��������I�ɐ��������肷�邾���łȂ��A�e�L�X�g�̍\���v�f�������f�[�^�x�[�X�����A����ɂ́A�ǎғƎ��̉��߁E���z�E���E�x�A�Ⴆ�A�Z�C�S�[�}�[�L���O�I�Ȃ��̂������f�[�^�x�[�X�����A�R���s���[�^��ŕ\���ł��Ȃ����Ƃ������Ƃł���B�v���O���~���O�����}�[�N�A�b�v�����ʂ��āA���R����͕ϗe���鎞��ɓ������悤�Ɏv����B�t�[�R�[(�~�V�F���E�t�[�R�[ - Wikipedia)���C���^�[�l�b�g��m���Ă�����ǂ̂悤�ɗ��j�I�Ɉʒu�Â��Ă����낤�Ǝv���B
�����Ȃ���A���ׁA���ׂȂ���A�����B�����Ă��邤���ɁA��x���������Ƃ��ŏ��̈Ӑ}�Ƃ͕ω����āA�ŏ��Ƒ啝�ɈႤ�Ӗ��ɂȂ��Đ��܂�ς�邱�Ƃ�����B���̂悤�ɂ��āA���̓��L�̋L���͏����Ă��邩��A�X�V���ꂽ�L���̈Ӗ����ς���Ă��邱�Ƃ�����͂��ł���B�������e�o�[�W�������ۑ����Ă����̂��Ӗ������邩������Ȃ��BAtom�ł�id�v�f������entry�v�f������ꍇ�ɂ́Aupdated�v�f��ς��Ă����悢���ƂɂȂ��Ă���B
�B�e�n�_�����f�W�^���J�����ŎB�e�Ɠ����ɉ摜�t�@�C���ɖ��ߍ��߂�A���ꂪ�x�X�g�����A���肻���łȂ��Ȃ��Ȃ��B�����炭�[���Ȑ��\���o�����Ƃ�����̂��낤�BGPS�ő��n���邱�Ƃƍ����ŃV���b�^�[��邱�Ƃ͑������邱�Ƃ����炾�B���R�[ Caplio Pro G3 - ���r���[ - CNET Japan�B���ꂪ���̂Ƃ��댻���I�Ȑ����ȁB�������A�c�O�Ȃ��獂���ł���B
Exif�ɂ�GPS�f�[�^���������߂�B�f�W�J���̂����̂������Ă���AGPS�̃f�[�^�����ԏ����L�[�ɂ��ĉ摜�t�@�C���ɏ������ނƂ���������邪�A�ړ����x�Ǝ��v�̐��x�����ɂȂ�炵���B
�}�[�J�[�̈ʒu���w�������ʒu���T�e���C�g�摜�ł͒n�}�̈ʒu�ɑ��ē��ɂ����Ԃ���Ă���(�T�e���C�g�摜���n�}�ɑ��Đ��ɂ���Ă���)�B�����ԂƂ����Ă��A1�b�����̂��ꂾ�Ǝv�����B�n�}�ł͐�݂̊��肬����w���Ă���}�[�J�[���q���摜�ł͐�̒��ɗ����Ă���B
Image::ExifTool - Read and write meta information - search.cpan.org�l�^�B[Podcast] �����I����(�n�[�h�E�F�A)�H���̑����B
Image-ExifTool�̃h�L�������g�ɂ���T���v�����g���āA�f�W�J���̉摜�t�@�C����EXIF�f�[�^�𒊏o���Ă݂��B�ȒP�BActivePerl�ł�ppm�ŃC���X�g�[���ł���B
C:\Program Files\MySync Photo2 �̌��� for A5403CA\BAlbum\2004\7>perl c:\anhttpd\ cgi-bin\imageexif.cgi 040703_1316~0001.jpg ---- ExifTool ---- ExifTool Version Number : 5.32 ---- File ---- File Name : 040703_1316~0001.jpg File Size : 22KB File Modification Date/Time : 2004:07:03 13:16:58 File Type : JPEG Image Width : 240 Image Height : 320 ---- EXIF ---- Image Description : 040703_1316~0001 Make : KDDI-CA Camera Model Name : A5403CA Orientation : Horizontal (normal) X Resolution : 72 Y Resolution : 72 Resolution Unit : inches Y Cb Cr Positioning : Centered Shutter Speed : 0.4 Exif Version : 0220 Shooting Date/Time : 2004:07:03 13:16:58 Components Configuration : YCbCr Flash : Off Flashpix Version : 0100 Color Space : sRGB Exif Image Width : 240 Exif Image Length : 320 Custom Rendered : Normal Exposure Mode : Auto White Balance : Auto Digital Zoom Ratio : 1.25 Scene Capture Type : Standard ---- PrintIM ---- Print IM 0x0001 : 0x00120012 Print IM 0x0002 : 0x01000000 Print IM 0x000e : 0x0000004c Print IM 0x0101 : 0xff000000 Print IM 0x0102 : 0x84000000 Print IM 0x0103 : 0x83000000 Print IM 0x0104 : 0x80000000 Print IM 0x0105 : 0x83000000 Print IM 0x0106 : 0x83000000 Print IM 0x0107 : 0x80808200 ---- Composite ---- Image Size : 240x320 Shutter Speed : 0.4
�����������Icon�u���B
�� TSfree �� Icon�~�j�u���S�i�t�B���^�[�j�@�@������
����́A�������̕����a�ւ̕����ŁA���\�Ȑ��̃p�^�[������������܂��̂ŁA����ɐ������|���܂��B�@�������̐����ƍŏ����̐�����t������悤�ɂ��܂��B
�O��� n_divd.icn �ɐ�����t���鏈����lj����Ă��ǂ��̂ł����A�~���݂̂̐�����t���邾���Ō��\�ʓ|�����̂ŁA�X�ɏC������C�͋N���܂���B
�����ŁAn_divd.icn�͂��̂܂܂ɂ��āAn_divd���Ăԕ��Ő�����t���悤�Ǝv���܂��B
����v���O�����̏������ʂ��A�ʂ̃v���O���������H���āA�X�ɕʂ̃v���O�����ɓn�����Ƃ��A�t�B���^�[�ƌ����܂��̂ŁA���� procedure���A�t�B���^�[�ƌ����ėǂ��Ǝv���܂��B�@����Ȋi�D�̍\���ł��B
+----------------+ +--------------+ +--------------+ | n_divd | | n_divdf | | main | | �������������� | ---> | ���������� | ---> | ���ʂ��g�p | | | | �ŏ������� | | | | | | �t�B���^�[ | | | | generator | | generator | | | +----------------+ +--------------+ +--------------+
-----^ N_DIVDF.ICN ( date:03-08-20 time:23:48 ) ------------<cut here
####################
# �����������@�������E�ŏ��������t��
####################
# n_divdf.icn Rev.1.0 2003/08/20 windy ������ H.S.
####################
# Usage n_divdf ������ �ő啪���� �ŏ���
# �^����ꂽ�������a�ɕ�������B���ʂ͍~���̕����̂݁B
# ��:5->[5],[4,1],[3,2],[3,1,1],[2,2,1],[2,1,1,1],[1,1,1,1,1]
# ���̒��ŁA�ő啪�����A�ŏ����̐����ɍ������̂��o�͂���B
# This file is in the public domain.
procedure main(args)
Usage := "n_divd ������ �ő啪���� �ŏ���"
if *args < 1 then stop(Usage) # �R�}���h���C��������������� Usage�\��
if args[1] < 1 then stop(Usage) # �����łȂ���� Usage�\��
n := args[1] # ��default�͂Ȃ�ׂ������p�^�[�������Ȃ��Ȃ�悤
ndiv := \args[2] | 1 # default�̍ő啪�����́A�P�i���������j
nmin := \args[3] | *n # default�̍ŏ����́A��������鐔���̂���
write(n," ���A�ő啪���� ",ndiv,"�A�ŏ��� ",nmin," �ɂĕ���")
# ������������ generator���珇�����ʂ����o��
every L := n_divdf(n,ndiv,nmin) do show_sl(L)
# ��list�̓��e��\������
end
####################
# ���������� generator
####################
# 5=3+2 ���ɐ�����������B���� procedure�� n_divd���Ăуt�B���^�[���|���Ă���B
# �����p�^�[�����������鎞�ɁA�����������邽�߂Ɏg�p�B
# arg [1]: �������錳�̐�
# [2]: �ő啪����
# [3]: �ŏ���
# value : list
procedure n_divdf(r,ndiv,nmin)
every L := n_divd(r) do { # r �̕������ʂ����o��
if *L <= ndiv then { # �������`�F�b�N�ilist�̃T�C�Y�`�F�b�N�j
if L[*L] >= nmin then suspend L # �ŏ����`�F�b�N�i�~���ɓ����Ă���̂�
} # �����̗v�f���`�F�b�N�j
}
end
####################
# ���������� generator
####################
# 5=3+2 ���ɕ�������B�����͍~���̂����B�i�� 5=2+3�͏��O�j
# arg [1]: ��������錳�̐��i�ċA�̏ꍇ�́A�O�̏����̗]��j
# [2]: �ő吔 �i5=2+2+1 �̏ꍇ�ɁA�ŏ��� 2�̎� 3���]�邪�A�ċA���� 3��
# �������n�߂鎞�A3����ł͂Ȃ� 2����n�߂邽�߂̍H�B�~���蓖�B�j
# value : �������ʂ̐��Blist�Ɋi�[
# Usage : every L := n_divd(r) do ...
procedure n_divd(r,max)
/max := r # �w�薳���́A��������錳�̐����̂���
if r < 1 then fail # �O�̂���
if r = 1 then return [1] # �ċA�I��
# r >= 2 �̏ꍇ
if r > max then rs := max # �����i��苎��j���̍ő吔�̐ݒ�B
else rs := r # ��������鐔�� �ő吔�w��� ��������
every i := rs to 1 by -1 do { # ��L�w�萔�`�P���A���Ɂ|�P���Ȃ���
rr := r -i # �V���ȗ]��
if rr = 0 then suspend [i] # �]�肪�������
# �]�肪����A�ċA����
else if rr > i then suspend [i] ||| n_divd(rr,i) # �]�肪�傫�߂��鎞
else suspend [i] ||| n_divd(rr)
}
end
# �ȉ��́AIcon����u�����
####################
# list�� ���e�\��
####################
# arg : list
# value : null
# Usage : show_sl(L)
# �ŏI�I�� string�� number���v�f�ł��邱��
# Icon����u���i�P�R�j,Icon����u���R�i�P�T�j
procedure show_sl(list)
# list�̓��e�\���itest�^�\���p�j
every writes(" ",!list)
write()
return
end
-----$ N_DIVDF.ICN ( lines:86 words:320 ) ------------------<cut here
n_divdf 9 3 3 >eee�@�Ƃ���ƁA���ʂ͂����Ȃ�܂��B�@�����A�������t�����܂��ˁB
-----^ EEE ( date:03-08-21 time:00:00 ) --------------------<cut here 9 ���A�ő啪���� 3�A�ŏ��� 3 �ɂĕ��� 9 6 3 5 4 3 3 3 -----$ EEE ( lines:5 words:13 ) ----------------------------<cut here
���āA����́A�܂Ƃ߂ł��B
�t�[�R�[�́u�m�̍l�Êw�v�ƃg�t���[�v�Ȃ́u�x�̖����v�����������ɁA���j��k�邱�ƂɂȂ����B�l�Ԑ��E�̎���̓����}��`���Ă݂邱�ƁB���ꂪ�A�ŏI�I�ȓ��B�_�ł���B
�O���n���E�n���R�b�N�́u�_�X�̐��E�v�ŁA1�`2���N�O���炢�̒n�k�ϓ����A�l�ޕ����̔��˂֗^�����e���ɂ��čl�������A�V�l�ނ̐����w�E�l�Êw�I�ȗ��j��20���N���k��B���l�ނ��܂߂��700���N�̐i���̗��j�������B����ȑO�ɂ�46���N�̒n���̗��j������킯�����ǁA����ǂ��납�A�l�ނ̔F���́A�F���̌�������I�ǂ܂ł��`���o���A��X�̏Z�މF���͕��s�F���̈�ɉ߂��Ȃ���������Ȃ��Ƃ����l�Ԃ̌��E���z�����̈�ɓ˓����Ă���B
���͂����Ɛg�߂ȕ����Ȍ�̐l�Ԃ̗��j�A�t�[�R�[�̌����J���g�ȑO�Ȍ�̐����̗��j�B����̓t�[�R�[�̑��̒���ׂ�Ƃ��납��n�߂邱�ƂɂȂ邾�낤�B�Ȃ��A����̂悤�Ȃ��ƂɊS�����̂��A�悤�₭�����Ă����B�������A����͐����̗��j�Ɩ��ڂɊW������A�����l�łȂ��ƌ����ɂ����b�̂悤�ȋC�͂��Ă���B�J���g�ȑO�Ȍ�͗��j�I�ɂ͑��̔g�̔����O��ƑΉ����Ă���悤�ɍl�����A���̂悤�Ȏ��_����t�[�R�[�̒�������Ă݂����B
�l���Ⴂ���́A��O�A�풆�A���Ƃ������t���悭�g��ꂽ�B����E���̈ȑO�Ȍ�Ő�����čl����ꂽ�B�u�푈��m��Ȃ��q�������v�Ƃ����t�H�[�N�\���O���̂�ꂽ��A�햳�h�Ƃ������t���o�������B���̃C���[�W������O�̂��Ƃ͖Y��āA����ɐ��ɂ��čl���邾���ł�������Ȃ��Ƃ����X���ɂȂ��Ă������B���ہA���j�̎��Ƃ͂���Ȃ�ɂ������납�������A���������]�ˎ��オ�ǂ��ł��낤�ƌ���Ƃ͊W�Ȃ��Ǝv��ꂽ�B
�����ɂ��ẮA�t�[�R�[�̎v���̓���H�邱�Ƃł悢���낤�B���s���āA���{������B����͂܂��ǂ̂悤�Ɍ���悢�̂��킩��Ȃ��B�i�n�ɑ��Y��ǂ߂q���g��������̂�������Ȃ��B�{�V�搶�͓s�s���Ɣ�s�s���̌J��Ԃ��Ƃ����悤�Ȏ��_��������Ă���B�ÓT���n���I�ɓǂޕK�v������̂��낤�Ǝv�����肵�Ă���B�g�{�����Ȃǂ��낢��ǂ�Ŏ�|�����T�����B
�A�L�o�n!�d�]��ԃJ�E�{�[�C�Y��Podcast��TSNET�Œm���Ă���A���낢��Ȃ��Ƃ��l�����B�ނ�̂悤�ȎႢ�l���������{�ɂ��邱�Ƃ͑f���炵�����Ƃ��Ǝv���B�ނ�̂������̓x�[�}�K��C�}�K�̓��e�����ł���B�����Web�őh�点�A�V�������̂ݏo�������͂ɂ��悤�Ƃ����킯���B���ꂪ�d�]��ԃJ�E�{�[�C�Y�T����Podcast�Ƃ����킯�B
�C���^�[�l�b�g�ɂ����NIFTY SERVE�̃t�H�[���������ނ̊�@���}���AWeb�ւ̈ڍs��z�肵�āATS Network�\�z��FGALTS�ŌĂт��������A�l�͊e�l�̃z�[���y�[�W�����ݍ�p����ɂ₩�ȃl�b�g���[�N������B����́A�t�H�[�����ł̐���オ��┚������(�������̋}���ȑ���)�ɂ���ďے������t�H�[�����ւ̃A�N�Z�X�̑�����C�u�����̗��p�x�ŕ]������NIFTY SERVE�����Ƃ͑���������̂̂悤�ɂ݂�Ȃ͊������炵���B
�l���C���^�[�l�b�g��m���Ďv�����̂́A�l�̕\���̎��R�x���i�i�Ɍ��シ�邱�Ƃł���B�t�H�[�����ł̔����́A���Ō����ΒP�Ȃ郁�[�����O���X�g�̃v���[���E�e�L�X�g�ɉ߂��Ȃ��B�R�~���j�P�[�V�����ɂ͓K���Ă��邪�A�\���ɂ͓K���Ȃ��B�\���̎��R�x���オ�邱�Ƃ́A�l�I�ɂ͂������肾�����߂ɖZ�����Ȃ�͂��ŁA�R�~���j�P�[�V���������낻���ɂȂ�͂����Ƃ����̂����̓ǂ݂ł���A�e�l�̃z�[���y�[�W������(���݂��ɎQ�Ƃ���)���Ƃ�����Ӗ��̃R�~���j�P�[�V�����ɂȂ�ƍl�����̂ł���BTS Networking�̃y�[�W�����̖��c�ł���B�ŋ߂ł́A�R�~���j�e�B��Planet�Ƃ����l�������o�Ă��邪�A�������肵���悤�Ȃ��̂������B���ł́ATSNETWiki�ɂ��ꂪ��������Ă���ƌ����邾�낤�B���[�����O���X�g+Wiki(+RSS)�Ƃ����̂�Web�̃R�~���j�e�B�ɓK�����`�Ԃƍl������B
�ĉj�Ђ�CodeZine�����e���ł���悤�ɂȂ��Ă���B���e�����̍Đ��𑣂��A�C�f�A�����ۂɓ����Ă���B�����A���\�����郁�f�B�A���A�x�[�}�K��C�}�K�Ȃǂ̎G�������Ȃ��Ƃ����ł͂Ȃ��̂ŁA���e������Ƃ����~�����z���邩�ǂ����͍ő�������������Ȃ��B�d�]��ԃJ�E�{�[�C�Y�ł��N���������Ă������A���f�B�A�����}�̂̎G������AWeb�Ɉڂ����Ƃ������ƂȂ̂��B������ēx��荞�����Ƃ������݂��n�܂��Ă���Bꎖ�����Z�����������A�ӊO�Ɛ�������̂�������Ȃ�(^^)
���T�������Ƃ����Ԃɔ�ы���B�������N�̔������߂�����A�����͂Ƃ������A����͗��Œ�d�����B�A��ɉ_�������ɔ��B���Ă���̂�������B�āA�ϗ��_�BPodcast���Ȃ���A��A�������B
IE 7�̓��{��Ń����C���X�g�[�����Ă݂����A�����N���E�N���b�N�Ń^�u�ɊJ�����y�[�W���J�����ƃ^�u���N���b�N����Ƃ�͂藎����BFirefox 2��1���C���X�g�[�����Ă݂����A�܂��g���@�\�������Ȃ��̂ō���B���ǃA���C���X�g�[���BGDS���p��ł�ver.4���C���X�g�[���������ƁA���{��ł�ver.3�ɖ߂�����ABecky!�̃��[���\�����ł��Ȃ��Ȃ����B�v���O�C����ver.4�p�ɂȂ��Ă��܂������炾�낤�B���{���ver.4���o��܂ʼn䖝���邩(^^;)
�d�]��ԃJ�E�{�[�C�Y�̘b�����ɂ��낢��Ǝc���Ă���BBtron�̘b�BVGA�P�[�^�C�̘b�BLisp��Java�̘b�B���T�y���݂��B���͉߂�����A�߂�����A�߂�����E�E�E
�A�L�o�n!�d�]��ԃJ�E�{�[�C�Y: [�ԊO��]�P�C�X�����J�E�{�[�C�T�K��l�� �����m�� ����l�^�B�b�̍����̎肪�����ƈႤ�^�C�~���O�ɂȂ�̂ɂ��������ɂ����̒��q�Œ��茞��P�C�X���B�Ƃ��Ƃ��Ō�͎����̃y�[�X�Ɋ������B���A���̌�ɁA�悤�₭�������낢�b���͂��܂����B
�s���̎��̕⊮�𑣂��悤�ȕ��͂̏������ɂ܂œ��ݍ���ŁA�\����͂����ă��^�f�[�^�����̎��������ł��Ȃ����Ƃ����͈̂�̍l���������A�ނ��뉽�̂��߂Ƀ��^�f�[�^�����̂��Ƃ����ړI�ɍ��킹���ق��������I���B������ǂ����p���邩�́A�܂��A�C�f�A�����邩������Ȃ��B�L���ȃA�C�f�A��RSS�̂悤�Ɉ���ݏo���Ȃ���A���y���邾�낤�B
���͂̏��������l����Ƃ����������́A���R������l����Ӗ��ł͏d�v�Ȃ��Ƃł���B�������A���R����̑��ݍ�p���͒�^�I�ȑ����������ݑ�����̂ł͂Ȃ����B����ǂ�ʼn���ǂݎ�邩�Ƃ������Ƃ́A�l�ɂ���Ĉ���Ă���B�ǂސl�̌o����m���Ȃǂɂ���Ă͗����ł��Ȃ��ꍇ�����邵�A�܂��A�A�z�ɂ���āA�[���Ӗ���ǂݎ�邱�Ƃ��ł���ꍇ������킯�ł���B�����ł͑��̕��ւ̃����N�����������ׂ���������Ȃ����A�V���ȕ�����������_�@�ƂȂ邩������Ȃ��̂ł���B������������A�ǂ肷�邱�Ƃ́A���̂悤�Ƀ_�C�i�~�b�N�Ȃ��̂ł���A�V���Ȑ��E�ݏo������A�َ������E�ɒʂ����������\�����߂Ă���B������x������悤�Ȏd�g�݂������d�v�ł���B
HTML��XML�̂悤�Ȍ����l�Ԃ����ݏo�����̂͂���Ӗ��K�R�Ȃ̂�������Ȃ��B�@�B�Ƃ̃R�~���j�P�[�V�����Ƃ����l���������邯�ǁA�ނ���A�@�B��}��Ƃ����l�ԓ��m�̃R�~���j�P�[�V���������~���ɂ���d�g�݂ɂȂ��Ă��Ă���̂ł͂Ȃ����B���^�f�[�^�̕t�^���@�B�I�ɂ��̂͂��܂�Ӗ����Ȃ��B��Ƃ��̂��̂�����������̂͂����̂����A�@�B�ɂ͂܂��Ӗ��͂킩��Ȃ��B�@�B�A���Ȃ킿PC�͐l�Ԃ̊g���ł���A�C���^�[�l�b�g�ł͊g�����ꂽ�튯��ʂ��āA�R�~���j�P�[�g���Ă���̂ł���B
�P�C�X���̋����̂��钆��]�搶�ɂ��ẮA�����H�ȑ�w�b�����Љ�b�o�C�I�j�N�X�w���b���� �]���Q�ƁB�A�z�L�����j���[�����l�b�g���[�N�ł��Ƃ����b�͂������낻�����B�������ׂĂ݂悤�B����]�搶�́A�~���X�L�[�ƃp�p�[�g�́u�p�[�Z�v�g�����v�̋���҂ł�����B
�����A��̎Ԃ��猩���鐣�˓��̓��X�͉����ɂȂ��N�₩�ȐF�ʂ����̊����ۗ������Ă���B���H�Z���^�[�ɓ��鋴�̏ォ��́A�v���U��ɐ��ꂽ��̉��Ŏl���̂ق��܂ł悭���ʂ���B�����ɉ��ޓ��͂Ȃ��B��������̂��ׂĂ��N���A�Ȏ��݊��������Ă���B�߂��炵�����i�����Ă���B�s�v�c�Ȋ��o�̒��ŁA�L���̒��ɍ��ݍ������Ƃ����͂������A���L���������ƂȂ��Ă͊��������Ƃ����L���������N���ł���B
�Ȃ���āA���炽�܂��āA�����������B�O����A�u���E�U��ŃV�X�e���̕ύX���ł���ق����֗����Ǝv���Ă������A�����̂��ʓ|�łق����炩���B�悤�₭���傱���傱���Ə����Ă݂��B
frame_edit.cgi : html�Ƃ����p�����[�^��html�t�@�C������^����ƊY���t�@�C����ҏW�ł���B�������Amain�t���[���ŕҏW����悤�ɁAmemol�V�X�e�����O��ŏ����Ă���B
#!/Perl/bin/MSWin32-x86-object/jperl.exe
require 'cgi-lib.pl';
&ReadParse(*in);
$html = $in{'html'};
$cgidir = $ENV{'CGIDIR'};
$docroot = $ENV{'DOCROOT'};
print <<TOP;
Content-type: text/html
<HTML>
<HEAD>
<TITLE>Frame�̕ҏW</TITLE>
<META HTTP-EQUIV="Content-Type" content="text/html; charset=Shift_JIS">
<link rel="stylesheet" type="text/css" href="/mystyle.css">
</HEAD>
<BODY>
<div class="emph">$html�̕ҏW</div>
TOP
print <<HEADER;
<form method="POST" action="$cgidir/frame_save.cgi/$html" target="main">
<textarea rows=30 cols=80 name="content">
HEADER
# �ҏW�t�@�C����ǂݍ���
if(open(IN, "<$docroot/$html")){
while(<IN>){
print;
}
close(IN);
}
# �ҏW�t�H�[���ŏI������ CGI �o�͂���
print <<FOOTER;
</textarea>
<br>
<input type="submit" value="�ۑ�">
<input type="reset" value="���Z�b�g">
</form>
</BODY>
</HTML>
FOOTER
frame_save.cgi : �ҏW���ʂ�ۑ����邽�߂�CGI�Atextarea�̓��e�����̃t�@�C���ɏ㏑���ۑ�����B�m�F�Ȃǂ͂Ȃ����A���s�������͖߂�{�^���Ŗ߂�Ώ����邩��(^^;)�m���߂鎞�̓o�b�N�A�b�v������Ă������ƁB
#!/Perl/bin/MSWin32-x86-object/jperl.exe
require 'cgi-lib.pl';
&ReadParse(*in);
$content = $in{'content'};
$cgidir = $ENV{'CGIDIR'};
$docroot = $ENV{'DOCROOT'};
$html = $ENV{'PATH_INFO'};
open(OUT, "> $docroot$html");
print OUT $content;
close(OUT);
print <<HTML;
Content-type: text/html
<HTML>
<HEAD>
<TITLE>Frame�̕ҏW�ۑ�</TITLE>
<META HTTP-EQUIV="Content-Type" content="text/html; charset=Shift_JIS">
<link rel="stylesheet" type="text/css" href="/mystyle.css">
</HEAD>
<BODY>
<div class="emph">$html�̕ۑ�</div>
<p>$html��ۑ����܂����B</p>
</BODY>
</HTML>
HTML
�������A�f�X�N�g�b�vCGI�̕ҏW�ɂ����p�\���B���������������Ɠ����ŁA����Ȋ����ŏ�����Wiki���ۂ����̂��ȒP�ɍ���͂����B
items.html�Ɏ��̂悤��CGI�ւ̃����N�������Ă����B
<a href="/cgi-bin/awakening/frame_edit.cgi?html=items_ff.html" target="main">Frame�ҏW</a>
�{�^���ŏ����i�D��t����Ȃ�A���̂悤�ɏ����B
<FORM action="/cgi-bin/awakening/frame_edit.cgi" target="main"> <INPUT type="hidden" name="html" value="items_ff.html"> <INPUT type="submit" value="Frame�ҏW"> </FORM>
 frame_edit.cgi���s���
frame_edit.cgi���s����A�L�o�n!�d�]��ԃJ�E�{�[�C�Y: ��\�l�� �����I����(�n�[�h�E�F�A)�H�� �O���A�A�L�o�n!�d�]��ԃJ�E�{�[�C�Y: ��\�܉� �����I����(�n�[�h�E�F�A)�H�� ����l�^�B
�o���҂̐��Ɩ��O���������킩��͂��߂����̍��Bkeith���āA�L�[�X�Ɠǂނ̂��Ǝv������A�P�C�X�Ȃ�ˁB�u��������ˁv�A�u�Ȃ�قǂˁv�Ƃ��������̎肪���Q�̃^�C�~���O�œ����ĉ����BPSoC�����ɂ��т�����B
�����A�d�q�H������Ă݂����Ȃ����ˁB�����E�w���v���O���~���O����ˁB5�N���炢�O���ȁA�v���O���~���O�ł��郍�{�b�g(MOVIT WAO�U)�c�t���ō�������ǁA�ǂ��ւ�������ȁB���z���Ŏ̂Ă���������B���ǃv���O���~���O�͂��Ȃ��܂܁E�E�E�����ȃC���^�[�t�F�[�X�J�[�h(IF-96)�܂ł͍�����̂�(;_;)���ׂĂ݂�ƁA�G���L�b�g�̐��i���E�E�E
���{�b�g������Ă����p�I�ɂ͂قƂ�LjӖ����Ȃ��B���Ȃ�A�f�W�J����GPS�ƘA�������c�[�����ł��Ȃ����Ǝv���B�莝���̃f�W�J���ACP-600��PC�ɐڑ����ă����[�g�ŎB�e�ł���̂����ACF�������J�[�h�ɋL�^�ł��Ȃ��Ȃ��Ă��܂������˂��B�B�e�n�_�̈ܓx�o�x���L�^�ł���f�W�J���͂������낢���ǁA�N�ł��v���������Șb�B���������������邽�߂ɂ́A�ʐ^�摜�t�@�C���ɋL�^����āA�����ǂݏo���Ȃ��Ƃ܂�Ȃ��BEXIF���E�E�E
�l�H�m�\�̑��l��J�E�}�b�J�[�V�[���ɕ���--AI�����A�����I�̗��j��U��Ԃ� - CNET Japan�l�^�B
���[�ށA���[����˂��A�Ƒ��Ƃ�łB���A�\�Ȃ̂́Aif�`elsif�`�E�E�E�`else�̃G�L�X�p�[�g�V�X�e������ˁB����Œm�����L�q���邱�Ƃ͂�����x�ł���Ǝv���B�v���O���~���O�͐��ɂ��̂��̂�����B
�����A���ƁA700MB��CD-R���ɏo�|�����B�R�W�}�d�@�ƃC�I��������āA5mm�̔����P�[�X�ɓ�����20���A1280�~��̃}�N�Z����CD-R���w���BPodcast�̘^���p�ł���B��ӁA�A�L�o�n!�d�]��ԃJ�E�{�[�C�Y��54���55���2��^�����悤�Ƃ��āA650MB�ł͏�������Ȃ��������炾�B����́AiTMS��Podcast�̃��X�g�ׂāARADIO SAKAMOTO Podcasting Vol.8,9��^�������B�ʋ̎Ԓ�����2���Ԃ�@���ɗL�Ӌ`�ɉ߂������͐l���̏d�v�Ȗ��Ȃ̂ł���(^^;)
�A�L�o�n!�d�]��ԃJ�E�{�[�C�Y�̑�2���͑�52-53��̓d�ԉ����z�M(Podcast)����O��҂���n�܂����B�܂��܂��������납�����B�����́A���܂����܂�����54-55���I����(�n�[�h�E�F�A)�H��O��҂���B�r���ŁA���c�S��̍����̎O�����낵�������Ă��܂��̂����BFM��CD�̐�ւ����������ł��Ȃ����̂�(^^)
�����������Icon�u���B
�� TSfree �� Icon�~�j�u���R�i�������̕����j�@�@������
����́A�������̕����a�ւ̕����ł��B����́A�T�����̕�������Ƃ��āA�Ⴆ�A�R�����ƂQ�����̂Q�̒P��Ƃ��āA�������Q�Ƃ��邽�߂̂��̂ł��B�T�̕����ł��A�T�i�������Ȃ��j�A�S�{�P�A�R�{�Q�A�R�{�P�{�P�A�D�D�D�Ƃ����āA�Ō�͂P�{�P�{�P�{�P�{�P�ƁA���Ȃ�̃p�^�[�����������܂��B���������ʓ|�ȌJ��Ԃ����K�v�ȏ����́A�ċA�������s���ƃv���O�������y�ɂȂ邱�Ƃ������݂����ł��ˁB
�����́A�T�̗�ł��ƁA�T���珇���@�T�A�S�A�R�A�Q�A�P�ƈ����Z���Ă��������ɂ��Ă��܂��B
�ŏ��́A�T����T�������P�[�X�ŁA�]��͂O�ł��B���ʂ́m�T�n��Ԃ��܂��B
���́A�T����S�������P�[�X�ŁA�]��͂P�ł��B�]�肪����ꍇ�́A���Ԍ��ʂƂ��ām�S�n��ێ����āA�������g���X�ɌĂ�Łi�ċA�j�A�]��̂P��^���āA���ʂ����炢�܂��B���̌��ʂƂ��ām�P�n���Ԃ��ė��܂��B���Ԍ��ʂ́m�S�n�Ɂm�P�n��lj����ām�S�C�P�n�����ʂƂ��ĕԂ��܂��B
���́A�T����R�������P�[�X�ŁA
�@�@�P��ڂ̓���@���Ԍ��ʂP�@�m�R�n�@�]��@�Q�@�E�E�E�]�菈���̂��ߍċA �@�@�Q��ڂ̓���@���Ԍ��ʂP�@�m�Q�n�@�]��@�O �@�@�@�@�@�@�@�@�@�@�@�@�@�Q�@�m�P�n�@�]��@�P�@�E�E�E�]�菈���̂��ߍċA �@�@�R��ڂ̓���@�@�@���ʂP�@�m�P�n
�Ƃ���������o�܂��̂ŁA���ʂ́m�R�C�Q�n�ƁA�m�R�C�P�C�P�n�̂Q���Ԃ�܂��B
����ȕ��ȓ���ƂȂ�܂��B
-----^ N_DIV.ICN ( date:03-08-20 time:19:43 ) --------------<cut here
####################
# ��������
####################
# n_div.icn Rev.1.0 2003/08/20 windy ������ H.S.
####################
# Usage n_div ����
# �^����ꂽ�������a�ɕ�������B
# ��:5->[5],[4,1],[3,2],[3,1,1],[2,2,1],[2,1,1,1],[1,1,1,1,1]
# This file is in the public domain.
procedure main(args)
Usage := "n_div ����"
if *args < 1 then stop(Usage) # �R�}���h���C��������������� Usage�\��
if args[1] < 1 then stop(Usage) # �����łȂ���� Usage�\��
# ���������� generator���珇�����ʂ����o��
every L := n_div(args[1]) do show_sl(L)
# ��list�̓��e��\������
end
####################
# �������� generator
####################
# arg [1]: ��������鐔�i�����j�i�ċA�̏ꍇ�́A�]��j
# value : �������ʂ̐� list�Ɋi�[
# Usage : every L := n_div(r) do ...
procedure n_div(r)
if r < 1 then fail # �O�̂���
if r = 1 then return [1] # �ċA�I��
# r >= 2 �̏ꍇ
every i := r to 1 by -1 do { # r ���珇�Ɂ@�|�P���Ȃ���
rr := r -i # ���̐���������Z���Ă���
if rr = 0 then suspend [i] # �]�肪�@�O�Ȃ猋�ʂ�Ԃ��B
else suspend [i] ||| n_div(rr)
# ���]�肪�ł���A�ċA���Ă��̌��ʂ� list�̖���
# �ɒlj��B�@||| �� list�̗v�f�̒lj����Z�q
} # suspend �́A�����̌��ʂ�Ԃ� return
end
# �ȉ��́AIcon����u�����
####################
# list�� ���e�\��
####################
# arg : list
# value : null
# Usage : show_sl(L)
# �ŏI�I�� string�� number���v�f�ł��邱��
# Icon����u���i�P�R�j,Icon����u���R�i�P�T�j
procedure show_sl(list)
# list�̓��e�\���itest�^�\���p�j
every writes(" ",!list)
write()
return
end
-----$ N_DIV.ICN ( lines:57 words:192 ) --------------------<cut here
n_div 5 >ccc�@�Ƃ��܂��ƁA����Ȍ��ʂɂȂ�܂��B
-----^ CCC ( date:03-08-20 time:19:44 ) --------------------<cut here 5 4 1 3 2 3 1 1 2 3 2 2 1 2 1 2 2 1 1 1 1 4 1 3 1 1 2 2 1 2 1 1 1 1 3 1 1 2 1 1 1 1 2 1 1 1 1 1 -----$ CCC ( lines:16 words:48 ) ---------------------------<cut here
�ȏ�̌��ʂ�ǂ����܂��ƁA�T���S�{�P�ƂP�{�S��@�R�{�Q�ƂQ�{�R�̗���������Ă��܂��B���������́A�ǂ��炩������s���A�c��͓���ւ��邾���Ől�����f�ł���Ǝv���܂��B�Ƃ������ƂŁA�Е������ɂ��邽�߂ɁA���ʂ́A�~�����������Ȃ��Ƃ���������t���܂��傤�B�Ƃ������ƂŁA�ċA�̍ۂɐ�����t���܂����B
-----^ N_DIVD.ICN ( date:03-08-20 time:19:42 ) -------------<cut here
####################
# ��������
####################
# n_divd.icn Rev.1.0 2003/08/20 windy ������ H.S.
####################
# Usage n_divd ����
# �^����ꂽ�������a�ɕ�������B���ʂ͍~���̕����̂݁B
# ��:5->[5],[4,1],[3,2],[3,1,1],[2,2,1],[2,1,1,1],[1,1,1,1,1]
# This file is in the public domain.
procedure main(args)
Usage := "n_divd ����"
if *args < 1 then stop(Usage) # �R�}���h���C��������������� Usage�\��
if args[1] < 1 then stop(Usage) # �����łȂ���� Usage�\��
# ���������� generator���珇�����ʂ����o��
every L := n_divd(args[1]) do show_sl(L)
# ��list�̓��e��\������
end
####################
# �������� generator
####################
# 5=3+2 ���ɕ�������B�����͍~���̂����B�i�� 5=2+3�͏��O�j
# arg [1]: ��������錳�̐��i�ċA�̏ꍇ�́A�O�̏����̗]��j
# [2]: �ő吔 �i5=2+2+1 �̏ꍇ�ɁA�ŏ��� 2�̎� 3���]�邪�A�ċA���� 3��
# �������n�߂鎞�A3����ł͂Ȃ� 2����n�߂邽�߂̍H�B�~���蓖�B�j
# value : �������ʂ̐��Blist�Ɋi�[
# Usage : every L := n_divd(r) do ...
procedure n_divd(r,max)
/max := r # �w�薳���́A��������錳�̐����̂���
if r < 1 then fail # �O�̂���
if r = 1 then return [1] # �ċA�I��
# r >= 2 �̏ꍇ
if r > max then rs := max # �����i��苎��j���̍ő吔�̐ݒ�B
else rs := r # ��������鐔�� �ő吔�w��� ��������
every i := rs to 1 by -1 do { # ��L�w�萔�`�P���A���Ɂ|�P���Ȃ���
rr := r -i # �V���ȗ]��
if rr = 0 then suspend [i] # �]�肪�������
# �]�肪����A�ċA����
else if rr > i then suspend [i] ||| n_divd(rr,i) # �]�肪�傫�߂��鎞
else suspend [i] ||| n_divd(rr)
}
end
# �ȉ��́AIcon����u�����
####################
# list�� ���e�\��
####################
# arg : list
# value : null
# Usage : show_sl(L)
# �ŏI�I�� string�� number���v�f�ł��邱��
# Icon����u���i�P�R�j,Icon����u���R�i�P�T�j
procedure show_sl(list)
# list�̓��e�\���itest�^�\���p�j
every writes(" ",!list)
write()
return
end
-----$ N_DIVD.ICN ( lines:63 words:231 ) -------------------<cut here
n_divd 5 >ddd�@�Ƃ���ƌ��ʂ́A�����Ȃ�܂��B�����ԃp�^�[��������܂����B����ł��A������������܂��̂ŁA��������ŏ����ɐ������������Ǝv���܂��B����́A����ɁB
-----^ DDD ( date:03-08-20 time:19:45 ) --------------------<cut here 5 4 1 3 2 3 1 1 2 2 1 2 1 1 1 1 1 1 1 1 -----$ DDD ( lines:7 words:20 ) ----------------------------<cut here
�T���f�[�E�v���O���}��ĂсFITpro�l�^�B�u���j�v���O���}�̂ЂƂ育�Ɓv�T�C�g�̏Z�l�Ƃ��Ă͖����͂ł��܂��B
��ђ��˂�h�b�g�C���p�N�g�v�����^�ƍ��͂Ȃ�2�C���`FD�̃V���O���h���C�u�������x�[�V�b�N�}�X�^�[Jr.�ŁA�J�i�̏�������Ă���������v���o���BFDD���܂߂�ƌy�����ԕ��݂̉��i�̃p�[�\�i���R���s���[�^�����ڂŒ��߂Ȃ���A���[�v���̎��オ�������A�������g���邱�Ƃ�������O�ɂȂ�B���[�v���ł悤�₭MS-DOS�����オ�������Ajgawk��jperl�Əo����āA�����Ɏ���B���̊ԂɃp�[�\�i���R���s���[�^�̔��W�̂����ƒ������j������BMS-DOS��MS-DOS+DOS Extender��Windows 3.1��Windows 95��Windows 98��Windows 2000��Windows XP�Ƃ�������B�����ς�A�v���O���~���O�����jperl�ł������B
����A�t���[�ł����{�ꂪ�g����v���O���~���O����͂��ǂ�݂ǂ�B�f�[�^�̓e�L�X�g�����A��ނ̓C���^�[�l�b�g�ɂ��f�X�N�g�b�v�ɂ����낲��]�����Ă���B����Ńv���O���~���O���������āA��������̂��B
������̃R���s���[�e�B���O�v���b�g�t�H�[���͉����BWindows Vista���AMac OS X���ALinux���APS3���E�E�EPS3���ǂ̂悤�Ȑ��E�������炷�̂��A�l����ϊy���݂ɂ��Ă���̂����E�E�E
�����������Icon�u���B
�� TSfree �� Icon�~�j�u���Q�i�g����������̎����Q�Ɓj�@�@������
����́A
�������s���܂��B�O��̎����Ǎ��̎����Q�Ƃ̕����ɁA�R�}���h���C�����͂̕�����̏���g�ݍ��킹��K�p����\���ƂȂ��Ă��܂��B
-----^ DICREFP.ICN ( date:03-08-20 time:18:18 ) ------------<cut here
####################
# �����Ǎ��E������̎����Q��
####################
# dicrefp.icn Rev.1.0 2003/08/20 windy ������ H.S.
####################
# Usage dicrefp ������
# english.dic�́A�X�y���`�F�b�N�p�̉p�P�ꂪ���ɕ����́B
# ���̃v���O�����̃e�X�g�ł́ADD SOFT SoundMixSpell�R���|�[�l���g
# Ver 0.3.0 �� �����̎����t�@�C�����g�p�B
# This file is in the public domain.
procedure main(args)
# �R�}���h���C�������`�F�b�N�B������� Usage�\��
if *args < 1 then stop("dicrefp �p�P��")
# �����Ǎ�
dic := "english.dic" # �����t�@�C����
dir := open(dic) | stop(dic," ��������܂���") # �����t�@�C���I�[�v��
S_dic := set() # �����i�[ set����
# write(&errout,dic," ��Ǎ����ł��B") # �����ǂݍ���
write(dic," ��Ǎ����ł��B") # �����ǂݍ���
# write(&errout,"�J�n:",&clock)
write("�J�n:",&clock)
n_line := 0 # �����s���J�E���^
while word := read(dir) do { # �������P�s���ǂݍ���ŁA
insert(S_dic,word) # set�ɓo�^
n_line +:= 1
if n_line % 1000 = 0 then writes(&errout,"*") # �ǂݍ��ݏ\��
}
close(dir) # �����t�@�C���N���[�Y
write(&errout)
# write(&errout,"�I��:",&clock)
write("�I��:",&clock)
# write(&errout,dic," �̓Ǎ����I���܂����B\n",*S_dic," �ꂠ��܂����B")
write(dic," �̓Ǎ����I���܂����B\n",*S_dic," �ꂠ��܂����B")
# �R�}���h���C���̈����̏�������A�������Q��
c_word := args[1]
# write(&errout,c_word," �̑g�����������ɂ��邩�`�F�b�N���ł��B")
write(c_word," �̑g�����������ɂ��邩�`�F�b�N���ł��B")
# write(&errout,"�J�n:",&clock)
write("�J�n:",&clock)
n_comb := 0 # �g�������J�E���^
n_find := 0 # �����ɂ��錏���J�E���^
every word := exsperm(c_word) do { # ���� generator���當�������o��
n_comb +:= 1 # �J�E���^�{�P
if n_comb % 1000 = 0 then writes(&errout,"*") # �`�F�b�N�\��
if member(S_dic,word) then { # �g�������������ɂ���A
n_find +:= 1 # �J�E���^�{�P
writes(&errout,"!") # �����\��
write(word) # �g����������o��
}
}
write(&errout)
# write(&errout,"�I��:",&clock)
write("�I��:",&clock)
# write(&errout,n_comb," �ʂ�̑g�����̂����A",n_find," �ʂ肪�����ɂ���܂����B")
write(n_comb," �ʂ�̑g�����̂����A",n_find," �ʂ肪�����ɂ���܂����B")
end
# �ȉ��́AIcon����u��������p
####################
# �p�����̑g�ݍ��킹�i���ꕶ���w��Ή��j
####################
# ���̕ύX expermute -> exsperm
# arg [1]: s string
# value: string
# Usage: every ss := exsperm(s) do ...
# Icon����u���Q�i�P�W�j
procedure exsperm(s) # string permutations
if *s = 0 then return "" #
ss := csort(s) # ��������\�[�g����B(strings.icn)
suspend ss[i := new_pos(ss)] || exsperm(ss[1:i] || ss[i+1:0])
# �����ꕶ���̓X�L�b�v����
end
####################
# �\�[�g���ꂽ������ s�̍��͂�����A���ɕ����ʒu���o�͂��� generator�B
####################
# ��O�̕����Ɠ���Ȃ�X�L�b�v����B
# arg [1]: s string
# value: integer
# Usage: every i := new_pos(s) do ...
procedure new_pos(s)
ss := "" # ��O�̕������L�����Ă����ϐ�
every i := 1 to *s do {
if ss ~== s[i] then { # ��O�̕����ƈ���Ă�����
ss := s[i] # ��O�������X�V
suspend i # i ��Ԃ��B
}
}
end
####################
# BIPL(Icon��{���C�u�����[)�� strings.icn�Ɋ܂܂�� �����̃\�[�g procedure
####################
procedure csort(s) #: lexically ordered characters
local c, s1 # ���[�J���ϐ��錾�i�����Ă��ǂ��j
s1 := "" # �����l�N���A
every c := !cset(s) do # ������ cset(�����W��)�֕ϊ������Ɏ��o���B
every find(c, s) do # ���o���������ŁA������������������A
s1 ||:= c # ������x�ɁA������ s1�ɑ������ށB
return s1
end
# cset���� !�ŗv�f�����o�����ɂ́A�A���t�@�x�b�g���Ɏ��o����B
-----$ DICREFP.ICN ( lines:110 words:369 ) -----------------<cut here
dicrefp sunrise >bbb �Ƃ��܂��ƁA����Ȍ��ʂɂȂ�܂��B
-----^ BBB ( date:03-08-20 time:19:18 ) --------------------<cut here english.dic ��Ǎ����ł��B �J�n:19:18:22 �I��:19:18:30 english.dic �̓Ǎ����I���܂����B 257650 �ꂠ��܂����B sunrise �̑g�����������ɂ��邩�`�F�b�N���ł��B �J�n:19:18:30 insures sunrise �I��:19:18:30 2520 �ʂ�̑g�����̂����A2 �ʂ肪�����ɂ���܂����B -----$ BBB ( lines:11 words:17 ) ---------------------------<cut here
�������̒P��Ŏ����Ă݂܂������A�Z���P��ł��ƕ��בւ��Ō��\���̒P��ɂȂ�܂����A�����P�ꂾ�ƕ��בւ��Ă����܂��͑��̒P��ɂ͂Ȃ�Ȃ��݂����ł��B
�����������Icon�u���B
�� TSfree > Icon�~�j�u���P�i�����Ǎ��j�@�@������
����́A�����̓ǂݍ��݂ł��B�@�����ƌ����Ă��A�P�ꂪ������ƕ���ł���e�L�X�g�t�@�C���ł��̂ŁA�e�L�X�g�t�@�C���̓Ǎ��v���O�����ƕς��͂���܂���B�@��X�A���Ԃ����ɋC�ɂȂ肻���Ȃ̂ŁA���ݎ����������o���悤�ɂ��܂����B &clock�́A���ݎ����� hh:mm:ss�`���ŕێ����Ă���g���L�[���[�h�ł��B�@�@�ŏ��A���샂�j�^�[�p�̕\���́A�G���[�o�͂֏o���Ă��܂������A�A�b�v�̓s����A�W���o�͂֏o���悤�ɏC�����Ă���܂��B
-----^ DICREF.ICN ( date:03-08-19 time:23:32 ) -------------<cut here
####################
# �����Ǎ��E�����Q�Ƃ̏K��B
####################
# dicref.icn Rev.1.0 2003/08/19 windy ������ H.S.
####################
# Usage dicref ������
# english.dic�́A�X�y���`�F�b�N�p�̉p�P�ꂪ���ɕ����́B
# ���̃v���O�����̃e�X�g�ł́ADD SOFT SoundMixSpell�R���|�[�l���g
# Ver 0.3.0 �� �����̎����t�@�C�����g�p�B
# This file is in the public domain.
procedure main()
# �����Ǎ�
dic := "english.dic" # �����t�@�C����
dir := open(dic) | stop(dic," ��������܂���") # �����t�@�C���I�[�v��
S_dic := set() # �����i�[ set����
# write(&errout,dic," ��Ǎ����ł��B") # �����ǂݍ���
write(dic," ��Ǎ����ł��B") # �����ǂݍ���
# write(&errout,"�J�n:",&clock)
write("�J�n:",&clock)
n := 0 # �����s���J�E���^
while word := read(dir) do { # �������P�s���ǂݍ���ŁA
insert(S_dic,word) # set�ɓo�^
n +:= 1
if n % 1000 = 0 then writes(&errout,"*") # �ǂݍ��ݏ\��
}
close(dir) # �����t�@�C���N���[�Y
write(&errout)
# write(&errout,"�I��:",&clock)
write("�I��:",&clock)
# write(&errout,dic," �̓Ǎ����I���܂����B\n",*S_dic," �ꂠ��܂����B")
write(dic," �̓Ǎ����I���܂����B\n",*S_dic," �ꂠ��܂����B")
# �����Q�ƃe�X�g
L := ["heavy","rain","yveah","niar"] # �e�X�g�f�[�^
# write(&errout,"�Q�ƃe�X�g���J�n���܂��B")
write("�Q�ƃe�X�g���J�n���܂��B")
# write(&errout,"�J�n:",&clock)
write("�J�n:",&clock)
every s := !L do { # �e�X�g�f�[�^�������ǂݏo��
writes(s)
if member(S_dic,s) then write(": OK") # �����ɂ��邩�`�F�b�N
else write(": NG")
}
# write(&errout,"�I��:",&clock)
write("�I��:",&clock)
# write(&errout,"�Q�ƃe�X�g���I���܂����B")
write("�Q�ƃe�X�g���I���܂����B")
end
-----$ DICREF.ICN ( lines:53 words:154 ) -------------------<cut here
dicref >aaa �Ƃ��܂��ƁA����Ȍ��ʂɂȂ�܂��B
-----^ AAA ( date:03-08-19 time:23:35 ) --------------------<cut here english.dic ��Ǎ����ł��B �J�n:23:35:43 �I��:23:35:51 english.dic �̓Ǎ����I���܂����B 257650 �ꂠ��܂����B �Q�ƃe�X�g���J�n���܂��B �J�n:23:35:51 heavy: OK rain: OK yveah: NG niar: NG �I��:23:35:51 �Q�ƃe�X�g���I���܂����B -----$ AAA ( lines:13 words:20 ) ---------------------------<cut here
���̂o�b�ł́A�����Ǎ��Eset�ւ̊i�[�ɁA�W�b�قǂ������Ă��܂��B�b�o�t�@Celeron�ŁA�N���b�N�@�V�R�R�l�A�������[�͑����R�Q�l�AMS-DOS�ł� Icon���AWindows-ME�̂c�n�r���œ��삳���Ă��܂��B
���A�݂�ȎႢ�B30�O��̐l�����ȂB�ł��A�������낢�B�܂��A�l�����x���͒Ⴂ�������悤�ȃR���s���[�^�̌��͎����Ă���̂����E�E�E���オ�����ԈႤ�B�e�N�m���W�[�n�ōő�̎��������ւ�炵�����A�������낷����ˁB�A�L�o�n!�d�]��ԃJ�E�{�[�C�Y: ��\��� �d�]��ԃJ�E�{�[�C�錾!�l�^�B
��͂�AiTunes�ōw�ǂ��āACD�ɏĂ��Ē��̎Ԃŕ������ȁBCGI��CD�ɏĂ����@�͂��邩�ȁE�E�E
���ւɂ��ASOHO�ɂ��A���^�e���r�ɂ�--�A�b�v�� Mac mini (intel) - ���r���[ - ZDNet Japan�l�^�B
�v���U���Mac�l�^�����ǁA1.66GHz��Intel Core Duo�ŁA99,800�~�B���������ɂȂ����˂��B
�ĂɂȂ�ƁA�䂪���@�����邳���G�����锠�ɂȂ�B�G�A�R����t���Ă��Ă��A�t�@�����X���ĉ��n�߂�B��߂Ă����ƌ��������Ȃ�B�܂��܂��APC�͐i�����Ȃ��Ă͂Ȃ�Ȃ��B��̓t�@���ɂ�鑛���ł���A������͂�͂�X�s�[�h�ł���B�����̃A�v���P�[�V������x�Ȃ��A���Ȃ킿�҂����ԂȂ����s�ł���K�v������B
�u�������ו��U�͕K�v�Ȃ��v---1��œ���50���ڑ���Web�T�[�o�[���o��FITpro�B�����܂ł̃X�y�b�N�͌l�̃f�X�N�g�b�v�ɂ͕s�v�ƁA�ʏ�l���邩������Ȃ����A���E���f�X�N�g�b�v��ɍ\�z���悤�Ƃ���A�K�v�Ȑ��\�Ɍ��E�͂Ȃ���������Ȃ��B�l���APS3�Ɋ��҂��Ă���̂͂��̂悤�Ȋv�V�ł���B
�����������Icon�u�����Ĕ������āAIcon���v���U��Ɍ��ɍs���Ă����BUnicode�Ή��̉\����Jcon(Java-based Icon)�ł̑Ή��̉\����������Ă��邪�A�����_�ł͂܂��B
TSNET���n�݂���Ĉȗ��A�{�T�C�g�́u�X�V���L�v�ɔ�d���ڂ��A�u���j�v���O���}�̂ЂƂ育�Ɓv�ƕʏ̂������A����ɖ{���̃v���C�x�[�g�T�C�g�ɂȂ肩���Ă����̂����B
TSNET�́A�C�y�ȃ}�C�y�[�X�̃��[�����O���X�g��Wiki�Ƃ��Čp������Ă���B�C����������b�������邱�Ƃ��ł��钇�Ԃ�����BTSNETWiki�ɁA�����������Icon�u�� - TSNETWiki�̃y�[�W������Ă݂��B
�ŏ���Wiki�y�[�W�ɓ\��t���ĉ��H���悤�Ƃ��������̂����A���ʂ��������č��܁B�����̓��L�ʼn��H���n�߂��B�䂪���L�Ɍf�ڂ���AAtom�Ŏ��o�����Ƃ��ȒP���BWiki�͓Ǝ��`���̃e�L�X�g�ŕۑ�����B���ꂪ�����W�����ɋt�s����B�X�V���L��dml�ŏ����Ă���̂����Adml���͎̂c���Ȃ����j�ł���B�Ȃ��Ȃ�A�d�l���ǂ�ǂ�ς��邱�Ƃ��\�Ȃ̂ł���Bdml�ŕۑ������AHTML�Ƃ��ĕۑ����邩��ł���B
TS Network�́A�R�~���j�e�B�Ƃ��āA�V���Ȃ��̂ݏo���̂��A�R�~���j�e�B���̂��̂��V�����`�ԂɂȂ�̂��A���āE�E�E�A�����������m���Ă���B
2003/9/26 ������(hshinoh[atmark]mb.neweb.ne.jp)�����--- TS Network �ւ̏������� ---
�{�T�C�g�̍u���ɂ́A�����������Icon Lecture�Ƃ����L��������܂��B���́A�Վɂ��畗��������̃��[����]�����Ă�����ču��(Seminar on TS Network)�ɒlj�����悤�Ɉ˗�����Ă����̂��A���������炭�o�^�o�^���Ă��������������̂ŁA�������Ă������A�Y��Ă��܂����������ǁA�������[�������Ă��Ă��܂��ܔ����BTSfree�ւ̏������݂��܂Ƃ߂�ꂽ���́B�����܂łق����炩���Ő\����Ȃ��B_(__)_�e�L�X�g���ʂ��傫���̂Ŗ{���L�ŘA�ڂ��A��������HTML�������\���邱�Ƃɂ��āA�Ō�ɂ܂Ƃ߂āA�u���ɒlj��������܂��B�ȑO�AHTML���Ɏg�����X�N���v�g�̍s�����肩�łȂ����E�E�E�A�f�U�C���I�ɂ������l���邩�ƁB
�� TSfree > Icon�~�j�u���i�O���j�@�@������
�c�~�J���������\���グ�܂��B�c������Ȃ��āA�~�J�������c���Ă���悤�ȓV�C�ł��ˁB�ΐ���ڋ߂Ƃ������j���[�X�Ŗ������グ�Ă��A�_����B
���āA����ATS Network�� TSabc�ŁA�N���X���[�h�p�Y���̊W�ŁA�ʔ�����ނ���Ē����Ă��܂��B����ȃP�[�X�ł��B
�Ƃ��������Ƃ�����܂��āAIcon�łŊȒP�Ȏx���v���O����������Ă݂��̂ł������~�x�݂ɁA���������@�\�A�b�v�ł��Ȃ����ƍl���Ă݂܂����B�����������āA�A�b�v���Ă݂܂��B
��������l���Ă݂��̂ł����A
����ȂƂ���ŁA����Ă݂܂��傤�BIcon�̃v���O��������у��C�u�����[�́A���̏����� ����ł��܂��B�� http://www.cs.arizona.edu/icon/
���̍u���́ATS Network�� TSfree ���[�����O���X�g�Ƀ|�X�g�������̂ɉ��M�E�C�����s�������̂ł��BIcon�� PDS�ł��̂ŁA���̍u�������������Ƃ��܂��B�i�]�ځE�ҏW���R�j(This textbook is in the public domain.)
Icon�~�j�u���@�ڎ��@�@�@�@�@�@�@�@�@�@ ���e �@�@��P��@�@�����Ǎ� �t�@�C���Ǎ��Aset(�W��)�����E�i�[�E�Q�� �@�@��Q��@�@�g����������̎����Q�� ����(nPm)�Aset�Q�� �@�@��R��@�@�������̕��� �������̕����a�A�ċA�v���O���� �@�@��S��@�@�t�B���^�[ generator�ƃt�B���^�[ �@�@��T��@�@�������E�����Q�� ������̕����E�J��Ԃ��Q�� �@�@��U��@�@�����Q�Ƃ̕ʕ��� table�����E�i�[�E�Q�� �@�@��V��@�@�B���Q�� �g��������(nHm) �@�@��W��@�@�������� �t�@�C�������� �@�@��X��@�@���z�g���� ������̑g�������z �@��P�O��@�@���������Ŏ����Q�� �J��Ԃ��Q�� �@���܂��@�@�@�v���O�����̐��� link �@���܂�@�@�@procedure�\�� �ċA�Eevery�Ewhile
�F��22�����2H���b�l�Ƃ��Ă̓w�߂��ʂ����ׂ��A�ē���ɊȒP�ȃ�����lj����āA�Ō�̈ē��𑗕t�B�F�i�X�ǂ̂䂤�䂤�����ŏo���B�����ɐ؎��\���ďo���Ă����B�x���ł�0-24���Ԏ�t������֗��B�� �����c�Ǝ��Ԃ̂��ē� �L����
Dell2�}�V����17�C���`�f�B�X�v���C��Vista�p�Ɏ��O���A���XDell2�}�V���ɕt���Ă���15�C���`�ɖ߂��Ă����B�M�܂߂ƃC���N�W�F�b�g�͂��̃}�V���Ŏg���悤�ɂ��Ă���̂ŁA�N�������OUT OF SCAN�̕\���BXP�������܂ł͌����Ȃ��B���̂܂ɂ��A�Q�Ă�ԂɃf�B�X�v���B�������ւ����Ă����Ƃ͋C���t���܂��B�t�͖��Ȃ����B
���ǁA17�C���`��t���ւ��āA��ʐݒ��15�C���`�p�ɐݒ肵�Ȃ����āA15�C���`�ɖ߂��BOK(^^)�f�B�X�v���B�̓d���𗎂Ƃ��A������PC���~�߂�܂ł��Ȃ��B������ȐӔC�ł��˂Ȃ�Ȃ����ǂ�(^^;)
�ē����t�p�ɏ������ꂽ�����̌`���A���`3��(120�~235)��I�����邪�A�Ȃ����A���o�l�̈��������Ă��܂��B�t���b�v���̐ݒ�Ƃ������ڂ�����̂����A�W������̂��A�Ȃ�̂��Ƃ��킩��Ȃ��B�w���v�̌������ɓ��{�ꂪ���͂ł��Ȃ��Ȃ�Ǐ�ŁA�w���v�����ɗ����Ȃ��B����Ȃ��Ƃ悭�����ˁB�����A�����ŁA�ʂ̃}�V���ŃO�O��ƁA�悤�₭���������܂�Ȃ������̒������Ƃ킩��B�������ꂽ�����͉��Ƀt���b�v������̂ŁA�����̒����ɂ͊W�Ȃ��B20.0mm��0�ɐݒ肷��B����ł����߁B����P�Ɉ�����J�n������ɐݒ��ς��Ă����f����Ȃ����������A�悤�₭�C���t���āA������L�����Z�����āA�ēx���݂�B����(^^)�����Ԃ��Ă��܂����B
�u�A�L�o�n!�d�]��ԃJ�E�{�[�C�Y: ��\�� �d�Ԟx(�u�b�N�}�[�N)��RSS��Google�v��Podcast�͑�ς������납�����Ƃ������A�����悤�Ɋ����Ă���Ƃ��낪�����Ǝv�����BRSS/Atom�̈Ӌ`�́AHTML�ɂ�����L��u���O�A�j���[�X�AWiki�̋L���v�f��W�������A���ʂ̃f�[�^�Ƃ��Ď�舵����悤�ɂ����Ƃ���ɂ���B�܂��A������܂Ƃ��ɗ��p�����A�v���P�[�V�����͂Ȃ��B�������ARSS��Web���f�[�^�x�[�X�Ƃ��Ď�舵���[���ƂȂ����ƌ㐢�̗��j�Ƃ͌������낤�B
�u�b�N�}�[�N + RSS + Google���z������́B�u�b�N�}�[�N�͍���Web�ɂ�����AGoogle�̓f�X�N�g�b�v�ɐi�o���Ă���B�f�X�N�g�b�v�̒T������Google�ɔC����Ƃ��v���B�������낢�悤�Ɍ�����ˁB�]���āA���ǁA������Web�ƃf�X�N�g�b�v�̗Z���ɂ���Ǝv���BGoogle�͂�����悭�m���Ă���Ǝv���B��c�����C���ł�����̂����A�����ɕK�v�Ȃ��̂̓f�X�N�g�b�v�ɏW�ς���Ă�������ł���B��͒n���Ȍ����ƃu�b�N�}�[�N�A�����ă��[�����O���X�g�ƃt�B�[�h�̍w�ǂł���B������f�X�N�g�b�v�ɏW�ς��邱�Ƃ��厖�����B�����GDS�������ł���悤�ɂ���B�����牺��Ƀo�C�i���f�[�^�x�[�X�����Ȃ��ق����悢�̂�������Ȃ��B
����Microformats�łقڌ��܂肶��Ȃ����BRSS/Atom�ɑ������̂ɂȂ邾�낤�BRSS/Atom�̔z�M����L���͂܂��ڍׂȃ��^���������Ă��Ȃ��B�^�C�g���A�v��A���҂�X�V�����A�J�e�S�����x�����^���Ƃ��Ďg������x�̂��̂��B�L���̋�̓I�ȍ\���v�f�ɂ��Ă͂قƂ�ǖ��͂Ȃ̂ł���B�L�����\������e�v�f�ɂ��āAMicroformats���l���悤�BCodeZine�̋L���̑�3��͂�����l�^�ɂ������B
�Ȃ�āA�������Ă��d���Ȃ����ǁAalt-S�ŋN������Sage���g���̂�����Ȃ�ɕ֗����B�t�B�[�h���W�߂�̂Ƀu�b�N�}�[�N���g���͓̂��������ǁB�u������v�V�X�e����submain�t���[���Ƀt�B�[�h���X�g���o���āA����submain�ʼn�͂������ʂ�����̂����ɂ����B�ŋ߂͕ʂ̃^�u�ɔz�M���̊Y���L����\�������邱�Ƃ��ł��邩��Amain�t���[���Ńt�B�[�h��͂������ʂ�����̂��֗����ƃt�B�[�h���X�g�̉�͌��ʏo�͐��ύX�B�Ȃ��Ȃ���������Ȃ��Ǝ��掩�^�B
IE 7���ɏo�̓X�^�C����ύX���邩��(^^;)
 �u������v�V�X�e�����A�L�o�n!�d�]��ԃJ�E�{�[�C�Y��Podcast���Ă���Ƃ���
�u������v�V�X�e�����A�L�o�n!�d�]��ԃJ�E�{�[�C�Y��Podcast���Ă���Ƃ���TSNET�ŕ]���́A�Ȃ��Ȃ��C���e���W�F���g��IT�ŐV�̟������b�����舵��Podcast�BSage�ł�Podcast�ւ̃����N��\���ł��Ȃ��B
 �g��}: �u������v�V�X�e���Łu�A�L�o�n!�d�]��ԃJ�E�{�[�C�Y�v��Podcast���Ă���Ƃ���
�g��}: �u������v�V�X�e���Łu�A�L�o�n!�d�]��ԃJ�E�{�[�C�Y�v��Podcast���Ă���Ƃ����~�V�F���E�t�[�R�[����A������̃t�����X�̏����Ƃ����ւ̂Ȃ��肪�����т�����B���A�c�_��Y��A�u����t�����X�����j�v�݂������[�A1976�N3��30���A�V����1��(���ő�1��: 1966�N1��30��)�A����: LE ROMAN FRANÇAIS DEPUIS LA GUERRE(Éditions Gallimard, 1963, 1970)�A323�y�[�W�A2600�~�́A����O���炢����̃t�����X20���I���w�̃K�C�h�Ƃ��ďڂ����B����̐펀�҃|�[���E�j�U������A�l�̍D���ȁA�����͂܂��Ⴉ����J�EM�EG�E���E�N���W�I�܂ł����グ���Ă���B
�k���N�̃~�T�C�����˂̃j���[�X���Ȃ���A�푈�͂Ȃ��N����̂����l����������B���̔g�̔������_�܂ł��A�j���[�g����J���g�܂ők��ȑO�ɁA20���I�ɂ��Ă��v������K�v������B
�Ɠ����A�W�T�C�̐F���炫���߂ƍ��ł͐����F���ς���Ă���Ǝ����Ă����B�O�ɎB�e�������Ɣ�ׂĂ݂悤�B
 2006-06-17
2006-06-17 2006-07-05
2006-07-05��ӁA�蕨����Ō��J���ꂽ���{���Y�́u�����̐_�b�v(1969)�B�O�i�̐���グ���s�v�Ȋ������������A��ʂ����C�g�Ŕ��������Ă��܂��āA���ЂƂ������B�v���U��ɎR���m��̃s�A�m�͒��������E�E�E
���́A����4�����������A5���̘A�x���̂��Ƃ������Ǝv�����A�L���s������p�قŁA�C���O�̌�����̎ʐ^���W�����ꂽ�B��^�̃C���N�W�F�b�g�v�����^�ň�����Ē��荇�킹�����̂ŁA��C���̑�����ʂ��Ă����B��㖜���́u���z�̓��v(1970)�Ɠ������ɐ��삳�ꂽ�lj�ł���B���z�̓��ɂǂ̂悤�ȈӖ�������̂��������Ƃ��A���{���Y�́u�Ӗ��Ȃ���͂����Ȃ��v�ƚ����������ŁA�G�Ȃǂ̌|�p�ɉߏ�ɈӖ������߂�͖̂��ʂȂ��Ƃł���B���邪�܂܂����Ċ����邾���ł���B���{���Y�̍�i�͌l�ŏ��L������̂͂Ȃ��A��i�͊�������Ό����̂��̂Ƃ����l���������̂��������B�u�����̐_�b�v�͍L���ɗU�v����\�z�����邻�������A�悢�ݒu�ꏊ�̃A�C�f�A���o���Ă��炢�����B
 �u�����̐_�b�v�̃p���t���b�g��4���ɐ܂肽���܂ꂽ�G�t��
�u�����̐_�b�v�̃p���t���b�g��4���ɐ܂肽���܂ꂽ�G�t�����{���Y �ւ炩�ȃ��b�Z�[�W"�����̐_�b"�����ւ̓��W 2006.4.15.sat��5.28.sun �L���s������p��
��ɂ���ĂƂ������A�O�ɂ������āA�{�������ς܂ꂽ�B�����ɏ\���ȏ���̖{��ǂ�ł���B�l��30�N���O�A�ߋ��̖{�B�挎�o�ł��ꂽ����̐V�����{�B���t�̐��E�̘A�Ȃ�ɋL����H�闷�ɏo��B���t�͋L�����h�����A�ߋ����猻�݂Ɍq����n�D���яオ�点�A�����������A�قƂ�Ǎl����p��m��Ȃ������Ⴋ����䍂���B���z�}���قɁA�{�̖ژ^�A�l�̚n�D�̖ژ^����낤�B
����͈ꉞ�`�F�b�N���Ă����ׂ����낤�B�������A���{���̃g�����h���~�����Ƃ�������������B
XP�p��IE 7 Beta 3���o���BVista��IE 7�Ƃ�������ŁARSS/Atom�̃u���E�U����������Ă���B�u���E�U�͂���ɔC����Ƃ����������˂Ǝv�����炢�悢�B�������A�V�����^�u���J�����肷��Ƃ悭������B�܂��A�s����B
 IE 7 Beta 3 for XP
IE 7 Beta 3 for XPWindows�t�H�g�M�������[��Picasa�R�Ȃ̂��낤���A�����������x���Ŕ�r���Ă͂����Ȃ��̂�������Ȃ��B�t�H�g�M�������[�̎ʐ^�̑N�����E�����ɂ͖ڂ�D��ꂽ�BMS�A���̎s��͉摜����--�ʐ^�Ƃւ̃A�s�[�������� - CNET Japan�̋L�������āA�Ȃ�قǂƂ��v�����B�������A�܂��A�ʐ^�̃t�H�[�}�b�g��jpeg�̂܂܁B�v���U��Ɍ���CRT��ʂ̍��o�̉\��������(^^;)�P�Ɍ��X�ǎ��̎ʐ^�ł��邾�����炩������Ȃ��B���ށAXP�̃��C���}�V�����猩�Ă݂悤�B�t���̃U���c�L���͂��邪�A���̎ʐ^���D��Ă���ƌ��_�t���������悳������(^^;)
wmv�̃T���v���̃r�f�I�́A�u�r�f�I�J�[�h�̃n�[�h�E�F�A�E�A�N�Z�����[�V�������K�v�ȃ��x���ɂȂ����A�n�[�h�E�F�A�E�A�N�Z�����[�V�������g���Ȃ����ł���v�Ƃ������b�Z�[�W���o�čĐ��ł��Ȃ��A�Ǝv������AWindows Media Player�ŊJ���ƃL�`���ƍĐ��ł����B�������ABeta���B
Google�̓\�t�g�E�F�A���I�[�v���ɂ��邱�Ƃ����Ђ̃r�W�l�X�W�����邱�ƂɂȂ���Ƃ����V�����r�W�l�X���f���ݏo������BOpen Tech Press | JavaWorld DAY 2006�FGoogle�̃L�[�}�������u�I�[�v���\�[�X�ƃ\�t�g�E�F�A�̖����v�l�^�B
�\�t�g�E�F�A�͐��ɓ��p�i��������B����ł����͂������悤�Ƀ\�t�g�E�F�A���ȒP�ɍ���悤�ɂȂ�B���̂悤�Ȏ��オ�߂Â��Ă���B���̐�ڂ��̂��X�N���v�g����ł͂Ȃ����ȂƎv�����肵�Ă���B�܂��ɃI�[�v���\�[�X���̂��̂ł���B
�l��rss2html.cgi�������n�߂����Aglucose�Ƃ���RSS���[�_�[�̏o�n�߂̃f�U�C�������Ă����Ȃ��Ǝv�����̂����A�����ŐV�ł��_�E�����[�h���ē������Ă݂��B�X�V���L��Atom�z�M���������̑�\�I�ȃ��[�_�[�Ń`�F�b�N���邽�߂ł���B���ɂ́AWindows Vista Beta 2��IE 7��Firefox��plugin��Sage(���l)�ł���B��������D�ꂽ���̂����A�@�\��ύX������A�lj�������A���̃A�v���P�[�V�����ƘA�g������Ƃ����悤�Ȃ��Ƃ��ł��Ȃ��B���̂悤�Ȃ��Ƃ��������邽�߂ɂ́A�����ō�邵���Ȃ��B�����āA��������L���Ĕ��W�����邽�߂ɂ́A�X�N���v�g���ꂪ�K���Ă���B
�f�[�^�͍���e�L�X�g�ƂȂ�A���̃e�L�X�g��ό`������A�K�v�ȕ������o������A����������A�������肵�āA�V�������ݏo���B���̏�ŗl�X�Ȏ�����ǂ�ň��p�������\�肵����A�����̍l�������ʂ��������肵�āA�V�������͂ݏo���̂Ƃ����ĕς��Ȃ��B�\�t�g�E�F�A�ɂ��e�L�X�g�̑���͓��퐶���ōs���Ă��邱�Ƃƕς��Ȃ��قǒP��������Ă��Ă���B
�uRSS���[�_�[����p�[�\�i�����v���b�g�t�H�[���ցv�Ƃ���glucose�̃R���Z�v�g�́A�uWeb�ƃf�X�N�g�b�v�̗Z���v��������f�X�N�g�b�vCGI�̍l�����Ǝ�������������Bglucose2�ł́A��͂胍�[�J��HTTP�T�[�o�[�����삵�Ă���B����ɉ����ċ����[���̂́APython�����삵�Ă��邱�Ƃł���B�w���v�̃o�[�W���������Q�Ƃ���ƁAPython���܂߂ėl�l�Ȃ��̂�g�ݍ��킹�č\�z����Ă��邱�Ƃ��킩��B
 glucose2�̃o�[�W�������
glucose2�̃o�[�W�������
�f�X�N�g�b�vCGI������ǂ̂悤�ɕϖe���Ă����̂��͂܂��悭�킩��Ȃ��̂����A�f�[�^�x�[�X�������Ă݂悤�ƍl���Ă���B�f�[�^�x�[�X�Ɏ��p�I�ȈӖ����^������̂��ǂ������A�܂����R�Ƃ��Ă��āA�{���ɕK�v�Ȃ��̂ɂȂ�̂��ǂ������悭�����Ȃ��B���L�Ƃ������n����V�X�e���̌��ʂ����悭���������S����͂����ƍl���Ă��邪�A�ǂ��g���̂�����̓I�ɂȂ��Ă��Ȃ��̂ł���B���̑O��Microformats���g���āA���L�������V�X�e�����\�z����B����ɂ���ē��L���f�[�^�x�[�X�������͂��ł���B���L�͑��푽�l��Microformats�̏W���Ƃ��ĕ\�������悤�ɂȂ�B
Windows XP�Ƃ̃f�U�C���ȊO�̈Ⴂ��T��B
�����Ƃ��傫�ȈႢ�́AWindows Media Center������Ƃ������ƁBMac ��Front Row�̂悤�ȃf�U�C�����B�������A������������ɂ�PC�ɐڑ��ł���TV�`���[�i�[���̊O���@�킪�K�v���B�����֘A�����N�����Ă������B
Windows Vista���[���h�T���U�B
 Windows Vista��Gadgets
Windows Vista��GadgetsVista��Gadgets�T�C�h�o�[���g���Ă݂�BVista�}�V�����e�X�g����̂��ړI�Ȃ̂ŁA���ʕK�v�Ȃ�GDS�̓A���C���X�g�[���BGadgets�̓��b�`�ȃf�U�C���ŁAVista�Ƀ}�b�`���Ă���BMac�̃��b�`�ȕ��͋C�Ɏ��Ă���B�^�X�N�o�[�̃^�X�N�ɃJ�[�\�������킹��Ɖ�����Ɩ����Ƃ炷�B�������A���҂��Ă����E�B���h�E��3D�\���̓T�|�[�g����Ă��Ȃ��B�O���t�B�b�N��p�{�[�h���Ȃ��}�V�������瓮���Ȃ�������������Ȃ��B�V�X�e���ɂ�Windows Edition��Windows Vista Ultimate�ƂȂ��Ă���B
 �u���j�v���O���}�̂ЂƂ育�ƁvAtom�t�B�[�h��IE 7�ɂ��\��
�u���j�v���O���}�̂ЂƂ育�ƁvAtom�t�B�[�h��IE 7�ɂ��\��Atom�t�B�[�h��IE 7�ŕ\���������Ƃ���AAtom�t�B�[�h����͂��āA���בւ���J�e�S���ɂ��t�B���^���T�|�[�g����B�\�����Ă���`���̃\�[�X�͕\������Ȃ��BRSS�ɂ��Ă����l�̋@�\���T�|�[�g���Ă���B
 Windows Vista�}�V��
Windows Vista�}�V��15�C���`�f�B�X�v���B��Windows Vista�ɂ͋�������B1024�~768�s�N�Z���B
 Windows Vista 1280�~1024�s�N�Z��
Windows Vista 1280�~1024�s�N�Z����͂�A17�C���`�f�B�X�v���B�ɕύX�BPC98���ォ��g���Ă���N�㕨���B���ꂮ�炢�Ȃ��Ƌ������������Ă��܂��B�������A�C�ɓ����Ă����I�[�����̃X�N���[���Z�[�o�[���u3D�n�[�h�E�F�A�A�N�Z�����[�^�̋@�\����ʂ�v�Ƃ������b�Z�[�W�����낤��Ɠ��������̂ɒu���������Ă��܂��̂ł�������(^^;)