 更新日記 - 日曜プログラマのひとりごと
日曜プログラマのひとりごと
更新日記 - 日曜プログラマのひとりごと
日曜プログラマのひとりごと
【レビュー】WebデザイナーのためのAjaxツール、Adobeの「Spry framework」とは? (MYCOMジャーナル)ネタ。
おもしろそうだなあと思ったが、どっちかというと今のところは@homepageで使いたい。今日はXML生成まではできたが・・・
LaCoocanは、MySQLを使えるようになったらしい。
サルトルがレヴィナスを手掛かりに現象学の研究を進めたという証拠を「哲学論文集」や「想像力の問題」に探したが、見当たらない。レヴィナスは小阪修平氏の「ガイドブック 哲学の基礎の基礎」を調べると、ハイデガーのフランスにおける紹介者という註が付いていた。
「新・サルトル講義」の13ページ『若き大江健三郎がサルトルの熱心な読者だったことは彼自身の証言からも知られている通りだし、・・・』を読んで、そんなこともあったような気もするけど、大江健三郎が何かサルトルについて言っていないかと、「新しい文学のために」を調べたが、言及はない。新しい発見、「想像力はどんなはたらきをするか(一)」では柳田国男の「海上への道」が引用され、(二)では、バシュラールの「空と夢」が引用されていた。もっともバシュラールについて更新日記で言及したことはいままでないが・・・
[Ontology] 意味と実体 [1/9/2005 (Sun.)]あたりから、哲学的思索にはまってきたのだが、世界を記述するということは、世界のモデルを作ることに他ならない。XMLについて考えることも同様な作業を経るのである。
閉じた世界(closed world)を想定しないと、XMLを読み書きできない。人間は多種多様な予測できない情報の群れに常に晒されている。そのなかで、一定の方法で情報を掬い取ることは、情報を識別・分類することである。このようにして、明確に定義された閉じた世界を生み出すことができる。このような世界は一定の知識によって解釈可能である。
一方、一見閉じたように見える世界もより高次の観点から見ると他の世界と関連付けることが可能になる。そのように考えると、閉じているように見えても実は開かれていると言える。閉じた世界など存在しないのである。例えば、Atomのcontentタグの非常に複雑な内容は他の世界への扉である。
さて、このような問題は哲学的にはどのような問題に帰着するのだろう。
内田樹氏のサイトで、レヴィナスという名を見て、誰だろうと思った。大江健三郎の「新しい文学のために」から想像力の問題を考え始めて、サルトルの「想像力の問題」を思い出し、[本] 新しい混沌 [12/11/2005 (Sun.)]にある澤田直氏の「新・サルトル講義」を再びひっくり返していると、レヴィナスの名が見える。サルトルはエマニュエル・レヴィナスの「フッサール現象学における直感の理論」(1930)を手掛かりに現象学の研究を進めたことがわかった。
註 私の知覚を構成するこのやり方は厳密な意味で私に固有なものであろう。読者は自分の採用する仕方を各自決定されるがよかろう。 (63ページ: J.P.サルトル「想像力の問題」)
 Jean-Paul Sartre著、「サルトル全集 第12巻 想像力の問題 - 想像力の現象学的心理学」、人文書院、昭和46(1971)年4月10日重版(昭和30(1955)年1月10日初版、原著: L'imaginaire(1940))、394ページ
Jean-Paul Sartre著、「サルトル全集 第12巻 想像力の問題 - 想像力の現象学的心理学」、人文書院、昭和46(1971)年4月10日重版(昭和30(1955)年1月10日初版、原著: L'imaginaire(1940))、394ページ昼の二時過ぎに散歩に出掛けた。空は灰色の雲が垂れ込め、水蒸気が身体の周りに凝縮して微細な水滴が今にも出現しそうな雰囲気だ。微かな雨がわからないようにそっと触れていく。家内からこの天気で傘を持っていかないなんて、なんて言われそうだなと思いながら、ままよと歩き続ける。御幸ジャスコのフタバ図書で本を眺める。
まんがや児童書が多過ぎるよと思いながら、新書のコーナーで内田タツルの本を探す。「武田鉄矢の今朝の三枚おろし」ネタなんだが、毎朝、車で聴きながら走る。よく本の話が出てくる。最近の武田鉄矢はテレビで見ると哲学者の風貌をしている。先週から、出てきているのが内田タツルの「先生はえらい」である。内田、内田、内田っと・・・あった。内田樹著、「先生はえらい」、ちくまプリマー新書 002、筑摩書房、2005年1月25日初版第1刷、175ページ、760円。ちくまプリマー新書のプリマーは、primerの入門書という意味だろう。中学生・高校生相手の本らしい。ページ数も通常の新書や文庫に比べて50ページ程度少ない。紙質が固めで分厚いので他の文書と同じボリュームに見える。この本はよい。
ついでにといってはなんだが、なだいなだ著、「こころの底に見えたもの」、ちくまプリマー新書 019、筑摩書房、2005年9月10日初版第1刷、175ページ、760円。「ちくま少年図書館」の「心の底をのぞいたら」という1971年の本の30年以上を経た続編ということで購入。まえがきがいずれもおもしろい。なだ氏のほうには友人の心理学者が亡くなった話が書いてあるので、おもしろいとは不謹慎だが・・・装丁が洒落ていて、デザインもよし。しかし、少年少女達は読んでくれるだろうか・・・
 ちくまプリマー新書
ちくまプリマー新書レジを済ませると、雨が降り出してはいないかと心配しながらエスカレータを降りる。ジャスコの入り口から、横断歩道で待つ人の姿が見える。少し外は明るくなっている。帰り道では、日が差して背中が温かい。
疑問を調べる。課外授業〜ようこそ先輩〜ネタ。今朝の再放送を見た。
先輩の広瀬先生は、2003年度のイグ・ノーベル化学賞受賞者である。受賞理由は、
Yukio Hirose of Kanazawa University, for his chemical investigation of a bronze statue, in the city of Kanazawa, that fails to attract pigeons.
ヒ素の含有量の多い銅像には鳥は近づかないのだ。昔は、銅の溶融温度を下げるためにヒ素を入れていたらしい。
コーヒー学講座を金沢大学で開講されているそうだ。工学的に解明されたコーヒーの淹れ方というのもおもしろそうである。「コーヒー学講義」を読んでみよう。
日常生活の中で疑問点はいろいろ出てきても、解明するためには科学的な観測手段が必要になる。たとえば、今年は花粉症が杉の花粉の飛ぶ期間、2-4月よりも、5月以降のヒノキの花粉の時期のほうがアレルギー症状が強かった。今年の特徴は、テレビでも少し話題になったが、黄砂の量が例年と比べてかなり多かったことで、花粉アレルギー症状を悪化させている可能性があるらしい。これを定量的に調べようと思うと少なくとも顕微鏡が必要である。毎日の花粉と黄砂の降り積もる量とアレルギー症状との関連を測定する必要がある。黄砂は、中国の工場地帯の上空を通過する時に、様々な化学物質を吸着して飛来するという話なので、何が吸着しているのか分析する必要もあるだろう。
最近は養老先生の影響もあって、床を蠢いている小さな虫を見ると興味を持つ。この虫は何の種類なんだろう。調べるためにはやはり顕微鏡がいるなあ。
 記憶の断片
記憶の断片課外授業〜ようこそ先輩〜、NHK教育 2006年5月28日再放送「なんで?なんで?が化学のはじまり」金沢市立明成小学校、広瀬幸雄 (自然化学者)
イグ・ノーベル賞は、インターネットを使って、人の臍のゴマを世界から集めて組成を調べ、衣類の繊維が臍に入り込んで固まったものであることを解明した研究にも与えられている。そんな楽しい研究がたくさんできたら、世界も平和になるかもしれないね。
スラッシュドット ジャパン | Googleが画像管理ソフト「Picasa」のLinux版をリリースネタ。Google Desktopが動くようになれば、Linuxをプラットフォームにすることを検討してもいいなと思う。
マイクロソフトのOpen XML、ISO承認の可能性低し--ガートナー - ZDNet Japanネタ。
文書のフォーマットは当然のことながら大変複雑である。文書の内容、表紙・まえがき・あとがき・目次・章・項・段落・表・リスト・図・画像・引用・参考文献のなどの文書構成要素とその配置による文書構造、フォントの選択とページ・段組による表現、印刷用データ、すべてを指定する必要があるからである。
千夜千冊の「特別対談 ウェブと活字の臨界点に立って」には、表意文字の縦組みによる見え方の違いについての言及があるが、そこまでの思い入れがこのようなODFやOpen XMLの規格に盛り込まれている可能性は低いのではと思う。Webにおける表現は、いずれ書物の表現に追いつき超えるべきものである。索引や年表を使って縦横無尽に全7巻の内容にアクセスできるようにするとあるが、このような索引機能はハイパーテキストのほうが優れていると思う。千夜千冊のWeb的読み方のようなものを考えるのもおもしろいかもしれない。
超音波エコーによる胆嚢ポリープや脂肪肝などの内臓定期診断とベースのデータを取るための肝臓癌腫瘍マーカー測定用の採血。超音波エコーでは、腎臓結石は検出できるが、癌はサイズが1cm程度にならないと検出できないらしい。会社の春の定期健診では久し振りに血液検査はすべて問題なしだったが、半年に一回は見てもらおうかと思う。それから、医者を2階から3階へはしごして、先日のメラノーマを取り上げたテレビ番組の影響で、足の爪の黒くなった内出血と思われる部分とほくろの検査を受けた。ほくろはまったく問題ないが、足の爪のほうは組織検査をしないと100%大丈夫とは言えないらしい。爪の外側に異常はなく、問題なさそうなので、爪の組織を傷つける組織検査はせずに、デジカメで撮影して、1ヶ月後の変化を見ることになった。爪の伸びで内出血かどうかがわかる。足の爪は1mm/月のスピードでしか伸びないので簡単にはわかりにくいらしい。少し、安心。
「眼の誕生」は大変おもしろくて、翻訳も読みやすく、あっという間に読み終えてしまった。一種の推理小説のようなものである。生物が生存競争を生き延びるために環境に適応して進化してきたということがよくわかったのだが、人間も生物として生存競争に打ち勝つという基本的な仕組みを体現しているはずだという観点からは、他の生物から見れば、恐怖の生物として見えているのかもしれないとも思う。最早単なる生物とは言えなくなりつつあるのかもしれないが・・・
続いて、読み終えたのが、養老孟司・テリー伊藤著、「日本人の正体」、宝島社新書 207、宝島社、2006年5月4日第2刷(2006年4月14日第1刷)、238ページ、762円。2004年8月発行の「オバサンとサムライ」の新書化である。「子供には昔は二つの世界があった。人間の世界と自然の世界と。今は自然の世界がなくなって、逃げるところがなくなった。」というような話が参勤交代の話と結び付いている。身体を使うと思考回路が変わる。ストレス解消には「身体を使え」、自信がなければ文字通り「勝手にしろ」っていうのが結論である。日本人の正体が書かれているのかどうかはよくわからないが、外国に比べて日本はうまくやっているらしい。
診察待合室の時間つぶしに持っていったのが、司馬遼太郎、ドナルド・キーン対談「日本人と日本文化」、中公文庫 し-6-46、中央公論新社、2003年7月25日改版5刷(1996年8月18日改版、1984年4月10日初版)、245ページ、552円。昭和47年5月、中央公論社刊、中公新書285だから、元は1972年の本だ。千夜千冊の擱筆となった柳田国男の遺作「海上の道」には、こんなことを解明したいというような課題として、「知りたいと思う事二三」というメモを残しているそうだ。古いせいか、門外漢には既にわからない問題に思えるが、民俗学的な観点から、日本という国を知るためには必要なことだったのだろう。司馬・キーン対談では、日本の古典文学や歴史から日本文化や日本人についての考察が語られている。1972年の本だから題材が古く、最近はあまり話題に上らず、耳や眼にする機会がないものばかりだが、現在の日本の原点のようなものが外国と対比して語られていくのは興趣深い。もう一度、このような歴史的な事実や古典文学が新しい視点からわかりやすく見直される機会があれば楽しいだろうと思う。
最近、読み直しているのが、大江健三郎著、「新しい文学のために」、岩波新書(新赤版)1、1988年4月28日第3刷(1988年1月20日第1刷)、218ページ、480円。8章の「文学は世界のモデルをつくる」というタイトルなどに惹かれたからである。文学もある意味、一種の知識を記述する方法である。想像力によって作られる仮想世界なのかもしれない。
医者からの帰りには雨が落ち始めて、走って帰った。日記を書いているといつのまにか勢いが強まり、ザーッと低い音を立て始めた。昼からはケーブルテレビのデジタル化について説明に来る。はて、セットトップボックスを付けるデジタルテレビは問題ないけど、アナログテレビはどうなるんだろう。
デジタルコースへの変更について広島ケーブルテレビの営業の人が詳しく説明してくれた。当面、CSデジタル放送のチャンネル数が増える。しかし、単にアナログがデジタルに変わるだけでは画質の向上はそれほどでもないらしい。BSのデジタルハイビジョン放送はすごいらしいが。地上波デジタル放送が始まる前だから、今のところCSデジタルやBSデジタルを見て、デジタル放送というものを知るしかない。広島は地上波デジタル放送の開始は10月から。アナログテレビは何も変わらない。
擱筆というのは、筆を置くという意である。第1144夜 松岡正剛の千夜千冊「海上の道」柳田国男が、第一期放埓篇の最後を飾った。
スラッシュドット ジャパン | Googleは「素人が持ってきた物を素人が論評し素人が見る」ためのもの?ネタ。Googleのページランクアルゴリズムへの批判だが、例外はあるにしてもGoogleの有効性は証明済みだろう。代わりになるものがあるなら、それを示してからでないと単なる批判に終わってしまう。
有効性を認めるにせよ、しないにせよ、自分で納得できない、いかがわしい変な結果が得られた場合は、誰も検索結果を信用しないから特に害もない。検索結果が信頼の置けるものかどうか、常に検索者は常識で判断している。大体こんな結果が得られるだろうと予測しながら検索はするものだ。なんでもかんでも鵜呑みにする人はいないだろう。
マイクロソフト、「Windows Live Local」の機能を強化 - CNET Japanネタ。
bird's eyeって、Pictometryが作っているらしいが、コストに問題が出そうな気がするけどね。
 Windows Live Local
Windows Live Localセマンティックウェブ、導入準備が整う--T・バーナーズ・リー氏が講演 - CNET Japanネタ。
少し調べてみるかな。
おもしろいけど、面倒くさそう(^^;)
この5月は日照時間が記録的に短いらしい。確かに雨が多い。今日も午前中は雨だった。寒冷前線が通り過ぎた。蒸し暑いと感じる中をお昼の散歩。
帰宅すると、フォーサイトが届いている。シリコンバレーからの手紙 117 には、「九六年夏」にも似た未来創造への狂気が溢れる、とある。高性能コンピュータはどこにでもあり、使うテクノロジーも環境も揃っている。この未来創造には誰もが参画できるのではと思う。
アンドリュー・パーカー著、「眼の誕生 - カンブリア紀大進化の謎を解く」(草思社、2006;原著: 2003)読了。生物の感覚のうち、聴覚、触覚、味覚、嗅覚の進化は徐々に起こった。視覚はある時点、すなわち、5億4,300万年前のカンブリア紀の初まりに急激に進化した。生物というものは不思議なものだと今更ながら思う。人類の歴史は遡っても19.5万年だ。文明の歴史は高々数千年でしかない。生物学的な進化は気の遠くなるような時間を要するのだ。
[本] 最近購入した本 - 時間を越えろ [5/5/2006 (Fri.)]では黴の生えたような考古学という言葉を使ったが、最近は、進化生物学という言葉がある。生物学の考古学は古生物学と呼ぶ。進化生物学がどのようにして、進化を研究するのかを知るのは大変おもしろい。視覚の進化の謎解きに是非参加してみることをお薦めする。
色は脳の中に存在するだけで、可視光の波長の差異を色に変換して見ている。と考えるだけでも、また不思議に思えてくる。視覚も不思議なものである。三葉虫の進化を勉強しながら、人間とは何かを考えるのも一興である。
PS3はいかなる位置づけとなるのか - CNET Japanネタ。
PlayStation 3は、PlayStation 2対比コストパフォーマンスは相当向上していると思われる。PS3 Linuxは、少なくともPS2のような32MBメインメモリで動作するLinuxではない。問題はLinux上でどのようなアプリケーションが動くかである。それに関する情報は今のところ洩れてこない。【続報】PlayStation 3はPS2互換,フルBD,フルHD,最新HDMI,HDD搭載:ITproで、「ホームサーバー機能を備える」としているぐらいしかない。プレステ3の60GB版は7万5,390円のような記事は出始めているが・・・
総務省調査、携帯からのネット利用がパソコンを上回るネタ。携帯のネット利用がPCを上回るという記事に過剰に反応してしまった。携帯なんかでネット利用ができるはずがないというのが理由である。総務省の携帯でのネット利用用途を見ると、「連絡・情報交換手段」が69.5%である。要はメール利用ということだ。これは確かに便利な場合もあるから必要だが、携帯で文字入力をしたいと思えないことは事実である。しかし、携帯はネット利用に適しているとは思えないという先入観は妥当なものだろうかという反問が浮かんできた。工夫の余地は・・・
Google Mobile at Wap Reviewから、Googleを調べてみると、Google News betaが見つかった。これはWebブラウザからも見ることができる。携帯をシミュレーションしてみよう。
 Google News(1)
Google News(1) Google News(2)
Google News(2)使えそうな画面ではある。携帯のプラウザに、本サイトを含めて、いくつかのサイトを登録してみた。写真もキチンと表示されるが、表示スピードが遅い。暇つぶしに見る可能性はあるが、実用的ではないし、コストがさらに必要となる。本でも読んだほうがよさそうだ。ながら族的、iPod的利用というのはあるかもしれないが、検索というような作業をまどろこしい携帯画面でやりたいとは思わないだろう。この分野は、画面サイズ的な観点からは、PSPやDSなどのゲーム機のWebブラウザを使うか、いわゆるPDAで行う作業の領域に属するのではと思う。
携帯で本格的にググるためには、通信スピードの向上とコストの低減、それから、電池寿命の向上もキーになるだろう。やはり、画面サイズの拡大もかな。しかし、これは携帯性を損なう。携帯で常時接続ができれば、新しい世界が生まれるかもしれない。
昨晩の会食の帰りに、御幸ジャスコのフタバ図書に寄った。佐々木俊尚著、「グーグル Google - 既存のビジネスを破壊する」、文春新書 501、文藝春秋、2006年4月20日第1刷、2006年5月15日第5刷、248ページ、760円を買うためだ。文書系がどこに置いてあるのか、少しばかり手間取ったが、ないはずはないよなとしばらくウロウロした。ようやくGoogleが巷の話題になりはじめたかと思うが、まだ、日本ではYahooのほうがよく使われているらしい。よくもわるくもGoogleは有名になってきた。Googleについては初期の頃から使ってきて、ほとんど知っているので、本のほうはどのようなスタンスで、どの程度のことが書いてあるのか調べるだけのつもり。あとがきから逆に遡って読み始めた。キーワード広告の威力やアドセンス停止処分のトラブルなどについては知らなかったので、ビジネス世界のGoogleについては参考になった。
個人の能力や力を拡張するという意味では、使い方によるわけだが、Googleは興味深い枠組みを提供しつつある。米Google、Ajax開発ツール「Google Web Toolkit」のベータ版を公開 (MYCOMジャーナル)から、Google Web Toolkit - Build AJAX apps in the Java languageのサンプルを見ていて、Google Readerのデザインを思い出した。
デスクトップのあらゆる場所にGoogleの刻印が標され、既に自作のデスクトップCGI以外は、Googleのコンテンツで満たされようとしている。個人の能力を拡張するためには、自分でプログラミングをするしかないと僕は信じているのだが、Google Mapsのように、Googleがプログラマブルになるのは大変素晴らしいことだと思う。Googleを如何にプログラムするか、今後は、日曜プログラマの大工仕事になるのかもしれない。
ひんやりとした風が窓から入ってくる。久し振りに広がった青空に、筋を引いた高層雲が停止している。しばらく雨が多く、海や山も濃霧に包まれていた。台風1号の影響もあったようだが、梅雨の走りという表現も天気予報で聞かれた。今日は散歩日和だ。
物語、歌、俳句、随筆、日記、事典、辞典、小説、詩、新聞、論文、専門書、シソーラス、データベース、プログラム、HTML、XML、RDF、数式・・・
NotebookはWebページを編集するツールとして使えそうだ。
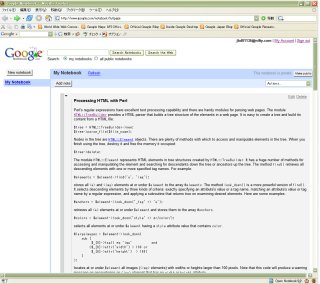 Google Notebook
Google NotebookGoogle Talkもおもしろそうだなあ。Nokiaの端末も使ってみたい感じ。ケータイの世界が変わりそうだ。
Ajaxを利用し、ブラウザ上でデスクトップと同じ機能を提供する「StartForce」 - CNET Japanネタ。おもしろいけど、実用性は?
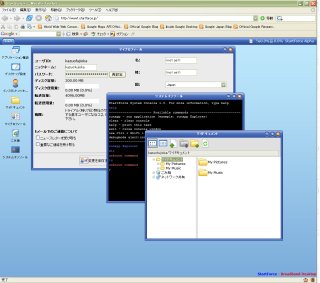 Startforce
Startforce主要開発者が語るグーグルとFirefoxの深い関係 - CNET Japanネタ。大変興味深いインタビューだ。Firefox 3というのはすごいものになりそうだ。キーワードはSVG。
取り扱うデータがテキストであるが故に、テキスト処理をする立場からは、Webブラウザがアプリケーションのプラットホームになるのが、大変効率が良いと以前から考えていた。Webブラウザの機能が高度になればなるほど、おもしろい世界が表出するはずである。
atom2html.cgiやrn2atom.cgiを書いてみて、Atomはおもしろいと思った。contentにxhtmlをそのまま埋め込めるからだ。そして、microformatsを応用すると、日記の書き方がより便利にならないかと思い始めている。すべての表現要素にメタ情報を付加して、かつ表現構造としてもスムースにつながるようにしたい。要はCSSの考え方に近い。他のサイトの表現を少し勉強してみるかな。Atomとmicroformatsの応用が当面の課題だ。
Atomを題材にWebとデスクトップの融合に関する記事を少しまとめたのだが、概念図をいろいろと弄っているうちに、Dlogという言葉が浮かんだ。Diary Logである。1月分連なっている更新日記にふさわしいかな(^^)Webのリソースとデスクトップのリソースが出会う場としての日記にふさわしい執筆用XMLリソースインターフェース(XRI)を作成できないかと考えている。そのためにAtomとmicroformatsの下に、データベースを置こうかと思う。問い合わせるためにいつまでもgrepしているわけにはいかないだろう。PerlでRDBを取り扱うのは、JPDB以来の夢であった。
Google、豊富なミニアプリ対応の「Google Desktop 4」などを一斉発表 (MYCOMジャーナル)、米Google,数百種の「Gadgets」やメタ情報をWebページに埋め込む「Co-op」など公開:ITproネタ。さて、日曜プログラマも音を上げそうな勢いで、新しい要素が登場する。Google Desktop Gadgets APIって何だろう。
結局、Desktop APIらしいが。ブック検索も進み始めた。
選択肢がいろいろと増えるのはよいことだ。Googleのデスクトップがどのように変貌していくのか大変楽しみである。
PS2初期価格: 39,800円 + HDD: 10,000円 = 49,800円という価格予想([PlayStation] PLAYSTATION3 続報と価格予想第2弾 - Longhorn PC vs PS3 [5/18/2005 (Wed.)])ははずれ、+10,000円という結果に終わった。内容的には別に驚く価格ではないだろう。安いとさえ言えるのかもしれない。メモリが少ないのが心配なだけである。32MBのようなことにはならないけど、スーパーコンピュータ足り得るのか。
「Apollo」プロジェクトでFlashの「脱ブラウザ」をねらうアドビ - CNET Japanネタ。詳細は不明だが、ActionScript on Desktopってことかな?
だれもが同じ方向に向かっている。それは、ウェブページやアプリケーション、マルチメディアコンテンツの間にある壁をなくすという方向だ。
改良点は次の通り。本スクリプトはjperl用です。→ atom2html
【特別インタビュー】「PS3は買ったその日から進化する」と久多良木氏:ITproネタ。
59,800円という価格でどの程度のスピードで売れるだろうか。まだ、半年先の話だが、Linuxとして使って、どの程度のパフォーマンスが出るのだろうか。Linux-PS3として使うなら、やはり60GBHDD搭載になるのだろうから、69,800円は準備が必要かな・・・ディスプレイの準備と・・・
PS3は5万9800円で11月11日に登場--20GバイトHDDを標準搭載 - CNET Japanネタ。予想よりも、10,000円高かった。アップルを待ち受ける「成長の限界」 - CNET Japanネタも合わせて。
さて、・・・まあ読めばわかること(^^;)ソフトウェアがまだ追いついていない?アップルもどうなる。現在のWindowsマシンからの買い替え・買い増しを誘導できるかどうかだが。
しばらく、現実的なXMLやPerlの技術的な話ばかりになってしまった。いろいろと題材はあるが、すべてを日記として書き残すには時間が足りない。断片的になるが、少しずつ残しておこう。最近購入した本のリスト。
博多で、アントニオ・R・ダマシオ著、「感じる脳 情動と感情の脳科学 よみがえるスピノザ」、ダイヤモンド社(邦訳: 2005、原著: 2003、原題: Looking for Spinoza - Joy,Sorrow, and the Feeling Brain)を買って以降、御幸ジャスコのフタバ図書で購入した。近くにそこそこの書籍量がある本屋ができて入り浸っている感じ。買い過ぎになりそうだ。
ダマシオの名はおそらく「デカルトの誤り(Descartes' Error)」(原著: 1994、邦題: 「生存する脳」)というタイトルで知っていたが、読んではいなかった。もう一冊は、「事象の感覚(The Feelings of What Happens)」(原著: 1999、邦題: 「無意識の脳 自己意識の脳」)。脳科学ブームだからといって、タイトルはどうかなと思う。宣伝をうまくすれば、こういう本は売れるべき人には売れるはずだ。原題の「スピノザを探して - 喜び、悲しみ、そして感じる脳」というタイトルからあるようにこの本は哲学書としての側面を持つようだ。スピノザって少し古い哲学者というイメージしかないんだけど、この本でよく理解できるかもしれない。もっとも重要なところは、人間はまず身体で感じたことが、心に感情となって現れるということである。心で感じたことが、身体的症状として現れるのではない。身体自体がまず感じて、身体的症状が現れ、その結果、心が感情を持つのが自然な流れなのである。これは生物の進化の順序に対応していると考えられ、大変興味深い。これは身体がないと心は感情を持てないということを意味している。脳だけを切り離して感情は得られないのである。
人工知能ネタから次第に自然知能ネタへと移りつつある。人間をよりよく知ることが、人工知能の発展に資するのは間違いないだろうと思うし、人間とは何かこそが最もおもしろいテーマかもしれないと考え始めている。そうすると、対象はなんでもありということになってきて、収拾がつかなくなりそうだが、結局は選択するのだから、まあなんとかなるだろう。
20世紀の半ばから後半の科学の急速な進展は、最近の本に現れるテーマに新しさをもたらすようになった。脳科学関係の本もその一つだが、最近の利根川先生や山元先生の本を読んでいると、脳科学は分子免疫学、分子遺伝学などの分子生物学を基盤とするようになるのかもしれないと思う。宇宙論から万物理論(昔なら素粒子論)は新しい世界観をもたらしつつある。人間の認知領域は宇宙さえも越えていくのだろうか。自己組織化、フラクタルなどの複雑系の科学は自然の複雑さを解き明かすかもしれない。これらの背景には、観測・測定技術とコンピュータによる計算の高速化、可視化の技術の進歩がある。娯楽の映画においても、既に現実世界と見紛う映像が生み出されるようになり、現実には見ることのできない映像さえ生み出すようになっている。人間はある意味で視覚を拡張したのである。
我々が取り扱う時間のスケールは、無限から、宇宙の年齢である百数十億年、銀河系の年齢、太陽系の年齢、地球の年齢(46億年)、地球上の生命進化の歴史(35億年)、人類の歴史、人間の残した文明の歴史、そして、最近の一世代から三世代、40-120年間程度の人間個体の寿命である。本を読むことによって、人間個体が直接経験可能なタイムスパンの限界を越えることが可能になる。人間はすべてを知りたいと考えている。上記のリストの最後にあるアンドリュー・パーカーは、5億4300万年前、生命最初の「眼」がすべてを変えたという説を唱えている。5億4300万年前というのはカンブリア紀のはじまりである。生命はカンブリア紀に大進化を遂げ、多様な生命が生まれた。その謎に考古学が迫ろうとしている。考古学がなぜそのようなことを証明できるのか、読むのが大変楽しみである。
5番目は、「21世紀への対話」として2000年に行われた読売新聞の小澤征爾氏と大江健三郎氏の対談をベースに編集された本。2001年に単行本としても出ている。表紙写真がなんとも言えずよかったのと両氏とも「同時代」の大切な人なので購入した。大江健三郎の本は、いろいろと持っていたはずだか、少し探してみると、手元には比較的新しいもの4冊しか残っていない。「われらの狂気を生き延びる道を教えよ」(初出: 1969、新潮文庫: 1975)、「みずから我が涙をぬぐいたまう日」(1972)、「同時代としての戦後」(1973)、「新しい文学のために」(1988)。ぜんぜん新しくないなあ(^^;)最近の仕事を探してみよう。このように本棚を調べ始めると引き出した本の山が増えて、周辺はごった返しているのだが、まとまりを作るという意味では整理になるし、記憶を呼び起こし、再構成するためにも有効である。
 「同じ年に生まれて」
「同じ年に生まれて」いろいろ調べていると、UTF-8フラグをONにすることにも慣れてくる。慣れれば、UTF-8フラグをONにして取り扱うこともそれほど不自由ではないとも感じ始める。人間とはそういうものである(^^;)OFFにする場合とONにする場合を簡単なスクリプトでまとめておこう。
UTF-8フラグをOFFにする場合
$str = "今日はソレイユに行ってきた。";
print "$str: ",length $str,"\n";
if(utf8::is_utf8($str)){
print "「$str」は、そうだよ、UTF-8。\n";
}else{
print "「$str」は、UTF-8ではないですよ。\n";
}
open OUT, ">out.txt";
if($str =~ /ソレイユ/){
print "ソレイユにマッチしました。\n";
print OUT $str,"\n";
}else{
print "ソレイユにマッチしません。\n";
}
close(OUT);
UTF-8フラグをONにする場合
use utf8;
binmode STDOUT, ":utf8";
$str = "今日はソレイユに行ってきた。";
print "$str: ",length $str,"\n";
if(utf8::is_utf8($str)){
print "「$str」は、そうだよ、UTF-8。\n";
}else{
print "「$str」は、UTF-8ではないですよ。\n";
}
open OUT, ">:utf8", "out.txt";
if($str =~ /ソレイユ/){
print "ソレイユにマッチしました。\n";
print OUT $str,"\n";
}else{
print "ソレイユにマッチしません。\n";
}
close(OUT);
謎、その一。上記の「open OUT, ">:utf8", "out.txt";」の行を次の2行に変えると、なぜかONにはならない。
binmode OUT, ":utf8"; open OUT, ">out.txt";
追記: [TSperl:681] use strict; use warnings; をつけようキャンペーン。Bruce.さんよりコメントをいただく。順序が逆。開いていないファイルハンドルをbinmodeにしようとしても、何も起こらない。逆にすれば意図通り動くことを確認。
謎、その二。UTF-8フラグをONにした場合とOFFにした場合でテキスト処理の仕方がどう違ってくるのかというのが、次の問題になるだろう。UTF-8フラグがOFFの場合でも、上記のスクリプトの場合、正規表現はバイトデータのUTF-8文字列で正常にマッチが起こったように見える。[Perl] 文字列のUTF-8フラグをOFFにして取り扱う [5/3/2006 (Wed.)]の話([Web Development] Perl 5.8で書いたデスクトップCGIを使って、更新日記 Atom 1.0 配信開始 [5/2/2006 (Tue.)])に出てくるスクリプトも問題なく動いたが、正規表現パターンはASCII文字列のみからなっていた。PERLUNICODE(perlunicode - perldoc.perl.org)→DESCRIPTION→Regular Expressionsの項には、UTF-8フラグとの関連における記述はないが、Security Implications of Unicodeにバイトデータと文字(Unicode)データとには僅かな差しかないと言及があるので、それさえ注意すればよさそうだ。
これで、Perl 5.8を使う基盤になる部分について、大体のチェックが終了したかな。
注意: 上記のスクリプトはUTF-8に変換して保存してテストしなければ意味がない。最近のPerl(v5.8.7以降かな?)はUTF-8テキストにBOMが付いていても読めるようになった。
追記: [TSperl:681] use strict; use warnings; をつけようキャンペーン。Bruce.さんによれば、5.8.5のperlunicodeマニュアルに、BOM自動検出の記載が最初に載ったということである。
Official Google Blog: Google Maps in Europeネタ。ブログタイトルから気が付くのが遅れたが、Google Maps API Version 2が出ていた。The Google Maps API BlogのAtom配信もチェックしないと。
Google Maps API 2 Upgrade Guideに基づいて、なんとか、Walking World Project Google Maps API ( v1 | v2 ) 版のように元の版のページから、Version 2版に書き換えた。そこまで変えちゃうのという大幅な変更なので少し戸惑ったが、書き換えにはなんとか成功。見掛けも何も変わらないのが残念だが(^^;)
まだはじまったばかりだからそれほどの負担ではないけど、過去のページに埋め込んだ地図をいちいち書き換えるのは面倒だなあ。次のバージョンアップでは、上位互換性を取るように仕様の変更はお願いしたいものだ。こちらも変更の負担を小さくする工夫が必要かな。今回は急場しのぎの変更で対応したが、zoomの数値の変更は地図を呼び出す部分の変更も必要になる。新しく書く場合は、呼び出し関数名を変えるかな。
驚いたのは、Firefoxにおいても、ToggleVisibilityとGoogle Mapの表示を併用した部分で地図の描画ができなくなったことだ。IE 6/7で表示できない原因をいろいろと調べてみて、よくわからないままにきているのだが。取り敢えず、その部分はVersion 1に戻した。
Perl 5.8で書いたデスクトップCGIを使って、更新日記 Atom 1.0 配信開始(web)への追記。Wide character in print ...のメッセージを消せないのもやはり問題なので、UTF-8フラグの問題をいろいろと調べてみた。
UTF-8で書かれたスクリプトに埋め込まれた文字列にはUTF-8フラグは立たないので、単にprint出力してもWide character...メッセージは出ない。Unicode::JapaneseモジュールによるSJIS→UTF-8変換文字列にはUTF-8フラグが立っているので、メッセージが出る。変換時にUTF-8フラグが立たないようにするには、Encodeモジュールのfrom_to関数を使えばよい。from_toを使う場合、UTF-8文字コードに変換されるが、UTF-8フラグはOFFのままになる。
問題は取り敢えず解決したが、UTF-8フラグの制御を常に意識してスクリプトを書くのは面倒であることも間違いない。でも、それを意識すれば問題は起きないということでもある。最大の問題はモジュールだろう。
昨夜遅く、日付変更線を大きく跨いでから、Zazelさんから、なぜWebサイトにRSSやAtomのファイルがあることを知らせるlinkタグを使わないのというメールをいただいた。
実は更新日記でmetaタグだけは使っていたが、linkタグだけでなくmetaタグを含めてどれほど有用か計りかねていたからだ。linkタグの存在は強く意識してはいなかった。最近のFirefoxではサイトを表示したときに、linkタグを調べて、アドレス欄の最後にフィードアイコンを表示しているのだそうだ。このフィードアイコンはライブブックマークの追加のためのものである。ライブブックマークを登録するとツールバーにフィードアイコンが自動的に作成され、記事リストのプルダウンメニューが出てくる。Firefoxは一種のフィードリーダーでもある。手軽に興味のあるサイトの状況を知ることができる。Googleのような検索エンジンが発達した今、metaタグでkeywordsやdescriptionを記載するより、linkタグで、RSS/Atomファイルの存在を知らせるべきだろうと思う。
ということで、更新日記にも、linkタグを追加し、Atom配信用にフィードアイコンを設置してみた。
お蔭様で、昨日、「TS Networkのために」バージョン2は、ほぼ6年を要して10万アクセスを越えることができました。ありがとうございました。おそらく、バージョン3を作ることが今年の趣味になりそう(^^;)更新日記「日曜プログラマのひとりごと」を媒介して、サイト全体の持つ情報を統合的に扱う仕組みにまで展開していきたいと考えている。
Googleが最近、Google Data APIs(Beta) Developer's Guide(Google Data APIs Overview)を発表した。僕が先日印刷したときは、4/23に更新されたページだった。今日も更新されている。GDataと縮めて呼ばれるGoogle Data APIsは、Atom 1.0とRSS 2.0を基盤とするものとしているが、Atom APIの延長上にある、Webにおける情報のフィード、クエリ、そして結果を得るための、より一般化したAPIと言えるだろう。
RSS 2.0では、ブログ記事そのものすべてを載せて配信し、RSSリーダーでブログを読む文化を生み出した。Atom 1.0は、フォーマットとしてはそれほど広まってはいないが、GoogleがBloggerでAtom APIを採用したために、注目度が高まっている。
Semantic Webで使うことが想定されているRDFは、そのままXHTMLを埋め込むことができないから、記事を表現構造を含めて埋め込もうとすると、CDATAセクションやcontent:encoded要素に頼らざるを得ない。昨年末に出たThe Atom Syndication Format(RFC4287)のサンプルを見ると、content要素に、XHTMLで書かれた記事ならば、そのまま簡単に埋め込むことができることがわかる。その逆も同じことである。Atomを通じて、XMLをベースとしたWebの姿が見えてきている。
rn2rss.cgiをTeraPadでUTF-8コード指定で保存し、RSS 1.0出力からAtom 1.0出力になるように大幅に改造して、Perl 5.8ベースに移植した。content要素に、記事内容部分のSJIS文字コードのHTMLを、UTF-8文字コードのXHTMLに変換しつつ出力する。例によって、UTF-8フラグの問題は混沌としているように見えるが、スクリプトの文字コードをUTF-8で書くこと以外は、jperlとまったく同じように書く。use Encodeもuse encodingも一切使わない。Unicode::Japaneseモジュールを使ったSJIS文字コードのHTMLページのUTF-8への変換部分はそのまま使える。ただ、Wide character in printの下記のようなメッセージが出ないようにすることは、いろいろと試みたが、すべてのprint出力で抑制することはできなかった。openプラグマやPerlIOなどでutf8出力を指定して抑制すると、スクリプトに書いたUTF-8文字列部分の出力が文字化けを起こしてしまう。このメッセージはスクリプトのコマンドプロンプトやCGI上での実行を妨げないし、得られる結果もまったく問題はない。
Wide character in print at rn2atom.cgi line 141, <GEN0> line 1097. Wide character in print at rn2atom.cgi line 141, <GEN0> line 1097.
このようなスクリプトは、jperlでも当然書けるのだが、今年計画しつつあるUTF-8をベースとしたXMLとXHTMLを使う新しいプロジェクトの基盤として、テスト的にPerl 5.8を使ってみたいと考えている。Perl 5.8を使うのは新しいデータベース関連のモジュールを使いたいからである。Perl 5.8で書いたCGIはjperlで書いたCGIと簡単に併用できる。CGIで起動するPerlを変えればよいだけである。Apacheでは先頭行に記述するPerlのパスを変えることによって変更する。Anhttpdの場合は、拡張子を変えて、拡張子毎にAnhttpdで起動するPerlを設定すればよい。
全体像も十分描けていないし、準備も不十分な部分もあるが、MicroformatsやAtomを通じた複数の多様なXMLと、表現としてのXHTMLの間の相互変換の可能性が見えてきている。更新日記を、Microformatsで表現される様々な情報を内包したXHTMLからなるテキストデータベースとして運用するという姿が現在の延長線上に見えるのだが、もう一つはRSS/Atomを利用して、関心のあるWebの情報についてもデータベース的蓄積を行って、更新日記の記事と一体化し、更新日記からいずれも引用として取り出せるような枠組みを実現できないかと考えている。さらには記事本体の作成・更新・削除などの管理を含めたデータベースを利用したWeb Publishingの仕組みを、CGIで作ることが可能だろう。今やこのような知的生産の技術が実現可能になってきたと思う。
いくつかの写真を残しておこう。最初と最後の2枚はケータイデジカメで撮影(元の写真は、JPEG:1280×960→320×240)。後の2枚は「写ルンです 400エクストラ」で撮影現像し、FUJICOLOR CDのデジタル化サービスを使ったもの(JPEG:1840×1232→320×214)。アナログ→デジタルの変換はPCのディスプレィで見ると明らかに解像度が低い感じを受けた。使い捨てカメラをアナログの代表にするのもどうかと思うが、変換の仕方にもよるのかもしれない。200万画素のケータイデジカメは解像度について不満はない。少なくとも画質的に、デジタルに変換してでもアナログを使え、という結論は出てこなかった。
 一蘭
一蘭 九州国立博物館
九州国立博物館 光明善寺裏石庭
光明善寺裏石庭 福岡タワーよりシーサイドももち海浜公園を見下ろす
福岡タワーよりシーサイドももち海浜公園を見下ろすNatureの動きにはいつも注意を払っているが、記事だけでなく、以前からPRISM(Publishing Requirements for Industry Standard Metadata)のRSSへの導入やNature Podcast([Podcast] Nature Podcast [12/1/2005(Thu.)])の取り組みにも注目してきた。ここでさらに新たな取り組みが出てきた。それがOTMIである。
OTMIについてはサンプルがあるぐらいで情報不足だが、ATOMのentry要素として実装されている。テキストマイニングということは言語にも依存するから、まだまだこれからだろうと思うが、このような具体的な試みが出てきたことは注目に値するだろう。テキスト処理の大きな分野を形成するはずである。entry要素を見てみよう。XML名前空間には、ATOMを基本の名前空間として、OTMIとPRISMが追加されている。
<entry xmlns:otmi='http://www.nature.com/schema/2006/03/otmi'
xmlns:prism='http://prismstandard.org/namespaces/1.2/basic/'
xmlns='http://www.w3.org/2005/Atom'>
otmi:data主要素の部分を引用してみよう(http://www.nature.com/nature/journal/v440/n7083/otmi/otmi-nature04614.xml)。otmi:data主要素は、otmi:vectors要素とotmi:snippets要素に分かれている。
<otmi:data>
<otmi:vectors>
<otmi:splitregex>(?-mix:\s+\W+|\W+\s+|\s+|\/)</otmi:splitregex>
<otmi:stoplist>
<otmi:stopword>it</otmi:stopword>
・・・
</otmi:stoplist>
<otmi:vector count='59'>data</otmi:vector>
・・・
<otmi:vector count='1'>biologists</otmi:vector>
</otmi:vectors>
<otmi:snippets>
<otmi:splitregex>(?-mix:\.\s+)</otmi:splitregex>
<otmi:snippet>1 )</otmi:snippet>
<otmi:snippet>A collaboration involving hundreds of Internet-connected scientists
raises questions about standards for data sharing</otmi:snippet>
・・・
</otmi:snippets>
</otmi:data>
otmi:vectors要素は、otmi:splitregex要素、otmi:stoplist要素とotmi:vector要素からなる。テキストを単語に分割する正規表現が、otmi:splitregex要素に示され、otmi:stoplist要素は、一般的に文で使われる、文の特徴にはならない冠詞など、出現頻度を数えない単語を、otmi:stopword要素のリストとしてまとめている。otmi:splitregex要素に使われている正規表現は、Perlでもそのまま使えるものである。otmi:vector要素は、記事に出現する単語の出現頻度をcount属性に入れて、出現頻度の多い単語順に並べてある。
otmi:snippets要素には、もう一つのotmi:splitregex要素の正規表現で分割された文が、一つ一つ、otmi:snippet要素として格納されている。snippetとは断片とか、抜粋という意味である。