 �X�V���L - ���j�v���O���}�̂ЂƂ育��
�X�V���L - ���j�v���O���}�̂ЂƂ育������͂�A�����A���ƌ������A���N�̕s�v�c���������BWindows 10��11�Ń^�[�~�i�������R�}���h�v�����v�g(cmd.exe)����PowerShell�Ɉڍs�������Ƃ̉e��������B�K�v�ɔ����A�Ǘ������X�N���v�^�͐���AI�ɏ�����ꂽ�B
while(<DATA>){
chomp;
push(@keywords, $_);
}
while(<>){
chomp;
s/��/�w�r/g;
s/��/�`���E/g;
s/�I/�n�`/g;
s/(�D|�M)��/�t�i���V/g;
s/�S���g/�T���X�x��/g;
s/���z��/�A�W�T�C/g;
s/����/�g�E�J�G�f/g;
s/��|��/�L���E�`�N�g�E/g;
s/�^�u�̖�/�^�u�m�L/g;
s/���m�L�Y�^/�Z�C���E�L�Y�^/g;
s/��/�n�g/g;
s/��/�J����/g;
s/��/�g�r/g;
s/��/�c�o�L/g;
foreach $keyword_category (@keywords){
($keyword, $category) = split(/ /, $keyword_category);
s/([^\#])($keyword)([^ ])/$1\#$2 \($category)$3/; # �s�̒��ōŏ��̂��̂����}�b�`
}
print $_, "\n";
}
__END__
�i���L���n�[ tree|����
�N�X�m�L tree|����
���}���� tree|����
�L���E�`�N�g�E tree|����
�^�u�m�L tree|����
�T���X�x�� tree|����
�T�N�� tree|����
�n�i�~�Y�L tree|����
�c�o�L tree|����
�I���[�u tree|����
�P���L tree|����
�g�E�J�G�f tree|����
�Z�C���E�L���V�o�C Shrub|���
�N�`�i�V Shrub|���
�V�������o�C Shrub|���
�g�x�� Shrub|���
�A�W�T�C Shrub|���
���V�m�c�c�W Shrub|���
�V�i�m�c�c�W Shrub|���
�Z�C���E�L�Y�^ plant|�A��
�L���n�m�u�h�E plant|�A��
�T���V�L�X�~�� plant|�A��
�`�K�� plant|�A��
�G�C fish|��
�`�k fish|��
�X�Y�L fish|��
���� fish|��
�t�i���V �b�k��
�n�` ����
�g���{ ����
�`���E ����
�A�I�T�M bird|��
�R�T�M bird|��
�X�Y�� bird|��
�c�o�� bird|��
�J���X bird|��
�n�N�Z�L���C bird|��
�J���� bird|��
�L bird|��
�g�r bird|��
�n�g bird|��
���� bird|��
���� bird|��
������ ���̑�
�L�m�R �ۗ�
�}�b�V�����[�� �ۗ�
�w�r ���
�D������ �l�H��
�x���` �l�H��
�� ����-��
�� ����-��
�� ����-�A��
�� ����-����
opendir(CHAPS, ".");
@chap_pre_files = grep(/^.+_pre\.txt$/, readdir(CHAPS));
for $chap_pre_file (@chap_pre_files){
($chap_out = $chap_pre_file) =~ s/^(.+)_pre\.txt$/$1\.txt/;
print $chap_out, "\n";
system("perl chap2key.pl $chap_pre_file > $chap_out");
}
closedir(CHAPS);
Perl�Ńo�b�`���̂��̂������H�ڂɂȂ�Ƃ́H
(��) perl�̕W���o�͂�UTF16��BOM�t�ɂȂ�Ǝv���̂ł����AUTF8�ŏo�͂���ɂ͂ǂ�����悢�ł����B
Perl�̕W���o�͂�UTF-16��BOM�t���ɂȂ�Ƃ����́A�ʏ�̎g�����ł͔������܂���BPerl�̃X�N���v�g�̓f�t�H���g�ł̓o�C�g��Ƃ��Ĉ����A����̃G���R�[�f�B���O�����Ȃ�����A�V�X�e�����P�[����X�N���v�g�̃G���R�[�f�B���O�Ɉˑ����܂��B
�������A�������炩�̗��R��UTF-16��BOM�t���ŏo�͂���Ă��܂��ɑ������Ă���A�܂���UTF-8�ŏo�͂������Ƃ������m�ȈӐ}������ꍇ�A�ȉ��̕��@��UTF-8�ŏo�͂��邱�Ƃ��ł��܂��B
1. binmode ���g�p����
�ł���ʓI�Ő����������@�́Abinmode �����g���ĕW���o�� (STDOUT) �̃G���R�[�f�B���O���I��UTF-8�ɐݒ肷�邱�Ƃł��B
Perl use strict; use warnings; use utf8; # �X�N���v�g���̃��e������UTF-8�Ƃ��Ĉ��� binmode(STDOUT, ':utf8'); print "����ɂ��́A���E�I\n";use utf8;: ����̓X�N���v�g�t�@�C�����̂�UTF-8�ŏ�����Ă��邱�Ƃ�Perl�C���^�[�v���^�ɓ`���邽�߂̃v���O�}�ł��B����ɂ��A�X�N���v�g���̕����e�����i��: "����ɂ��́A���E�I"�j��UTF-8�Ƃ��Đ��������߂���܂��B
binmode(STDOUT, ':utf8');: ���ꂪ�d�v�ł��B�W���o�͂ɏ����o���ۂɁAPerl�������I�Ɏ����Ă���UTF-8��������o�C�g��ɕϊ����ďo�͂���悤�Ɏw�����܂��BBOM�͎����I�ɕt������܂���B
2. ���ϐ� PERL_IO_ENCODING ��ݒ肷��
Perl�̎��s���Ɋ��ϐ� PERL_IO_ENCODING ��ݒ肷�邱�Ƃł��A�W���o�͂��܂ނ��ׂĂ�I/O�X�g���[���̃G���R�[�f�B���O��ݒ�ł��܂��B
Bash # �V�F���Ŏ��s����ꍇ export PERL_IO_ENCODING=":utf8" perl your_script.plPerl # your_script.pl use strict; use warnings; use utf8; print "����ɂ��́A���E�I\n";���̕��@�́A�X�N���v�g���C�������ɃG���R�[�f�B���O��ύX�������ꍇ�ɕ֗��ł����A���̃X�N���v�g��I/O�ɂ��e����^����\�������邽�ߒ��ӂ��K�v�ł��B
3. open �v���O�}���g�p����iPerl 5.8�ȍ~�j
open �v���O�}���g���āA�O���[�o����I/O���C���[�̃f�t�H���g�G���R�[�f�B���O��ݒ肷�邱�Ƃ��ł��܂��B
Perl use strict; use warnings; use utf8; use open ':std', ':encoding(UTF-8)'; # �W��I/O���ׂĂ�UTF-8��K�p print "����ɂ��́A���E�I\n";use open ':std', ':encoding(UTF-8)';: ����͕W�����́A�W���o�́A�W���G���[�o�͂��ׂĂ�UTF-8�G���R�[�f�B���O��K�p���܂��B:std �� STDIN, STDOUT, STDERR ��\���܂��B
4. Encode ���W���[���Ŗ����I�ɃG���R�[�h����
����x���ŁA��������I�ɃG���R�[�h���ďo�͂�����@�ł��B�ʏ�͏�L�̕��@�ŏ\���ł����A����ȏŎg�����Ƃ�����܂��B
Perl use strict; use warnings; use utf8; use Encode qw(encode); my $string = "����ɂ��́A���E�I"; print encode('UTF-8', $string);���̕��@�ł́Abinmode ���g�킸�ɁA�������UTF-8�o�C�g��ɕϊ����Ă���o�͂��܂��B
�ǂ̕��@���g���ׂ����H
�ł����������̂� binmode(STDOUT, ':utf8'); �ł��B ����̓X�N���v�g���Ŗ����I�ɃG���R�[�f�B���O��ݒ肵�ABOM�Ȃ���UTF-8�o�͂�ۏ��܂��B
�X�N���v�g�S�̂ň�т����G���R�[�f�B���O���g�������ꍇ�́Ause open ':std', ':encoding(UTF-8)'; ���ǂ��I�����ł��B
�����̃X�N���v�g���C�������Ɉꎞ�I�ɃG���R�[�f�B���O��ύX�������ꍇ�́APERL_IO_ENCODING ���ϐ����֗��ł��B
BOM�ɂ���
UTF-8�ɂ͒ʏ�BOM�͎g�p����܂���BBOM�͎��UTF-16��UTF-32�Ŏg�p����A�o�C�g�I�[�_�[���������߂̂��̂ł��BUTF-8��BOM���t�������ƁA�����̃c�[���Ŗ�肪��������\��������܂��BPerl�� binmode(STDOUT, ':utf8'); ��BOM��t�����Ȃ��悤�ɐv����Ă��܂��B
�������ۂ�Perl�X�N���v�g�̏o�͂�UTF-16��BOM�t���ɂȂ��Ă���̂ł���APerl�̊O���Ɍ��������邩�A���ɓ���Ȑݒ肪����Ă���\��������܂��B��ʓI��Perl�̊��ł͂��̂悤�Ȃ��Ƃ͔������܂���B
(��) Windows���PowerShell��̘b�ł��BWIndows�̏�̃G�f�B�^�ɂ���R���\�[���ł͉��̖����N����Ȃ��̂ł��B
Windows PowerShell��ł�Perl�̕W���o�͂�UTF-16��BOM�t���ɂȂ��Ă��܂��Ƃ����ŁAWindows�̃G�f�B�^�i�����炭GUI�x�[�X��IDE��G�f�B�^�t���̃R���\�[���j�ł͖�肪�N���Ȃ��Ƃ̂��ƁA���m�������܂����B����́APowerShell�̃f�t�H���g�G���R�[�f�B���O��Perl�̏o�͂̈������̑g�ݍ��킹�Ŕ�������\���������ł��B
PowerShell�́A�f�t�H���g��UTF-16�iBOM�t���j���������Ƃ��������߁APerl�̏o�͂�UTF-8�ł����Ă��APowerShell�������UTF-16�Ƃ��ĉ��߂��悤�Ƃ��āA�Ӑ}���Ȃ����ʂɂȂ邱�Ƃ�����܂��B�G�f�B�^�̃R���\�[���ł́A���̃G�f�B�^���̂�UTF-8�𐳂�����������悤�ɐݒ肳��Ă��邽�ߖ�肪�N���Ȃ��̂ł��傤�B
���̖����������APerl�X�N���v�g�̏o�͂�PowerShell��UTF-8�Ƃ��Đ������\�������邽�߂̕��@�͂���������܂��B
PowerShell�ł�UTF-8�o�͂̐ݒ�
�܂��APerl�X�N���v�g���ŏo�͂�UTF-8�ł��邱�Ƃm�ɂ��܂��B����͈ȑO���`���������@�Ɠ����ł����APowerShell���ł̃g���u���V���[�e�B���O�̊�{�ƂȂ�܂��B
Perl # your_script.pl use strict; use warnings; use utf8; # �X�N���v�g���̃��e������UTF-8�Ƃ��Ĉ��� binmode(STDOUT, ':utf8'); # �W���o�͂�UTF-8�Ƃ��Ĉ��� print "����ɂ��́A���E�I\n";����Perl�X�N���v�g�� your_script.pl �Ƃ��ĕۑ����APowerShell������s���܂��B
PowerShell���̑Ή���
Perl�X�N���v�g��UTF-8�ŏo�͂��Ă���ɂ��ւ�炸PowerShell�Ŗ�肪�N����ꍇ�APowerShell����UTF-8�𐳂��������悤�ɐݒ肷��K�v������܂��B
1. PowerShell�̃f�t�H���g�G���R�[�f�B���O��ύX����
����͍ł����ړI�ȕ��@�ł��BPowerShell�̃Z�b�V������v���t�@�C���Ńf�t�H���g�̃G���R�[�f�B���O��UTF-8�ɐݒ肵�܂��B
PowerShell # ���݂̃G���R�[�f�B���O���m�F [Console]::OutputEncoding # UTF-8�ɐݒ�iBOM�Ȃ��j [Console]::OutputEncoding = [System.Text.Encoding]::UTF8 # Perl�X�N���v�g�����s perl your_script.pl���̐ݒ�͌��݂�PowerShell�Z�b�V�����ɂ̂ݓK�p����܂��B�i���I�ɂ������ꍇ�́APowerShell�̃v���t�@�C���X�N���v�g�i�ʏ�� $PROFILE �Ŏ������p�X�j�ɏ�L�̐ݒ��lj����܂��B
2. �o�͂����_�C���N�g����ۂɃG���R�[�f�B���O���w�肷��
�����t�@�C���������̂ł���APowerShell�� Out-File �R�}���h���b�g��_�C���N�g���Z�q (>) ���g���ۂɃG���R�[�f�B���O���w��ł��܂��B
PowerShell # �t�@�C���ɏo�͂���ꍇ perl your_script.pl | Out-File -FilePath output.txt -Encoding Utf8 # �܂��� perl your_script.pl > output.txt -Encoding Utf8���̕��@�ł́APowerShell�̕W���o�͂ɒ��ڕ\���������e�ł͂Ȃ��A�t�@�C���ɕۑ������ۂ̃G���R�[�f�B���O���w�肵�܂��B
3. chcp 65001 �R�}���h���g�p����
����̓��K�V�[�ȃR�}���h�v�����v�g�̃G���R�[�f�B���O�ݒ�ł����APowerShell�ł��e����^���邱�Ƃ�����܂��B
PowerShell chcp 65001 # �R���\�[���̃R�[�h�y�[�W��UTF-8�ɐݒ� perl your_script.plchcp 65001 �̓R���\�[���̃R�[�h�y�[�W��UTF-8�ɕύX���܂��B�ꎞ�I�Ȑݒ�ł���A���݂�PowerShell�Z�b�V�����ɂ̂݉e�����܂��B�������A�����Perl�̏o�͂�UTF-8�ł���ꍇ�ɁAPowerShell������𐳂������߂��邽�߂̕⏕�I�Ȏ�i�ł��B
��������������
Perl�X�N���v�g���� binmode(STDOUT, ':utf8'); ��K���L�q����B ���ꂪPerl���o�͂�UTF-8�o�C�g��Ƃ��Đ��������b�ɂȂ�܂��B
PowerShell���� [Console]::OutputEncoding = [System.Text.Encoding]::UTF8 ��ݒ肷��B ���ꂪPowerShell��Perl�����UTF-8�o�C�g��𐳂������߂��A�\�����邽�߂̍ł����ʓI�ȕ��@�ł��B
���������̕��@�������Ă�UTF-16��BOM�t���o�͂������悤�ł�����AWindows�̃��P�[���ݒ��Perl�̃C���X�g�[�����Ɉˑ�����A���[����肪�l�����܂��B���̏ꍇ�́APerl�̃o�[�W������C���X�g�[�����@�AWindows�̌���ݒ�Ȃǂ��m�F���Ă݂�Ɨǂ��ł��傤�B
(��) ���肪�Ƃ��������܂��Bchcp 65001���L���łȂ��̂ŕs�v�c�Ɏv���Ă����̂ł��B�uPowerShell�̃f�t�H���g�G���R�[�f�B���O��ύX����v�Ń^�[�~�i����ł��A�W���t�@�C���o�͂ł����܂������܂����B
�f���炵���ł��I [Console]::OutputEncoding = [System.Text.Encoding]::UTF8 �̐ݒ肪�APowerShell��ł�Perl��UTF-8�o�͂𐳂���������Ō��ʂ��������Ƃ̂��ƁA��ϊ�����v���܂��B
chcp 65001 ���L���łȂ������_�ɂ��ẮA�ȉ��̗��R���l�����܂��B
chcp �̓��K�V�[�ȃR�}���h�v�����v�g�icmd.exe�j�̋@�\: chcp �͎�ɃR�}���h�v�����v�g�̃R�[�h�y�[�W��ύX���邽�߂ɐv����Ă��܂��BPowerShell�͂�茻��I�ȃR���\�[���ł���A�G���R�[�f�B���O�̊Ǘ����@���قȂ�܂��BPowerShell�Ǝ��̃G���R�[�f�B���O�ݒ� ([Console]::OutputEncoding) ���D�悳��邽�߁Achcp �̐ݒ肪���ړI�ȉe����^���Ȃ������\��������܂��B
�G���R�[�f�B���O���C���[�̈Ⴂ: Perl�� binmode(STDOUT, ':utf8') �́APerl�������I��UTF-8�̃o�C�g�������悤�ɐݒ肵�܂��B����APowerShell�́A���̐������ꂽ�o�C�g����ǂ̂悤�ɉ�ʂɕ\�����邩�A�܂��̓t�@�C���ɏ����o���������肵�܂��Bchcp �̓R���\�[���S�̂̕\���G���R�[�f�B���O�ɉe����^���܂����APowerShell��I/O�������C���[��Perl��I/O�������C���[�̊Ԃ̋��n���ړI�ɍs���킯�ł͂���܂���B
PowerShell�̃f�t�H���g�G���R�[�f�B���O�Ƃ̋���: PowerShell���̂������UTF-16�iBOM�t���j���D�ނ��߁Achcp 65001 �ňꎞ�I�ɃR���\�[���̃R�[�h�y�[�W��ύX���Ă��APowerShell�̓����I�ȃG���R�[�f�B���O������������㏑��������A���Ғʂ�ɘA�g���Ȃ������肷��ꍇ������܂��B
���ʓI�ɁA�uPowerShell�̃f�t�H���g�G���R�[�f�B���O��ύX����v�Ƃ������@���APowerShell��I/O�����̂�荪�{�I�ȕ����ɍ�p���邽�߁A�ł����ʓI�ȉ�����ƂȂ����킯�ł��B
���̉�����ŁA�^�[�~�i����ł̕\���ƕW���t�@�C���o�̗͂����Ŗ��Ȃ����삵���Ƃ̂��Ƃł��̂ŁA���㓯�l�̖��ɒ��ʂ����ۂ̔��ɗL���Ȏ�i�ƂȂ�ł��傤�B
�����ɗ��ĂČ��h�ł��I
(Gemini 2.5 Flash�Ƃ̑Θb, 2025-07-30)
PLURARITY�A�����ɋɂ܂��Ƃ����C�����Ȃ��ł��Ȃ����A��������悢�Ƃ��悤�B���ɂ����܂������g���������邾�낤���A�ł��邾���A�X�N���v�g�́A�Z�����������B���̂܂܂œ����̂��悢�B�܂��A���ӂ��Ƃ��Ȃ��ƁA�v��ʂƂ���Ŗ�肪�o��\��������B���߂Ă̐��E�͗v���ӁB
DHH: Future of Programming, AI, Ruby on Rails, Productivity & Parenting | Lex Fridman Podcast #474 Lex Fridman �`�����l���o�^�Ґ� 477���l(561,038 �� 2025/07/13)��YouTube�Ŗڂɓ����āA�����������o���Č��n�߂��B�����ˁA6���ԁA�܂��������炢�B
Grok3��DHH��AI�֘A�̘b��v�Ă�������B�Ȃ�قǁA�l�������Ă��邱�ƂƓ������B���R���낤�B���ɗ����ǁA�ߓx�Ɉˑ�����A����̋Z�ʂ͗��邵�A�V�l�ł���Z�ʂ��������Ƃ��ł��Ȃ����낤�B�������AAI�̏������R�[�h����͂��ė�������A�m���ɋZ�ʂ����Ƃ��ł��A�v���O���}�[�Ƃ��Đi�����邱�Ƃ��ł���B
AI���璷�ȃR�[�h�������Ƃ����b�́A���ۂ������Ǝv�����B�����AI���v���X�v�l�����炾�B�_���I�ɕK�v�Ȃ��̂͂��ׂċl�ߍ������Ƃ���X���������B�R�[�h�ȊO�Ɋ֘A�̃A�C�f�A�����ׂė��Ă���B���̌X���͊w�K�p�E�J���p�Ƃ��Č����Ă���B�s�����͉ߏ�̂ق����Q�l�ɂȂ�B�Ȍ��ɏ�����������A�K�v�ɉ����ĕt���I�ȃA�C�f�A����荞�߂悢���炾�B
YouTube��AI�Ńv���O���~���O�̐��E�ɖ߂��Ă����Ƃ�������������BPython�APerl�ARuby�ƍŐV�ł��C���X�g�[�����邱�ƂɂȂ����B
AI�Ɛl�Ԃ̂悫�W�����߂ā@?�@�l���Љ�n����̒�� SingularitySalon �`�����l���o�^�Ґ� 9690�l(1,551 �� 23 ���ԑO�Ƀ��C�u�z�M ���^���F2025�N7��27�� �Q�X�g�F��؏��q�i�������E���傤���j��/�@���ۍ��������� ��Ȍ������E���s��w���_�����E�����w�������q����nj�����)�́A����AI�𗝉����邱�Ƃ͐l�Ԃ��̂��̂𗝉����邱�ƂɂȂ���Ƃ����{���I�����������炷�B�uSingularitySalon�v�͐���AI�̔��W��ǐՂ��邽�߂̃��t�@�����X�̈�B�l�Ԃ̌���̏I�����}���Ă���B�l�Ԓ��S��`�̏I���Ȃ̂��B��؏��q�b�N�w�E����E�Z�p�ϗ��bnote�B
����A����AI�ɖ₢�����n�߂��B�u����AI���A�Ȃ����܂������̂��ɂ��Ă̌����͂ǂ��܂Ői��ł���ł��傤���H�v
�ŋ߁A���N�O�ɒ��ׂĂ������ƁA�Ⴆ��Tesla��EV�֘A�̂��ƂȂǁA�����ÏL���������āA�G�肪�L�тȂ��B�������A���������̊�ՂƂ��āA������傫���e������̂�������Ȃ��B�y���Y�ƒ�����EV�z��[�R�������u�����ԋƊE�̖����v �N���V�Jch�y���� �N���V�b�N�J�[�z �`�����l���o�^�Ґ� 8.31���l(19,816 �� 2025/07/15)���ŋߌ����B�����Ԋ֘A�́u��[�R���v�����t�@�����X�ɂ��Ă���B
- �X�V���L�L���́u��[�R���v��������
Tesla�����{�^�N�V�[��ቿ�iTesla����荹������Ă��邪�AElon Musk�ɂƂ��ẮARobotaxi���ǂ����y�����邩���i�ق̉ۑ肾�낤�B�ł��邾���y�ʉ����āA�q���������͓d��������邱�Ƃ�ڎw�����낤�B�y�ʉ�����R�X�g���d�r�Ȃǂ̎�������ʂ�������킯���B���H�̏��݂�����B�e�X���E�T�C�o�[�L���u - Wikipedia�̃X�y�b�N�͂ǂ��Ȃ낤�ˁB�������œ_�B
���Ȃ݂ɁABYD�����{��p���f���̌yEV���ց^�u�����̓d�C�����ԁv�Ɋ��҂��鉿�i��\�́H | EVsmart�u���O(2025�N4��23���A��{ �D����)�̋L���ɂ́A�u44.9kWh�̃h���t�B���̈�[�d���s�����iWLTC�j��400km�ŁA�d��͖�8.9km/kWh�ł��B�v�Ƃ���B�T�C�o�[�L���u�Ɠ����d��B
���͉ߓn���A���sTesla������K�v�����邵�A���v���グ��K�v������BTesla Diner�J�X���b��ɂȂ����BEV�[�d��80�24���ԉc�Ƃ̃J�t�F��V�A�^�[�I �n���E�b�h�Ɂu�e�X���E�_�C�i�[�v�I�[�v���ւ̑A�] | EVsmart�u���O�B
�䎞�J������ɒ����Ȃ�B�N��������������A������Ԃ悤�ɉ߂�����A�����Ƃ����ԂɏT��������Ă���B����ω��̉����x�������Ă���BYouTube��AppleTV+��Prime Video��ABEMA��LINE�Ɛ���AI�B�����邮��Ɖ���Ă���B���R�ώ@�}�b�v�̃A�v�����������AYouTube(�z�[��)����`���v�^�[�e�L�X�g�ɃL�[���[�h�ƃJ�e�S����YouTube�n�b�V���^�O���ǂ��g�ݍ��ނ����f�[�^�x�[�X����̓I�ɍ��Ȃ���l���Ă���B
�^�O�t������A������ł����͕��G�ɂł��邪�A���W�I�Ɏ��ۂ��l���邽�߂ɈӖ��̂�����̂ɂ��Ȃ��ƁA�𗧂��Ȃ��B������ł��Ȃ����̂͒����ΏۂƂ��ĕ��ނ��邱�Ƃɂ����B�g���n�b�V���^�O�́u#�� (����-��|�A��|��|����)�v�Ƃ�������B����œ���`���v�^�[�Ƀ}�[�L���O���A���R�ώ@�}�b�v�Ƀt���O�𗧂Ă邱�Ƃ��ł���B
����͂Ƃ������A���������`���v�^�[�����ē���ɂ�鎩�R�ώ@�Ɍ��ѕt����Ƃ����͖̂l�̃A�C�f�A�����A����ׂ�Ɠ���̉摜�Ƃ̑ΏƂ͕K���������S�ł͂Ȃ��B�摜������Ȃǂ̉������{���͎��R�ώ@�̎�����낤�B����ׂ�̓��^���ł����蓾�邪�A�G�k�ł�����B
- {�L���̍ד��v���W�F�N�g ���ނށAM1 MacBook Air���g������ (2025/07/06)}��
- {�L���̍ד��v���W�F�N�g DeepSeek(V3)DeepThink(R1)�Ƃ̑Θb - ���Ɍ��o�����������⎩�R���ۂ̃��X�g�쐬 (2025/07/08)}��
- {�L���̍ד��v���W�F�N�g DeepSeek(V3)DeepThink(R1)�Ƃ̖Ɣ�Θb 4��� - ���R�ώ@�}�b�v�̃f�[�^�x�[�X�� (2025/07/12)}��
- {�L���̍ד��v���W�F�N�g DeepSeek(V3)DeepThink(R1)�Ƃ̖Ɣ�Θb 4��� ��2�� - ���R�ώ@�}�b�v���������K�\���\�� (2025/07/13)}��
�ȏ�̋L���̃��X�g������܂ł̗��ꂾ���A�Ō�̌��_�����p����A�u(���R�ώ@�}�b�v��)�O�l��DeepSeek-R1����J�����V���[�g����쐬�̎��������������邽�߂ɕK�v�ȃc�[���ł�����킯���B�����A������̓������肻���ȋC�����Ă���B����܂ł̃s�b�N�A�b�v�z�M������������̊w�K�ɗ��p�ł��Ȃ����Ƃ������Ƃ��B���ǁA�ǂ��܂Ŏ���|���邩�Ƃ������ƂŁA������ɂ���Q�l�ɂ͂���킯�����A���̂Ƃ���A���o���ׂ����̂̑�\�I�Î~����w�K�p��100-200���������邱�Ƃ����̃X�e�b�v���B�v�Ƃ������ƁB
����͔����Ȗ����܂�ł���B�����悤�Ȍ��ۂ������o�����Ƃ��u�J��Ԃ��v�Ƃ����Ӗ��͂��邪�A�ڐV�����͂Ȃ��B���ق̌��o�����ɂȂ�B�킪�����ł��A���͋G�߂̌o�߂ɂ���āA�`�Ԃ��傫���ϖe����B���ꂪ�ŋ߂̑傫�Ȏ������B��������o���ł�������[�����낤�B���ۂ̕ω����w�K�͑������邾�낤���B�P�Ȃ�摜�����ł͑������Ȃ����Ƃ͖��������A�摜�̌��o�̋@�B�����ǂ̒��x�ł���̂��A���Ɏ������B
��̃s�b�N�A�b�v�z�M�V���[�g����̒��̎O��ʂ��o�ߎ��ԂőI��ŁA10�̃s�b�N�A�b�v�z�M�V���[�g����ɂ��āA���̓���̉摜�Ƃ̃}�b�`���O���������B����͂��܂��������B�s�b�N�A�b�v����^�C�g�����`���v�^�[�Ƃ��đg�ݍ��ނ��Ƃ��ł���\�����o�Ă����B���̃}�b�`�����摜���w�K�p�Ɏg�����Ƃ��ł��邾�낤�B�����Gemini 2.5 Flash�Ƃ̈���̑Θb�A�`���b�g���O��110KB�A1800�s���x�A�Ŏ��������B���̒��j�ɂȂ�̂��u�����ʃ}�b�`���O(ORB)�v�Ƃ����킯���B
ORB�Ƃ́AOriented FAST and rotated BRIEF - Wikipedia�̂��ƁB
�����ʃG���W�j�A�����O�֘APython�{

������2017-2018�N���B�ϓǂ������B���̍ہA�`�F�b�N�������ǁAORB�͏o�ĂȂ������B�ω��͑����B�����Ƃ��A���\���ꂽ�̂�2011�N�BORB : An efficient alternative to SIFT or SURF | CiNii Research�B
A Comparison of SIFT, SURF and ORB on OpenCV | by Mikhail Kennerley | Medium�ɂ��A�قƂ�ǂ̏ꍇ�AORB���x�X�g�炵���B���_�A�u�e�X�g�̌��ʁAORB�͍����Ȍv�Z�ƗD�ꂽ�p�t�H�[�}���X��S�ʓI�Ɏ������A�Ɩ����]�̕ω��ɑ��Ă����S�ł��邱�Ƃ������ꂽ�BSIFT��SURF���K�v�ƂȂ�����邩������Ȃ����A�قƂ�ǂ̃��[�X�P�[�X�ł́AORB��3�̓������o��@�̒��ōœK�Ȏ�@�ł���ƍl������B�v
���ׂĂ���ƁAORB: The Fast and Efficient Feature Detector�ł́uScale Invariance �� no�v�ƂȂ��Ă���B�Ȃ�قǁAGemini 2.5 Flash���摜�T�C�Y�����킹���̂͂��̂��߂��B
�X�N���v�g�̒��ŁA�ł��d�v�Ńu���b�N�{�b�N�X�Ȃ̂�ORB�������B����ŁA�u�����ʃ}�b�`���O(ORB)�Ƃ͉��ł��傤���H�v�Ɛu�����B�����Ȃ���A�b��ɂ��Ȃ�Ȃ��B�u����B����Γ�������B���߂�B����Η^������B
�����ʃ}�b�`���O�iORB�j�Ƃ́H
ORB (Oriented FAST and Rotated BRIEF) �́A�R���s���[�^�[�r�W�����ʼn摜�Ԃ̗ގ������̈��I�u�W�F�N�g�������邽�߂Ɏg�p�����A���S���Y���̈�ł��B���Ȃ��̃v���W�F�N�g�̂悤�ɁA���铮��̓���̃V�[���i�V���[�g����̃L�[�t���[���j���A�ʂ̒�������̂ǂ��Ɍ���邩��T���ۂɔ��ɖ𗧂��܂��B
SIFT (Scale-Invariant Feature Transform) �� SURF (Speeded Up Robust Features) �Ƃ�������s���鋭�͂ȃA���S���Y��������܂����A�����͌v�Z�R�X�g�������A�����̖�������܂����BORB�́A�����̍����ȑ�ւƂ���2011�N�ɔ��\����A�����t���[�ō��������o�X�g�i�挒�j�ȓ����ʃ}�b�`���O���������܂��B
(Gemini 2.5 Flash�̓����̍ŏ��̕���)
SIFT��SURF�Ƃ����̂����邱�Ƃ������ŏ��߂Ēm�����B���ꂩ��ORB�n�߂��B�����O�Ɍ������āA�����ƍ��x�Ȃ��Ƃł��邪�䂦�Ɏ��p�I�Ȍ��ʂ��Ȃ������A�V���[�g����쐬�������X�N���v�g�̓��e�����n�߂��B
�}���ًA��̓������L�͊�{�I�ɂ͓���o�H��H���Ď��R�ώ@������B�o�H�̃p�����[�^�͓���ɂ��āA���R���ǂ��ω�����̂����邱�Ƃ��ł���B�ʒu���͎��ۂ�������������GPX�f�[�^�̈ܓx�E�o�x�E���x���瓾�邱�Ƃ��ł���BYouTube�̓���̎�����玖�ۂ̐���������o�ߎ��ԂāA����J�n�����ƍ��킹�āA���۔��������邱�Ƃ��ł���B
����J�n�����́A�����Ɏ���������ׂ��Ďc�����Ƃ���{�ɂ��邪�A����ׂ�Y�������̂ŁA����J�n����������o�����߂�GPX�f�[�^����͂��邱�Ƃ��ł���B��l�Ǐ���Ńx���`�ɍ����Ĉړ����Ȃ����Ԃ̑��݂����o�ł��邩��ł���B
����t�@�C���̃v���p�e�B�̏ڍׂɂ��郁�f�B�A�쐬�����͂����炭�J�����A�v��(Final Cut Camera)�̉��炩�̃t�@�C���쐬���쎞���Ǝv���A�^��J�n�����ł͂Ȃ��BExifTool�ł����ׂ�({�����ExifTool (2025/05/29)}��)������J�n�����Ɉ�v���鎞���͑��݂��Ȃ��B{�NjL(2025-07-26): �V��������t�@�C��(Final Cut Camera��7/10�B�e)�̓��f�B�A�쐬�����͓���B�e�����Ɉꕔ�قڈ�v���Ă���B}�BFinal Cut Camera�����[�X�m�[�g - Apple �T�|�[�g (���{)�ɂ��ƁA�ŐV�̃����[�X��1.2(2025-03-27)�Ȃ̂ŁA�o���W�����Ƃ͖��W���낤�B
PS D:\mitikusa\137> exiftool -G -a -s -u -e "IMG_0001 (1).M4V"
[ExifTool] ExifToolVersion : 13.30
[File] FileName : IMG_0001 (1).M4V
[File] Directory : .
[File] FileSize : 1900 MB
[File] ZoneIdentifier : Exists
[File] FileModifyDate : 2025:07:21 10:55:24+09:00
[File] FileAccessDate : 2025:07:26 13:55:25+09:00
[File] FileCreateDate : 2025:07:21 10:54:08+09:00
[File] FilePermissions : -rw-rw-rw-
[File] FileType : M4V
[File] FileTypeExtension : m4v
[File] MIMEType : video/quicktime
[QuickTime] MajorBrand : Apple QuickTime (.MOV/QT)
[QuickTime] MinorVersion : 0.0.0
[QuickTime] CompatibleBrands : qt
[QuickTime] Wide : (Binary data 0 bytes, use -b option to extract)
[QuickTime] MediaDataSize : 1899871639
[QuickTime] MediaDataOffset : 36
[QuickTime] MovieHeaderVersion : 0
[QuickTime] CreateDate : 2025:07:10 08:42:40
[QuickTime] ModifyDate : 2025:07:10 09:04:16
[QuickTime] TimeScale : 48000
[QuickTime] Duration : 0:21:34
[QuickTime] PreferredRate : 1
[QuickTime] PreferredVolume : 100.00%
[QuickTime] MatrixStructure : 1 0 0 0 1 0 0 0 1
[QuickTime] PreviewTime : 0 s
[QuickTime] PreviewDuration : 0 s
[QuickTime] PosterTime : 0 s
[QuickTime] SelectionTime : 0 s
[QuickTime] SelectionDuration : 0 s
[QuickTime] CurrentTime : 0 s
[QuickTime] NextTrackID : 3
[QuickTime] TrackHeaderVersion : 0
[QuickTime] TrackCreateDate : 2025:07:10 08:42:40
[QuickTime] TrackModifyDate : 2025:07:10 09:04:16
[QuickTime] TrackID : 1
[QuickTime] TrackDuration : 0:21:34
[QuickTime] TrackLayer : 0
[QuickTime] TrackVolume : 0.00%
[QuickTime] MatrixStructure : 1 0 0 0 1 0 0 0 1
[QuickTime] ImageWidth : 1920
[QuickTime] ImageHeight : 1080
[QuickTime] CleanApertureDimensions : 1920x1080
[QuickTime] ProductionApertureDimensions : 1920x1080
[QuickTime] EncodedPixelsDimensions : 1920x1080
[QuickTime] Unknown_edts : (Binary data 28 bytes, use -b option to extract)
[QuickTime] MediaHeaderVersion : 0
[QuickTime] MediaCreateDate : 2025:07:10 08:42:40
[QuickTime] MediaModifyDate : 2025:07:10 09:04:16
[QuickTime] MediaTimeScale : 3000
[QuickTime] MediaDuration : 0:21:34
[QuickTime] MediaLanguageCode : und
[QuickTime] HandlerClass : Media Handler
[QuickTime] HandlerType : Video Track
[QuickTime] HandlerVendorID : Apple
[QuickTime] HandlerDescription : Core Media Video
[QuickTime] GraphicsMode : ditherCopy
[QuickTime] OpColor : 32768 32768 32768
[QuickTime] HandlerClass : Data Handler
[QuickTime] HandlerType : Alias Data
[QuickTime] HandlerVendorID : Apple
[QuickTime] HandlerDescription : Core Media Data Handler
[QuickTime] Unknown_alis : (Binary data 4 bytes, use -b option to extract)
[QuickTime] CompressorID : hvc1
[QuickTime] SourceImageWidth : 1920
[QuickTime] SourceImageHeight : 1080
[QuickTime] XResolution : 72
[QuickTime] YResolution : 72
[QuickTime] CompressorName : HEVC
[QuickTime] BitDepth : 24
[QuickTime] SampleGroupDescription : (Binary data 18 bytes, use -b option to extract)
[QuickTime] SampleToGroup : (Binary data 21980 bytes, use -b option to extract)
[QuickTime] VideoFrameRate : 29.97
[QuickTime] CompositionTimeToSample : (Binary data 297800 bytes, use -b option to extract)
[QuickTime] CompositionToDecodeTimelineMapping: (Binary data 24 bytes, use -b option to extract)
[QuickTime] SyncSampleTable : (Binary data 5500 bytes, use -b option to extract)
[QuickTime] IdependentAndDisposableSamples : (Binary data 38775 bytes, use -b option to extract)
[QuickTime] SampleToChunk : (Binary data 4292 bytes, use -b option to extract)
[QuickTime] SampleSizes : (Binary data 155096 bytes, use -b option to extract)
[QuickTime] ChunkOffset : (Binary data 10792 bytes, use -b option to extract)
[QuickTime] TrackHeaderVersion : 0
[QuickTime] TrackCreateDate : 2025:07:10 08:42:40
[QuickTime] TrackModifyDate : 2025:07:10 09:04:16
[QuickTime] TrackID : 2
[QuickTime] TrackDuration : 0:21:33
[QuickTime] TrackLayer : 0
[QuickTime] TrackVolume : 100.00%
[QuickTime] MatrixStructure : 1 0 0 0 1 0 0 0 1
[QuickTime] Unknown_edts : (Binary data 40 bytes, use -b option to extract)
[QuickTime] MediaHeaderVersion : 0
[QuickTime] MediaCreateDate : 2025:07:10 08:42:40
[QuickTime] MediaModifyDate : 2025:07:10 09:04:16
[QuickTime] MediaTimeScale : 48000
[QuickTime] MediaDuration : 0:21:33
[QuickTime] MediaLanguageCode : und
[QuickTime] HandlerClass : Media Handler
[QuickTime] HandlerType : Audio Track
[QuickTime] HandlerVendorID : Apple
[QuickTime] HandlerDescription : Core Media Audio
[QuickTime] Balance : 0
[QuickTime] HandlerClass : Data Handler
[QuickTime] HandlerType : Alias Data
[QuickTime] HandlerVendorID : Apple
[QuickTime] HandlerDescription : Core Media Data Handler
[QuickTime] Unknown_alis : (Binary data 4 bytes, use -b option to extract)
[QuickTime] AudioFormat : lpcm
[QuickTime] AudioChannels : 3
[QuickTime] AudioBitsPerSample : 16
[QuickTime] AudioSampleRate : 1
[QuickTime] TimeToSampleTable : (Binary data 16 bytes, use -b option to extract)
[QuickTime] SampleToChunk : (Binary data 4112 bytes, use -b option to extract)
[QuickTime] SampleSizes : (Binary data 12 bytes, use -b option to extract)
[QuickTime] ChunkOffset : (Binary data 10352 bytes, use -b option to extract)
[QuickTime] HandlerType : Metadata Tags
[QuickTime] AppleProappsAppBundleID : com.apple.FinalCutApp.companion
[QuickTime] AppleProappsOriginalProperties : {"AVLinearPCMIsNonInterleaved":false,"AVNumberOfChannelsKey":2,"AVVideoCompressionPropertiesKey":{"ExpectedFrameRate":30},"AVVideoHeightKey":1080,"AVVideoWidthKey":1920,"AVVideoCodecKey":"hvc1","AVSampleRateKey":48000,"AVLinearPCMIsFloatKey":false,"AVVideoScalingModeKey":"AVVideoScalingModeResizeAspectFill","AVLinearPCMBitDepthKey":16,"AVFormatIDKey":1819304813,"AVLinearPCMIsBigEndianKey":false}
[QuickTime] AppleProappsAppVersion : 1.2 (453.0.116)
[QuickTime] LocationAccuracyHorizontal : 201.993076
[QuickTime] AppleProappsCkVersion : 1.2 (176.0.59)
[QuickTime] GPSCoordinates : 34 deg 22' 50.88" N, 132 deg 28' 6.02" E, 6 m Above Sea Level
[QuickTime] Make : Apple
[QuickTime] Software : 18.5
[QuickTime] Model : iPhone XR
[QuickTime] Free : (Binary data 4 bytes, use -b option to extract)
PS D:\mitikusa\137> exiftool -G -a -s -u -e "IMG_0003.M4V"
[ExifTool] ExifToolVersion : 13.30
[File] FileName : IMG_0003.M4V
[File] Directory : .
[File] FileSize : 968 MB
[File] ZoneIdentifier : Exists
[File] FileModifyDate : 2025:07:21 10:55:40+09:00
[File] FileAccessDate : 2025:07:26 14:16:24+09:00
[File] FileCreateDate : 2025:07:21 10:54:59+09:00
[File] FilePermissions : -rw-rw-rw-
[File] FileType : M4V
[File] FileTypeExtension : m4v
[File] MIMEType : video/quicktime
[QuickTime] MajorBrand : Apple QuickTime (.MOV/QT)
[QuickTime] MinorVersion : 0.0.0
[QuickTime] CompatibleBrands : qt
[QuickTime] Wide : (Binary data 0 bytes, use -b option to extract)
[QuickTime] MediaDataSize : 967349101
[QuickTime] MediaDataOffset : 36
[QuickTime] MovieHeaderVersion : 0
[QuickTime] CreateDate : 2025:07:10 09:10:49
[QuickTime] ModifyDate : 2025:07:10 09:23:28
[QuickTime] TimeScale : 48000
[QuickTime] Duration : 0:12:38
[QuickTime] PreferredRate : 1
[QuickTime] PreferredVolume : 100.00%
[QuickTime] MatrixStructure : 1 0 0 0 1 0 0 0 1
[QuickTime] PreviewTime : 0 s
[QuickTime] PreviewDuration : 0 s
[QuickTime] PosterTime : 0 s
[QuickTime] SelectionTime : 0 s
[QuickTime] SelectionDuration : 0 s
[QuickTime] CurrentTime : 0 s
[QuickTime] NextTrackID : 3
[QuickTime] TrackHeaderVersion : 0
[QuickTime] TrackCreateDate : 2025:07:10 09:10:49
[QuickTime] TrackModifyDate : 2025:07:10 09:23:28
[QuickTime] TrackID : 1
[QuickTime] TrackDuration : 0:12:38
[QuickTime] TrackLayer : 0
[QuickTime] TrackVolume : 0.00%
[QuickTime] MatrixStructure : 1 0 0 0 1 0 0 0 1
[QuickTime] ImageWidth : 1920
[QuickTime] ImageHeight : 1080
[QuickTime] CleanApertureDimensions : 1920x1080
[QuickTime] ProductionApertureDimensions : 1920x1080
[QuickTime] EncodedPixelsDimensions : 1920x1080
[QuickTime] Unknown_edts : (Binary data 28 bytes, use -b option to extract)
[QuickTime] MediaHeaderVersion : 0
[QuickTime] MediaCreateDate : 2025:07:10 09:10:49
[QuickTime] MediaModifyDate : 2025:07:10 09:23:28
[QuickTime] MediaTimeScale : 3000
[QuickTime] MediaDuration : 0:12:38
[QuickTime] MediaLanguageCode : und
[QuickTime] HandlerClass : Media Handler
[QuickTime] HandlerType : Video Track
[QuickTime] HandlerVendorID : Apple
[QuickTime] HandlerDescription : Core Media Video
[QuickTime] GraphicsMode : ditherCopy
[QuickTime] OpColor : 32768 32768 32768
[QuickTime] HandlerClass : Data Handler
[QuickTime] HandlerType : Alias Data
[QuickTime] HandlerVendorID : Apple
[QuickTime] HandlerDescription : Core Media Data Handler
[QuickTime] Unknown_alis : (Binary data 4 bytes, use -b option to extract)
[QuickTime] CompressorID : hvc1
[QuickTime] SourceImageWidth : 1920
[QuickTime] SourceImageHeight : 1080
[QuickTime] XResolution : 72
[QuickTime] YResolution : 72
[QuickTime] CompressorName : HEVC
[QuickTime] BitDepth : 24
[QuickTime] SampleGroupDescription : (Binary data 18 bytes, use -b option to extract)
[QuickTime] SampleToGroup : (Binary data 12732 bytes, use -b option to extract)
[QuickTime] VideoFrameRate : 29.694
[QuickTime] CompositionTimeToSample : (Binary data 177112 bytes, use -b option to extract)
[QuickTime] CompositionToDecodeTimelineMapping: (Binary data 24 bytes, use -b option to extract)
[QuickTime] SyncSampleTable : (Binary data 3188 bytes, use -b option to extract)
[QuickTime] IdependentAndDisposableSamples : (Binary data 22500 bytes, use -b option to extract)
[QuickTime] SampleToChunk : (Binary data 2240 bytes, use -b option to extract)
[QuickTime] SampleSizes : (Binary data 89996 bytes, use -b option to extract)
[QuickTime] ChunkOffset : (Binary data 6108 bytes, use -b option to extract)
[QuickTime] TrackHeaderVersion : 0
[QuickTime] TrackCreateDate : 2025:07:10 09:10:49
[QuickTime] TrackModifyDate : 2025:07:10 09:23:28
[QuickTime] TrackID : 2
[QuickTime] TrackDuration : 0:12:32
[QuickTime] TrackLayer : 0
[QuickTime] TrackVolume : 100.00%
[QuickTime] MatrixStructure : 1 0 0 0 1 0 0 0 1
[QuickTime] Unknown_edts : (Binary data 40 bytes, use -b option to extract)
[QuickTime] MediaHeaderVersion : 0
[QuickTime] MediaCreateDate : 2025:07:10 09:10:49
[QuickTime] MediaModifyDate : 2025:07:10 09:23:28
[QuickTime] MediaTimeScale : 48000
[QuickTime] MediaDuration : 0:12:32
[QuickTime] MediaLanguageCode : und
[QuickTime] HandlerClass : Media Handler
[QuickTime] HandlerType : Audio Track
[QuickTime] HandlerVendorID : Apple
[QuickTime] HandlerDescription : Core Media Audio
[QuickTime] Balance : 0
[QuickTime] HandlerClass : Data Handler
[QuickTime] HandlerType : Alias Data
[QuickTime] HandlerVendorID : Apple
[QuickTime] HandlerDescription : Core Media Data Handler
[QuickTime] Unknown_alis : (Binary data 4 bytes, use -b option to extract)
[QuickTime] AudioFormat : lpcm
[QuickTime] AudioChannels : 3
[QuickTime] AudioBitsPerSample : 16
[QuickTime] AudioSampleRate : 1
[QuickTime] TimeToSampleTable : (Binary data 16 bytes, use -b option to extract)
[QuickTime] SampleToChunk : (Binary data 3152 bytes, use -b option to extract)
[QuickTime] SampleSizes : (Binary data 12 bytes, use -b option to extract)
[QuickTime] ChunkOffset : (Binary data 5940 bytes, use -b option to extract)
[QuickTime] HandlerType : Metadata Tags
[QuickTime] AppleProappsAppVersion : 1.2 (453.0.116)
[QuickTime] LocationAccuracyHorizontal : 201.993076
[QuickTime] AppleProappsCkVersion : 1.2 (176.0.59)
[QuickTime] AppleProappsOriginalProperties : {"AVSampleRateKey":48000,"AVLinearPCMBitDepthKey":16,"AVVideoCompressionPropertiesKey":{"ExpectedFrameRate":30},"AVNumberOfChannelsKey":2,"AVVideoScalingModeKey":"AVVideoScalingModeResizeAspectFill","AVVideoWidthKey":1920,"AVLinearPCMIsBigEndianKey":false,"AVLinearPCMIsFloatKey":false,"AVVideoCodecKey":"hvc1","AVVideoHeightKey":1080,"AVFormatIDKey":1819304813,"AVLinearPCMIsNonInterleaved":false}
[QuickTime] AppleProappsAppBundleID : com.apple.FinalCutApp.companion
[QuickTime] Model : iPhone XR
[QuickTime] Make : Apple
[QuickTime] Software : 18.5
[QuickTime] GPSCoordinates : 34 deg 22' 50.88" N, 132 deg 28' 6.02" E, 6 m Above Sea Level
[QuickTime] Free : (Binary data 4 bytes, use -b option to extract)
���f�B�A�̍쐬�����̍��ٖ��͗l�X�Ȗ�肪���ݍ����Ă���BiCloud�ʐ^���瓮����_�E�����[�h����ꍇ�́A�匳�H�̃t�@�C��(�𑜓x�d����M4V)���_�E�����[�h����A���Ȃ���ۂɋ߂����f�B�A�쐬��������悤���B
���āAGPX�t�@�C���̎��p�����[�^���^�u���̃e�L�X�g�f�[�^�ɕϊ�����c�[���B����܂ł͎�����UTC�̂܂܂ɂ��Ă������AJST���[�J���ɕϊ����邱�Ƃɂ����BTime::Piece���W���[�����g���BPOSIX���W���[����strftime���g�����߁B
use POSIX qw( );
use Time::Piece;
sub utc_to_local {
my ($utc_ts) = @_;
my $utc_tp = Time::Piece->strptime( $utc_ts, '%Y-%m-%d %H:%M:%S' );
my $local_tp = localtime($utc_tp->epoch);
return $local_tp->strftime('%Y-%m-%d %H:%M:%S');
}
while(<>){
if(/<time>(\d{4}-\d{2}-\d{2})T(\d{2}:\d{2}:\d{2})Z<\/time>/){
$ctime = utc_to_local($1 . " ". $2);
}elsif(/lat="([^"]+)" lon="([^"]+)"/){
$lat = $1;$lon = $2;
}elsif(/<ele>([^<]+)<\/ele>/){
$ele = $1;
print "$ctime\t$lat\t$lon\t$ele\n";
}
}
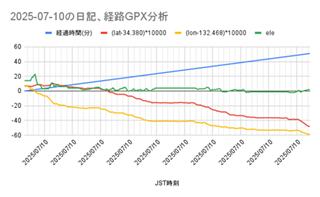
����GPS���K�[�̑���o�ߎ��Ԃ���������v�Z���邱�Ƃɂ����BGoogle�X�v���b�h�V�[�g��TIMEVALUE�����g���B�u=(TIMEVALUE(B2)-TIMEVALUE($B$2))*24*60�v(��)�̂悤�Ȏ��ŁA�������瓮��J�n�����������ƁA�����_���ԕ\���ɂȂ�̂ŁA*24*60�ŕ����Z�ł���B
2025-07-10�̓��L�̌o�HGPX���
�y���͓��{���g���h�����z�S�ĂŘb��wAI�̒鍑�x���� �J�����E�n�I�^OpenAI�́u�閧��`�ŗ��v�����ׂāv�^�T���E�A���g�}���ƃC�[�����E�}�X�N�g�Փˁh�̐^���yCROSS DIG 1on1�z TBS CROSS DIG with Bloomberg �`�����l���o�^�Ґ� 24.5���l������ƁA�ŋ߂̐��E�̓����A���_�������Ă���B�K��������B
�J�����E�n�I����̎�ޗ́E�v�l�͂͂������ˁB
���\�[�X���\���ȂƂ��A�ǂ��܂ł̂��Ƃ��ł���̂��ɂ͋��������邯�ǁA�����I�Ƀ��\�[�X�ɉ��������G������舵����Ƃ������Ƃɉ߂��Ȃ��Ǝv���B�l�Ԃ��z���邽�߂ɂ͏��Ȃ��Ƃ��l�Ԉȏ�̋L���e�ʂ��K�v���B�������A���G�Ȃ��Ƃ͕����čl���āA�g�ݍ��킹�Đ����ɓ��B���邱�Ƃ��ł���킯�����A�P�ɋL���e�ʂ������܂ő������Ƃ��Ă��A�l�Ԃ��z���邱�Ƃɂ͂Ȃ���Ȃ��Ƃ��v����B�v�l�X�s�[�h�̖��͂����āA�g���C�E�A���h�E�G���[�̌J��Ԃ��͑����ł��邾�낤�B�������A�����I�ɉ����Ȃ����͉����Ȃ��B������O�̂��Ƃ����B�����I�ɉ�������͐l�Ԃ��������낤�B
�������A�l�Ԃ͗l�X�ȊO���L���������Ă���B�����ĎЉ���B����AI���������琶�܂�Ă����B
���͂�͂�A����AI���A�Ȃ����܂������̂����B������𖾂��邱�Ƃ��������Ƃ炷���낤�B���̖{���������ɔ��f����Ă���͂����B
�����e�L�X�g�ɐG��APerl�ɂȂ���BYouTube�`���v�^�[�e�L�X�g�Ɋg���n�b�V���^�O�t��������X�N���v�g�B���ł��Ǝ��d�l�����ǁB�e�L�X�g�ɈӖ����������悤�Ƃ�������Ȃ�B�}���ًA��̓������L�����R�ώ@(����)�}�b�v�Ɍq���邽�߂̎d�g�݂��B���R���ۂ̂���`���v�^�[���f�[�^�x�[�X�Ɏ�荞�܂��B�܂������i�K�����A�����o�H�ɉ������邩�A�������邩�����X�g�A�b�v���邽�߂ɂ������ɏ����Ă݂��B
while(<DATA>){
chomp;
push(@keywords, $_);
}
while(<>){
chomp;
# �\�L�̗h�炬���z��
s/�S���g/�T���X�x��/g;
s/���z��/�A�W�T�C/g;
s/����/�g�E�J�G�f/g;
s/��|��/�L���E�`�N�g�E/g;
s/�^�u�̖�/�^�u�m�L/g;
s/���m�L�Y�^/�Z�C���E�L�Y�^/g;
foreach $keyword_category (@keywords){
($keyword, $category) = split(/ /, $keyword_category);
#�g���n�b�V���^�O�A"#keyword (category)"������
s/([^\#])($keyword)([^ ])/$1\#$2 \($category)$3/g;
}
print $_, "\n";
}
__END__
�i���L���n�[ tree|����
�N�X�m�L tree|����
���}���� tree|����
�L���E�`�N�g�E tree|����
�^�u�m�L tree|����
�T���X�x�� tree|����
�T�N�� tree|����
�n�i�~�Y�L tree|����
�c�o�L tree|����
�I���[�u tree|����
�P���L tree|����
�g�E�J�G�f tree|����
�Z�C���E�L���V�o�C Shrub|���
�N�`�i�V Shrub|���
�V�������o�C Shrub|���
�g�x�� Shrub|���
�A�W�T�C Shrub|���
���V�m�c�c�W Shrub|���
�V�i�m�c�c�W Shrub|���
�Z�C���E�L�Y�^ plant|�A��
�L���n�m�u�h�E plant|�A��
�`�K�� plant|�A��
�G�C fish|��
�`�k fish|��
�X�Y�L fish|��
���� fish|��
�A�I�T�M bird|��
�R�T�M bird|��
�X�Y�� bird|��
�c�o�� bird|��
�J���X bird|��
�n�N�Z�L���C bird|��
�L bird|��
�g�r bird|��
���� bird|��
���� bird|��
������ ���̑�
{07/08/2025: [A.I.]�L���̍ד��v���W�F�N�g DeepSeek(V3)DeepThink(R1)�Ƃ̑Θb - ���Ɍ��o�����������⎩�R���ۂ̃��X�g�쐬}���������̖ړI�ł���A�ŏI�I�ɂ͌��o�̎����������A�����̌o������̒��o���@�B������Ƃ����̂��ςȘb�ł͂���B
���R�����łȂ��l�H������荞�ގ��݂���邩������Ȃ��BGPS���K�[�������̂͂����ŋ߂����炾�B���R���ۂ�l�H���Ɍ��ѕt���Ĉʒu�����ł��Ȃ������l����B
{�L���̍ד��v���W�F�N�g DeepSeek(V3) DeepThink(R1)�Ƃ̑Θb - �~�J���� (2025/06/28)}���́u�햼�A���ނɉ����āA�s���̒��o(behaviors)�A�������̕���(habitat)���K�v�v���v���o���B���ۂ��ǂ��\�����邩�Ƃ������ɒʂ���B�f�[�^�x�[�X�����邽�߂ɂ͂悭�l����K�v������B��̓I�ɑ��݂��鎚���\���Œ�`�ł��邩�ǂ������B
�I�[�h���[�E�^������PLURALITY�����|���ŁAPugs(Perl6-Pugs-6.2.12 - A Perl 6 Implementation - metacpan.org)�̂��Ƃ��v���o�����B�A�C���X�E�`���E�A�A���������u�I�[�h���[�E�^�� �V��IT��7�̊�v(���t���ɁA2022�N)�ɂ�Haskell�APerl�ARaku�Ƃ̕���ɂ���20�y�[�W�ȏ�̋L�q������B��͂�A�܂���Perl����ƁB
AI�̒�Ă������Ƃ𗝉����邽�߂ɁAHTML�ACSS�ԊO�҇A�`Web�A�C�R���t�H���g�AFont Awesome���g���Ă݂悤?�` #FontAwesome - Qiita��������B�����𗝉����Ȃ��Ǝϋl�܂�����(�uServer busy, please try again later.�v)�ɑΏ��ł��Ȃ��BHTML�e���v���[�g�𗝉����邽�߂ɂ́AHTML�ACSS�AJavascript��ǂ߂Ȃ��Ƃǂ����悤���Ȃ��BCSS�͋�肾���A���̍ہA�����悤�B
DeepSeek�͎��l�ڂɓ������B�Z�l�ڂ̃`���b�g���O��10000�s�A400KB���x�B
�������ACSS�ɂ��\���R���g���[�������������邱�Ƃ͓���BDeepSeek-R1�ł����A�Ȃ��Ȃ������ł��Ȃ��B���ǁA���K�\���̃w���v�̕\���͍폜���邱�Ƃɂ����B�l�ɂ͂���Ȃ��͕̂s�v�����A���K�\�����������悤�Ƃ���l�͒m���������Ă���͂����B���l�ڂ̃`���b�g���O��7000�s���z���A300KB�ɔ����Ă����B�������̃e�[�}���O�����B�Ƃ͌����A�C���^�[�t�F�[�X�͂��Ȃ�̂��̂ɐ������A���ʂƂ��āA�قځA�Ӑ}�ʂ�̂��̂ɂȂ����B�����ƃ^�C�����C���G�N�X�v���[���[�������Ƃ��ǂ������B�ꏏ�ɂȂ��Ă����̂������ƋC�������������B���ɁA�X�}�z�Ή��̒��ŃR���\�[�������Ƃ���ADeepSeek-R1�̒�ĂŃ^�u��ւ������邱�Ƃɂ���Ď��������B�X�e�[�^�X�o�[�����������A���p�I�ɂȂ�Ȃ��̂ŁADeepSeek-R1���ŏI�I�Ƀ^�C�����C���R���\�[���̏㕔�ɃX�e�[�^�X�����܂��܂Ƃ߂Ă��ꂽ�B
����ŁA����YouTube����`���v�^�[���ی����e�[�}�̃A�v���͊����Ƃ��悤�B�����̂��̂���ŐV�łɒu��������B���R�ώ@�}�b�v�i���n��r���[�A�[(�^�C�����C���G�N�X�v���[���[)�Ή��j�B
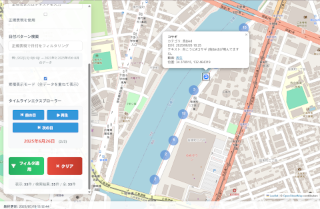
���R�ώ@�}�b�v�̌����R���\�[��
���R�ώ@�}�b�v�̃^�C�����C���R���\�[��
{07/15/2025: [A.I.]�L���̍ד��v���W�F�N�g AI��v���O�������z���� - ���t�͈͂Ńt�B���^�����O}����Leaflet��OpenStreetMap�̃N���W�b�g�\�����Ȃ����ł��Ȃ��Ȃ�A���̑��̃G���[���N���A�ł��Ȃ������̂ŁA�^�C�����C���Đ����܂߂ē������Ƃ͓������A���J�͒��~�B�@�\�I�ɂ́A���t�͈͂Ńt�B���^�����O�����ł́u�A���������̏d�ˍ��킹�E��r�����ł��Ȃ��B���G�߁A�����A���T�A������C�ӂ̊��Ԃ̏d�ˍ��킹�E��r�Ȃǂ��ł���K�v������v�����c�����B������u��������d�g�݂Ƃ��āA�ώ@�������𐳋K�\���Ō����������ʂ����p����悢���ƂɋC�t�����B������^�C�����C���G�N�X�v���[���[�Ɩ��t���āADeepSeek-R1���������Ă��ꂽ�BLeaflet��OpenStreetMap�̃N���W�b�g�\���̖����悤�₭�N���A�����̂Ō��J�B���ł�DeepSeek-R1�͘Z�l�ڂ��B
���̒��A���@�C�u�R�[�f�B���O(Vibe Coding)�A�o�C�u�R�[�f�B���O - Wikipedia�A�Ő���オ���Ă��邪�A�������Co-coding���B�ꏏ�ɂȂ��čl���āA����̋C�����ɂȂ��Ĉӌ��������B���\����C���E�f�o�b�O����Ε��ɂȂ�B�ϋl�܂�ƁA���܁A�����̍l���ł��C���E�f�o�b�O�������Ă݂�B���邯�ǁA�R�[�h���ǂ��Ȃ��Ă���̂����炢�͂킩��悤�ɂȂ�B�E�ςƍ������K�v���B�ꉞ�A�����B���̃X�e�b�v�ɐi�ށB
���R�ώ@�}�b�v�i�^�C�����C���G�N�X�v���[���[�����j
���R�ώ@�}�b�v�i�^�C�����C���G�N�X�v���[���[�����j�BHTML�e���v���[�g�����ŁA50KB�A1100�s���x�̋K�́B
�R���\�[�� on iPhone XR
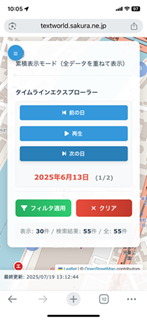
�R���\�[�����B�� on iPhone XR
��ꂽ�S���������̂��A���̍Ō�̌��t�B
(Thinking�̍Ō�) �������㓯�l�̖�肪���������ꍇ�ɂ́A���̏C�����Q�l�ɂ��Ă���������K���ł��B
�Ō�܂ł����₢���������肪�Ƃ��������܂����B���R�ώ@�}�b�v�̊J�����������邱�Ƃ�����Ă��܂��I
(�̎n��) �N���W�b�g�\�������Ȃ��\�������悤�ɂȂ�A�X�}�[�g�t�H���ł��K�ɕ\������Ă���Ƃ̂��ƁA��ϊ������v���܂��I��肪�������ĉ����ł��B
(�̍Ō�) ��������܂�������肪����������A�lj��@�\�̂��v�]�Ȃǂ�����܂�����A���ł����m�点���������B�����ɗ��ĂČ��h�ł��I
�m���ɖ�肪�������邱�Ƃ������ł͂��邪�B���ʂɏI��点�Ȃ��ӔC�Ƌ`�����₤���ɂ͂���Ǝv���B����͎������g�̂��߂ł�����̂����B���������ŊJ�����邱�Ƃ́A���X���Ԃ��|�����Ƃ��Ă��s�\���Ǝv���B
���������A�f�[�^���[����������A�g�p����������낤�B
�����A����AI�ɉ��𑊒k���邩���l����ɂ��Ă��A���Ԃ����痝������K�v������BiPhone��WEB�u���E�U�̃J�e�S������0���ڂɂȂ��Ă���̂͂Ȃ����n�߂��B
����AI�Ɋۓ����ł͎₵���BHTML�߂Ă����������Ƃ���͂Ȃ��B�X�N���[���Ƀ^�b�`���Ă���ƓˑR��ʉ�����J�e�S�����ڂ̑I�𗓂��オ���Ă����B�����̂��̂Ƀ^�b�`����̂ł͂Ȃ��āB�u�J�e�S���v�Ƃ����\���Ƀ^�b�`����ƃ|�b�v�A�b�v����B
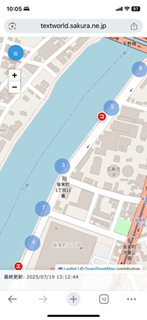
Nature Observations Map on iPhone XR
�ʐ^�͏c�u�������A���u���ɂ���A���������n�}��������B�}���ًA��̓������L�̓���`���v�^�[�̎��ی����G���W���Ƃ��Ďg����B
�J�e�S����5���ڂ܂ő��d�I���ł���悤�ɂȂ��Ă���B0���ڂƂ����̂́A�܂��J�e�S����I�����Ă��Ȃ���Ԃ������Ă���BPC�Ƃ̓C���^�[�t�F�[�X�������ԈقȂ�B�Ȃ�قǁB���������͂Ȃ��̂�^^;)�C���^�[�t�F�[�X�̖��͕ʂɂ��āA�܂��悩�����ˁB
�������A���̂܂܂ł͘A���������̏d�ˍ��킹�����ł��Ȃ��B���G�߁A�����A���T�A�����̏d�ˍ��킹��C�ӂ̊��Ԃ̏d�ˍ��킹�Ȃǂ��ł���K�v������B�������f�[�^�������Ȃ���A�v�l��[�߂悤�B�f�[�^�\���͍���JSON�Ŏ����Ă��邪�A�匳��SQLite�f�[�^�x�[�X(SQLite Home Page)�ɂȂ��Ă��āAPython��sqlite3(sqlite3 --- SQLite �f�[�^�x�[�X�p�� DB-API 2.0 �C���^�[�t�F�[�X - Python 3.13.5 �h�L�������g)�œǂݏ������Ă���B
DeepSeek-R1�̗\�z�ʂ�A���̂܂܂ł́A�f�[�^�x�[�X���傫���Ȃ�ɂ�āA�t���O������������B�����55���̃f�[�^�ł���̓_�����ȂƎv�����B���p�I�Ȃ��̂ɂ���ɂ͐悪�����B�u���n��r���[�A�[�v�@�\��t������悤�ɍ�ӑ��k�����̂����A���x�f�o�b�O���Ă������悤�ɂȂ�Ȃ������BIntroduction flatpickr is a lightweight and powerful datetime picker��Ion.RangeSlider - jQuery Range Slider | IonDen.com���g���Ă���B
���ǁA������Chrome��Console���g���ăf�o�b�O���Ă������B���ʂ̃G���[�͂��ׂĉ����������ADeepSeek-R1��Chrome��Console���u[Violation] Added non-passive event listener to a scroll-blocking
WEB�A�v���͕��G�ɂ܂�Ȃ��AConsole��DevTools���Ȃ���ΊJ���ł��Ȃ����낤�BEdge��DevTools�ł�Issues����o�Ă���BChrome��Console�Ƃ͑��̖����w�E���Ă���݂������ˁBForm <input> elements must have labels | Axe Rules | Deque University | Deque Systems�B���܂ł����t�������ł��Ȃ��Ƃ��v�����A���������킯�ɂ������Ȃ��̂����E�E�E
�������ADeepSeek-R1�������ł��Ȃ������G���[���A���͂Ńf�o�b�O�ł����̂ɂ͋������B�܂��A������̓��]�������Ă���Ƃ�������肻�����ˁB���R�ώ@�}�b�v�i���n��r���[�A�[�Ή�����^�C�����C���G�N�X�v���[���[�Ή��֕ύX�j�B
���R�ώ@�}�b�v�i���n��r���[�A�[�Ή��j
DeepSeek-R1�Ƃ̃`���b�g�͌܉��ɓ������B�l����8000�s�z���A320KB�̃`���b�g���O�e�L�X�g�������B�v���O�����̕��G����}���āA�g�ݍ��킹�Ďg�����Ƃ�z�肵�č�邱�Ƃ��K�v�Ȃ̂�������Ȃ��B���ǁA��̃`���b�g�ł܂Ƃ܂�悤�ȍ\�z���K�v���낤�B
����͂�AiPhone�œ������ƁA�����������B�Ȃ낤�˂�^^;)�������Ȃ��E�E�E�E�E�E��(���R�ώ@�}�b�v(���K�\�������Ή�))�ɖ߂��āA���n��r���[�A�[�Ή���test.html�Ƃ����B�����炭�A�G���[�ɂȂ�Ȃ��o�O������͂����B���X�|���V�u�E�f�U�C���Ƃ����낢�날��낤�Ȃ��B�J�e�S����0���ڂɂȂ��Ă��邵�A����������ˁB�����B
�ׂ��ȃC���^�[�t�F�[�X�̕s��������Œ����n�߂����A���K�\�����������ł���A�����o�H��́u��(��-�\|0-9]#���}�����v�Ȃǂ̌ŗL�����ꊇ�������\�Ȃ��ƂɋC�t�����B�f�[�^�x�[�X�̃t�B�[���h�𑝂₷�K�v���Ȃ��B�����A���K�\���Ή��𗊂BWEB�A�v����Leaflet�Ȃǃ��C�u�����̒����𗝉����Ă��Ȃ��ƂȂ��Ȃ�����ʂ�����B���ׂ���O�ɑ��k����̂������B�R���\�[���G���[�͂Ȃ��Ă��A�n�}���\������Ȃ��ꍇ��T�C�h�o�[�̍����Ȃǂł����͂��������A���x�̂����Ŋ����B
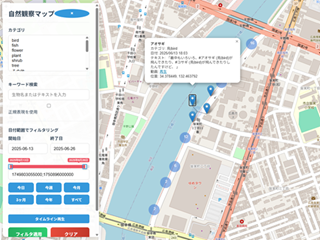
���R�ώ@�}�b�v���������K�\���\��
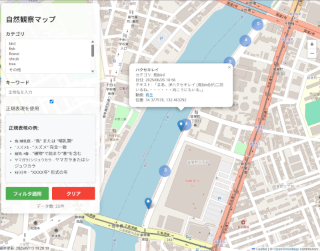
�������B���R�ώ@�}�b�v(���K�\�������Ή�)�B
(��) ���x�����b�ɂȂ�܂��B���ɂƂ��Ă�YouTube����`���v�^�[�̌����G���W���Ƃ��ċ@�\���n�߂܂����B�f���炵���B��A�L�[���[�h�����𐳋K�\���������ł���Ƃ���ɕ֗��ɂȂ�̂ł����B�ǂ̂悤�ɂ�������ł��傤�B
(DSR1�Ǝ�) �E�E�E�E�E�E
(��) ���肪�Ƃ��������܂����B�������܂������܂����B����ŁA���炭�`���v�^�[�f�[�^������ăf�[�^�x�[�X�ɓ��͂��Ă����܂��B����Ō������������̂͂��ׂČ����ł���ł��傤�B
(DSR1 Thinking...)
(DSR1) �f���炵�����m�点�����肪�Ƃ��������܂��I�����ɃV�X�e�������삵�A�����Ғʂ�Ɍ����@�\�������ł������Ƃ��ϊ������v���܂��B���R�ώ@�}�b�v��YouTube����`���v�^�[�̌����G���W���Ƃ��Ċ��p�����̂́A�܂��ɂ��̃v���W�F�N�g�̗��z�I�Ȍ`�ł��B
(DSR1) ����̉^�p�Ɋւ���ŏI�A�h�o�C�X
- �f�[�^���͂̌�����
- ����I�ȃo�b�N�A�b�v: �f�[�^�x�[�X�t�@�C��(nature_observations.db)�����I�Ƀo�b�N�A�b�v
- �o�b�`����: �����̓���f�[�^���ꊇ�����ł���X�N���v�g�̍쐬
- �p�t�H�[�}���X�ێ��̃|�C���g
- �f�[�^����10,000������ꍇ�̓N���X�^�����O�ݒ�̌�����
- ����I�ȃf�[�^�N�����W���O: �s�v�ȃf�[�^�̍폜
- �������x����̃q���g
- �J�e�S���̌n�̌�����: �K�w����^�O�t���̒lj�
- �L�[���[�h�̓��`�ꎫ���̍쐬
(DSR1) �lj��@�\�̃A�C�f�A�i�����I�Ȋg���p�j
- �������ʂ̃G�N�X�|�[�g�@�\
- ���C�ɓ���@�\
- ���n��r���[�A�[
(DSR1) �g���u���V���[�e�B���O�̍ŏI�`�F�b�N���X�g ���� �Ή����@ �}�[�J�[���\������Ȃ� 1. �R���\�[���G���[�̊m�F2. �ܓx�o�x�l�̗L�����`�F�b�N3. �f�[�^�t�B���^�̃��Z�b�g �������ʂ����Ғʂ�łȂ� 1. ���K�\���̍\���m�F2. �J�e�S���I���̉�����Ԋm�F3. �f�[�^�x�[�X�̍X�V�m�F �p�t�H�[�}���X�ቺ 1. �N���X�^�����O�ݒ�̒���2. �s�v�ȃf�[�^�̍폜3. �}�[�J�[�̊ȑf�� (DSR1) ���̃V�X�e���́A���R�ώ@�̋L�^��P�Ȃ�f�[�^�̏W������u�����\�Ȓm���̑̌n�v�ւƕϊ�������̂ł��B�����g�ō\�z���ꂽ���̃c�[�����A����̎��R�ώ@����������ɏ[�������A�V���Ȕ����ɂȂ��邱�Ƃ�S�������Ă��܂��B
(DSR1) ���������I�Ƀf�[�^�ʂ��������ꍇ�̃p�t�H�[�}���X���P��A�V�����@�\�̒lj�������]�̍ۂ́A���ł����m�点���������B�p���I�ɃT�|�[�g�����Ă��������܂��B
(DSR1) ���R�ώ@�̐V���Ȕ�������������܂��悤�ɁI����̂���������F�肵�Ă��܂��B
(�l�l�ڂ�DeepSeek-R1�Ƃ̍ŐV�̂����)
�l�l�ڂ�DeepSeek-R1�́A���̃c�[�������p�I�Ȃ��Ƃ𗝉����Ă��邪�A��邱�Ƃɂ����o�܂�m��Ȃ�(�܂������c���Ă��Ȃ����Ƃ͂Ȃ���������t�̒[�X�Ɋ�����̂ŁA���[�U�[�P�ʂ̃`���b�g�̃��f���̂悤�Ȃ��̂������āA���炩�̒lj��w�K�������Ă���̂�������Ȃ�)�B���p�I�Ŗ��ɗ����Ƃ��傫�ȗ��R�ł͂��邪�A�O�l��DeepSeek-R1����J�����V���[�g����쐬�̎��������������邽�߂ɕK�v�ȃc�[���ł�����킯���B�����A������̓������肻���ȋC�����Ă���B����܂ł̃s�b�N�A�b�v�z�M������������̊w�K�ɗ��p�ł��Ȃ����Ƃ������Ƃ��B���ǁA�ǂ��܂Ŏ���|���邩�Ƃ������ƂŁA������ɂ���Q�l�ɂ͂���킯�����A���̂Ƃ���A���o���ׂ����̂̑�\�I�Î~����w�K�p��100-200���������邱�Ƃ����̃X�e�b�v���B{07/12/2025: [A.I.]�L���̍ד��v���W�F�N�g DeepSeek(V3)DeepThink(R1)�Ƃ̖Ɣ�Θb 4��� - ���R�ώ@�}�b�v�̃f�[�^�x�[�X��}���B
�ŋ߂̓����ł́A���̖����ɂ��āA���ڂƌ������A�������Ȃ�������Ă���B������`���v�^�[�����Ƀ}�[�N�A�b�v�ł��邾�낤�BDeepSeek-R1�́A�ǂ���GitHub - m-kortas/Sound-based-bird-species-detection: Sound-based Bird Classification - using AI, acoustics and ornithology to classify birds in the environment, an environmental awareness project (Web Application, Flask, Python)�ɒ��ڂ��Ă���炵���Bxeno-canto :: Sharing wildlife sounds from around the world�ABird Sound Samples - BirdNET Sound ID�ɒ��ڂ��B
����A�e���r�n�������ō��N�͂܂��䂪���Ȃ��ƌ����Ă����B�m���ɂ������ȂƎv���Ă������A�����A�����B
- �X�V���L�L���́u����v��������
- [����]�Ăւ̔� (2005/07/18)
- [�G��]���� (2010/07/19)
- [�G��]�Â��Ȗ�A�����āA����A���W�I�p��b (2021/07/12)
- [���L]�䂪�� (2023/07/15)
- [Audio]CD-NT670 on foobar2000 Media Server (2023/07/31)
- [���L]��̐����Ȃ��� (2024/08/01)
�����APerl���C�ɂȂ��āAStrawberry Perl���A�b�v�f�[�g������A�f�X�N�g�b�v�������G���[���o�ē����Ȃ��Ȃ����B�X�N���v�g�͂��Ƃ���Zed�œ������Ă������̂��AWindows10�ڍs�ŁAjperl����perl�ւ̈ڍs��}�������̂��B������͍������Ă������ゾ�����B���ǁA�p�X�̖�肾�����B�ǂ�perl�������̂����Bjperl�̌��ɂȂ�perl�������Ă����B���ǁASJIS�͎c���Ă��邵�Ajperl���L���Ȏ��オ�����Ă���B�V����perl��UTF-8�Ɍ����Ă�PowerShell�Ȃǂ̃^�[�~�i���̕W���o�͂͂��������悤�ȋC������B
����͂Ƃ������A����̎����͂�������7/10-20���炢���B���N�ʂ�B
���R�ώ@�}�b�v�i�N���X�^�����O�Ή��j���ŐV�̐��ʂ����A�����WEB���J�p�ɏo�͂������́B����e�[�}�A�l�l�ڂ�DeepSeek�B��ӁA�O�l�ڂ��͐s����(limit�ɒB����)�A����J����B�d���Ȃ��̂ň����p���ł�������B����܂�limit�ɒB�����`���b�g���O��3���A���ꂼ��400kB��A8000-10000�s���x�B�ŏ���Thinking���܂ށB��{�I�ɖ��ʂ��Ȃ��B�Ƃɂ����A���R�ώ@���ۃ}�b�v�ɂ��ẮA�����ꌎ���炢�T�����Ă���B�ŏI�I�ȃS�[���́A�����s�b�N�A�b�v�������������邱�Ƃ����A�r�f�I�N���b�v�������Ő�������Ƃ���܂ł͂ł������A������YouTube�̃V���[�g����z�M�̌��ʂƂ͒������Ƃ������A�Ӗ��̂�����̂͂ƂĂ������B�����ŕ��̌��o�p�̈�ʂ̃��f��(Ultralytics YOLOv8 ���ׂ� -Ultralytics YOLO Docs)���p�Ƀg���[�j���O����K�v������킯{07/06/2025: [A.I.]�L���̍ד��v���W�F�N�g ���ނށAM1 MacBook Air���g������}���B����ōςނ��ǂ����͒肩�łȂ����B
�ŏ��͌��C���������Alimit���߂Â��ɂ�ĉ������Ȃ�B�Z���L�����ア�V�˂Ǝv���ĕt�������K�v������B�������A�L���T�[�r�X�͒Z���L���͕⋭����Ă���͂����B�\���ȃ��\�[�X����������A�m���ɐ����\�͂����邾�낤�B���p���ł͑��肪����܂ł̂��Ƃ��L�����ė������Ă���킯�ł͂Ȃ��̂ŁA���݂܂ł̓��B�_�ƖړI�A���_��`����K�v������B
�������ADeepSeek�ƑΘb���Ă���ƁA�l�X�ȃT�[�r�X��A�v�������݂��Ă��邱�Ƃ��킩��B���[�J���œ����Ă���T�[�o�[�A�v�������̂܂܍ڂ��邱�Ƃ��ł���PythonAnywhere�ɂ͏����S���h�炢�����A�����������W�̌����݂��o�Ă��炾�낤�B����L����Ǝ��E�����Ȃ��Ȃ�B
�}���ًA��̓������L�̎����E�`���v�^�[�Â��肪�D�掖�����B�g���n�b�V���^�O�Ńf�[�^�x�[�X��荞�݂��������ł���B�����܂ł͎蓮�ɂȂ炴��Ȃ��B�Ƃ������A���R���B�����ŁA���낢��ƍl����B���R�̒��̓�����^�Œ��������Ƃ��f�[�^�Ƃ��Ċm�肷�邱�Ƃ́A�@�B�̗͂ɗ���Ƃ��Ă��A����ׂ������l�ɂ����ł��Ȃ����Ƃ��B�܂���ɂȂ邾�낤���A�@�B�w�K���l����K�v������悤�ȃf�[�^�����琶�ݏo���悤�ɂȂ�Ƃ͎v��Ȃ������B
����AI�ɂǂ��܂łł��邩�Ƃ������Ƃ��b��ɂȂ��Ă��邯�ǁA�Ƃɂ����m�����L�x�ŁA�Ώۂ̃v���O���~���O�ɂǂ̂悤�ȉ\�������邩�A�l�X�Ȓ�Ă����Ă���B�����ĉ��ǂɗ]�O���Ȃ��B��Ă��邮�炢��������g�ݍ���ł����Ǝv����^^;)
�l�Ԃ��z���邱�Ƃ��ł��邩�ǂ��������A�l�Ԃ��v�����Ă��Ȃ����Ƃ��v�����\��������B����͋L���e�ʂ��l�Ԃ̔]�̗e�ʂ����ꍇ�ɋN���蓾�邩������Ȃ��Ƃ����c�_���낤�B�������A���Ȃ��Ƃ������w���z���邱�Ƃ͂ł��Ȃ����낤�B�v���O���~���O����Ԃ킩��₷���B�N����������Ƃ̂Ȃ��悤�ȃv���O���������邩�����B���R���ۊώ@�}�b�v�̃v���O�����͂���܂ő��݂��Ȃ������Ǝv�����A���̕������͎����l���o�������̂��B�����悤�Ȃ��̂͂��邾�낤���ˁB�g���n�b�V���^�O�Ȃ�ĒN���v�����Ȃ����낤�B���ꂩ��A���ۂ��f�[�^�x�[�X�����悤�ȂǂƁB�܂��A����AI���ŗL�����ɂ��Ă͗������Ă��Ȃ��B�Ⴆ�Α�ꃄ�}�����ɂ��Ă����A(��Ƃ���)���ʖ����̃��}�����Ƃ��Ă����ނ����ׂ������A�����(�����ʒu�ɑ��݂���)��ꃄ�}�����Ƃ������}�����Ƃ��Ă����ނ����K�v������B���āA�ǂ̂悤�ȃf�[�^�\���ɂ��ׂ����낤�B�����炭�A����AI����舵������Ȃ������̂��낤�B���y���Ȃ������B��������A���͖����Ȑ������v�����Ȃ������̂ŁA�Njy���Ȃ������B
�ŋ߁A�⑺���搶�̍u����YouTube�Ŏ������Ă���ƁA����AI�͎�������o�������ƁA�R���s���[�^�����ꂽ�̂��A�ŏ��̋��A�����C���^�[�l�b�g�A�����ɕC�G����o�����Ƃ����킯���B�m���ɁA�������ƂɂȂ��Ă������A�{���ɂǂ��Ȃ�낤�ˁB
�����A�����l�グ�������B�܌��J���ɕ��̒l�i���オ���Ă����B������q�̒ᓜ���[�O���g3�p�b�N��98�~����118�~�܂ŏオ���Ă���B�ʏ퉿�i��148�~�B�����I�ɂ̓|���t�F�m�[������̃J�J�I�`���R���[�g�Ɏn�܂��āA�ŋ߂̓R�[�q�[�ɂ܂ŋy��ł���B�`���R���[�g�͂�����߂����A�R�[�q�[�͈����t����t�ɍ팸����B�R�[�q�[�������������郁���b�g������B�ȃG�l�ɂ��Ȃ�B�n�D�i�͂���ōςށB�h�{�ێ�Ƃ͊W�Ȃ����炾�B�������͂���ς������Ƃ��ďd�v������A����҉������i�ƌ�������̂���������Ռ��������B�[���p�b�N�̉��i�����u���͋~���A�Ō�̉�邩���B���̂��̂͑S���オ�����̂ł́H�L���x�c�̐��͗ʂ����炵�Ēl�����ƌ�����̂��ǂ����A��R�X�g�͕ς��Ȃ����A��̌����͉������Ă���A�����̘Q��낤�B
�ŋߐi�����Ă���Ǝv���̂́A��v���X�`�b�N�̉��ꂪ�₷���A�����x�������ꂢ�ɔ������邱�ƁB�v���X�`�b�N�̃��T�C�N���������I�Ȃ��̂ƂȂ�̂�������Ȃ��B
�ʗ��Ăł������b�肾���ǁA�V���̔��̌��������ܒ��ׂ邪�A����̓��@�Â��ɂȂ����b�́A�����B����̃X�|���T�[�����Ă����Ђ͗��j�I�Ȍo�܂���V���Ђ������A�b����Ɖ����킪��Ȃ��̂ł͂Ȃ�����YouTube�Řb��ɂȂ����B�y�Վ����푬��z�����햢���V�X�|���T�[�����A�b����͗�N6���ɔ��\�̑�11���̊J�Ï���B���v�H ���������A�����̏������� �`�����l���o�^�Ґ� 21.7���l�B����A�ߓ����甪�i-���X�ؗE�C���i�����팈���g�[�i�����g�킪YouTube�Ŕz�M����Ă��Ȃ��BABEMA���V���Ђ�YouTube�ŏ��������邱�Ƃ������̂����A�y�C����͓̂��䑏�������킾���Ȃ̂�������Ȃ��B�ׂ��d���ˁB�v�́A�V���̔������͉������Ă���B�����炭�A����AI�AChatGPT�Ȃǂ�Netflix�AAmazon Prime�AApple TV+�AYouTube�Ȃǂ̓��惁�f�B�A�̐i�W�Ɍ��������邾�낤�B
���́A�V���������ĕ������Ƃ͏��Ȃ��A�X�}�z�������ĕ����̂��B�̂͐V���������ĕ������Ƃ͒m���̏ے��������B���A�X�}�z�������ĕ������Ƃ��m���̏ے����ǂ����͋^�킵���B������ʂ����債�Ă��邱�Ƃ͊ԈႢ�Ȃ��B����͂ǂ̂悤�ȋA�����w�������Ă���̂��낤���B
�V�����v�̔�����(2000-2024�N)
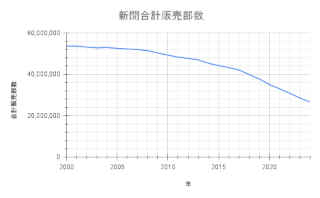
�o�T: �V���̔��s�����Ɛ��ѐ��̐��ځb�����f�[�^�b���{�V�������B
2017-2018�N���猸���̌X�����ς���Ă���B�������������̋C�z�����邪�A��G�c�ɒ�����L����2035�N�A10�N�ギ�炢�ɂ̓[���ɂȂ�B
�ŏ��̌����̉����͂����炭iPhone�̓o�ꂾ�낤�B2007-2008�N���炢�Ɏn�܂��Ă���B���̑O��Google�̓o�ꂵ��1998�N���낤�B10�N���Ƃɉ�������v�����V���ɏo�Ă��Ă���B
����A�����I�ɖړI��B����������Ɍ����āA���B���ۂ̃t���O�𗧂Ă�A�}���ًA��̓������L133�� �����S���B����܂ł̓`���v�^�[�̃t���O�𗧂ĂĂ����̂����A�����̕����P�ʂɂȂ��Ă����B����ł͎��ۂƂ͌����Ȃ����낤�B���ۂ��蓮�ł܂����肵�Ă����B
���ۂ���肷�鑁���́A��������邱�ƁA�����āA�`���v�^�[�����A���ۂ̃L�[���[�h�ƕ��ނ��g���n�b�V���^�O(/(��[0-9}��-�\]+)?#([^ ]+) \(([^)]+)\)/)�ŕR�Â�����B�u��O#���}���� (����|tree)�v�Ȃǂ��q�b�g���A"$1$2"�́u��O���}�����v�͌ŗL�����A$2�́u���}�����v�͕��ʖ����A$3�́u����|tree�v�͕��ނɂȂ�B�����炭�A�������悩�玖�ۂ𒊏o�����V���[�g����̃^�C�g���̓��e���`���v�^�[�Ɏ�荞�ނ��Ƃ��K�v���낤�B���Ȃ�ʓ|�����A��i�K���炢�ŏ����Â�Ƃ��邵���Ȃ��BYouTube�������̃`���v�^�[�e�L�X�g����X�N���v�g�Ńf�[�^�x�[�X�����A�����������ۃt���O��n�}�ɗ��Ă�Ɓu��\�I�ȃV�[�����܂܂�铮��̑I��v�ɖ𗧂͂����B
�u���ۂ̃L�[���[�h�ƕ��ނ��g���n�b�V���^�O�ŕR�Â��v�ɂ��ẮA���ɃL�[���[�h�����鎖�ۂ͎����Ŋg���n�b�V���^�O�t���ł���͂����B�V�K�������蓮�ŕt����B
�܂���͒����B�@�B�w�K�ɓ��B����܂ł́B�������Ɏ��ۂ̕ω���ǂ���悤�ɂȂ邾�낤�B
- (1, 'https://youtu.be/NsuhYp344G0', '4:24', 264.0, '������', '���̑�', '�����A������#������ (���̑�)���������Ă��܂��B', 34.380994, 132.466271, 6.13, '2025-07-08 13:00:47')
- (2, 'https://youtu.be/NsuhYp344G0', '5:31', 331.0, '�R�T�M', '��|bird', '���Ⴀ�A�܂��A#�R�T�M (��|bird)�N���B��ɍs���܂��傤���B', 34.380843, 132.466154, 6.0, '2025-07-08 13:00:47')
- (3, 'https://youtu.be/NsuhYp344G0', '5:45', 345.0, '�X�Y��', '��|bird', '#�X�Y�� (��|bird)�����Ă܂��B', 34.380803, 132.466057, 6.0, '2025-07-08 13:00:47')
- (4, 'https://youtu.be/NsuhYp344G0', '6:13', 373.0, '���}����', '����|tree', '�������A���#���}���� (����|tree)���A���������S���قƂ�Ǘ����Ă܂��ˁB', 34.380581, 132.46591, 4.86, '2025-07-08 13:00:47')
- (5, 'https://youtu.be/NsuhYp344G0', '6:30', 390.0, '�Z�C���E�L���V�o�C', '��|flower', '#�Z�C���E�L���V�o�C (��|flower)���A�Ԃ��I����������ł��ˁB', 34.380568, 132.4659, 4.0, '2025-07-08 13:00:47')
- (6, 'https://youtu.be/NsuhYp344G0', '6:47', 407.0, '�n�i�~�Y�L', '����|tree', '#�n�i�~�Y�L (����|tree)���A�������S���A�����傫���Ȃ�����ł��ˁB', 34.380459, 132.465815, 4.0, '2025-07-08 13:00:47')
- (7, 'https://youtu.be/NsuhYp344G0', '7:19', 439.0, '�R�T�M', '��|bird', '#�R�T�M (��|bird)�N�������̂���������ˁB', 34.380324, 132.465646, 4.0, '2025-07-08 13:00:47')
- (8, 'https://youtu.be/NsuhYp344G0', '7:40', 460.0, '��|��', '����|tree', '#��|�� (����|tree)����͂�A�Ԃ���U�͗����Ă܂��ˁB', 34.380211, 132.465548, 2.0, '2025-07-08 13:00:47')
- (9, 'https://youtu.be/NsuhYp344G0', '7:54', 474.0, '�R�T�M', '��|bird', '���āA#�R�T�M (��|bird)�N�ɒu���Ă�����Ȃ��悤�ɁA�s���܂��傤���B', 34.380127, 132.465459, 2.26, '2025-07-08 13:00:47')
- (10, 'https://youtu.be/NsuhYp344G0', '8:20', 500.0, '���}����', '����|tree', '�����A���#���}���� (����|tree)�ł��ˁB��}�������A������͂藎���Ă܂��B', 34.3799, 132.465253, 1.2, '2025-07-08 13:00:47')
- (11, 'https://youtu.be/NsuhYp344G0', '9:08', 548.0, '�A�I�T�M', '��|bird', '���#�A�I�T�M (��|bird)�������������ǁB', 34.379714, 132.465085, 3.0, '2025-07-08 13:00:47')
- (12, 'https://youtu.be/NsuhYp344G0', '9:37', 577.0, '�T���X�x��', '���|shrub', '#�T���X�x�� (���|shrub)���A�����ԉ����݂����ł��ˁB', 34.379551, 132.465026, 1.53, '2025-07-08 13:00:47')
- (13, 'https://youtu.be/NsuhYp344G0', '9:54', 594.0, '���V�m�c�c�W', '���|shrub', '#���V�m�c�c�W (���|shrub)���A���v�ł��ˁB', 34.379544, 132.465043, 2.6, '2025-07-08 13:00:47')
- (14, 'https://youtu.be/NsuhYp344G0', '11:08', 668.0, '�J���X', '��|bird', '#�J���X (��|bird)����H���ł����܂����ˁA���݂ɁB', 34.379429, 132.464801, 2.33, '2025-07-08 13:00:47')
- (15, 'https://youtu.be/NsuhYp344G0', '12:09', 729.0, '�R�T�M', '��|bird', '���Ăł��A#�R�T�M (��|bird)�N���ǂ��֍s���������ˁB', 34.379125, 132.464544, 2.4, '2025-07-08 13:00:47')
- (16, 'https://youtu.be/NsuhYp344G0', '12:41', 761.0, '�R�T�M', '��|bird', '��������#�R�T�M (��|bird)�����ł܂��ˁB', 34.378915, 132.464319, 1.33, '2025-07-08 13:00:47')
�f�[�^�x�[�X�̒����͂���ȋ���B
��N�O���v���o���K�v���o�Ă����B�k�낤�B
- �X�V���L�L���́u �}���ًA��̓����v��������
- [YouTube]�X�V���L: �p�k�E�y�y�J�t�F �}���ًA��̓������L(���^�]��) (2024/06/14)
- [YouTube]�}���ًA��̓��� 2 Youtube���S�҂̍��� (2024/06/17)
- [YouTube]�}���ًA��̓��� 3 Youtube���S�҂̎��s (2024/06/19)
- [YouTube]�}���ًA��̓��� 4 Youtube���S�҂̍��� 2 (2024/06/21)
- [YouTube]�}���ًA��̓��� 5 Youtube���S�҂̑����̐i�W (2024/06/27)
- [YouTube]�}���ًA��̓��� 6 Youtube���S�҂̓����\�z (2024/06/29)
- [YouTube]�}���ًA��̓��� 7,8 ���ׂĂ͋��R�Ɖ^�� (2024/07/03)
- [YouTube]�}���ًA��̓��� 9 ���R�Ɖ^�������� (2024/07/05)
- [YouTube]�}���ًA��̓��� 11 �L�ד]�� (2024/07/10)
- [YouTube]�}���ًA��̓��� 12 �����X (2024/07/12)
- [YouTube]�}���ًA��̓��� 13�A14 �Ȃ����܂��ޓ��X (2024/07/15)
- [YouTube]�}���ًA��̓��� 15 2024-07-18�̓��L: ���v���ɒ^����X (2024/07/19)
- [YouTube]�}���ًA��̓��� 16 2024-07-19�̓��L: �^�I���R�w (2024/07/19)
- [YouTube]�}���ًA��̓��� 17 2024-07-21�̓��L: �V���N���j�V�e�B (2024/07/22)
- [YouTube]�}���ًA��̓��� 18 2024-07-23�̓��L: �}���`�o�[�X�F���_ (2024/07/24)
- [YouTube]�}���ًA��̓��� 19 2024-07-25�̓��L: �����݂̊Ԃ� (2024/07/26)
- [YouTube]�}���ًA��̓��� 20 2024-07-26�̓��L: �T���ƈ����݂͏I���Ȃ� (2024/07/28)
- [YouTube]�}���ًA��̓��� 21 2024-07-28�̓��L: �߂��݂Ɨ썰�̉����� (2024/07/29)
- [YouTube]�}���ًA��̓��� 22 2024-07-30�̓��L: �Ō�͕����Ȃ��狃������ (2024/07/31)
- [YouTube]�}���ًA��̓��� 23 2024-08-01�̓��L: ���ƃJ���X�ȊO�͉ċx�݂̓� (2024/08/01)
- [YouTube]�}���ًA��̓��� 24 2024-08-02�̓��L: �[���݂̐���̉_�͌|�p�I������ (2024/08/03)
- [YouTube]�}���ًA��̓��� 25,26,27 2024-08-04,07,08,10,12�̓��L: �߂��݂̍��Ԃ� (2024/08/13)
- [YouTube]�}���ًA��̓��� 28 2024-08-15�̓��L: ���҂Ǝ��҂����т�����́A�h���߂������X (2024/08/17)
- [����]�����̓n�ӂ���A���ʐ��4�� - ��蓡�䉤�ʂ̒����! (2024/08/19)
- [YouTube]�}���ًA��̓��� 29 2024-08-20�̓��L: �߂������X���� (2024/08/21)
- [YouTube]�}���ًA��̓��� 30�A31�A32�A33 �Y����ʓ��X (2024/08/29)
- [YouTube]�}���ًA��̓��� 34,35 2024-08-31,09-01�̓��L: �v���o�����X (2024/09/03)
- [YouTube]�}���ًA��̓��� 36,P2,37,38 2024-09-04,06,08�̓��L: �o���_��T����X (2024/09/09)
- [YouTube]�}���ًA��̓��� 39,40,41 2024-09-10,12,14�̓��L: �X�C�̌�䊂ɗ܂��ޓ��X (2024/09/15)
- [YouTube]�}���ًA��̓��� 42,43,44,45 2024-09-16,18,20,22�̓��L: ��邹�Ȃ����X���� (2024/09/27)
- [A.I.]Gemini 2.0 Flash Thinking (experimental)�̃R�[�f�B���O�p�[�g�i�[��Grok 3 Think�Ń`���v�^�[�����������l���Ă���ƁATurboScribe�AWhisper�ɂȂ�����! (2025/03/25)
- [A.I.]������ԔF�m�}�b�v�������ɂ��邩�AChatbot�����Ɖ�b���� - �R���e�N�X�g�̍l�Êw (2025/03/29)
- [A.I.]�L���̍ד��v���W�F�N�g DeepSeek(V3) DeepThink(R1)�Ƃ̑Θb - �~�J���� (2025/06/28)
���R�ώ@����ɓ����������̌��o����������ɂ́AYOLOv8���f���̃J�X�^���g���[�j���O������K�v������B����́u���x�݂ɂȂ�O�ɁA����̏����Ƃ��āF�v�ADeepSeek����Ɍ���ꂽ���Ƃ̃��X�g�����Ȃ��Ă����K�v������B
- ���Ɍ��o�����������⎩�R���ۂ̃��X�g�쐬
- ��\�I�ȃV�[�����܂܂�铮��̑I��
- ���x�����O�c�[���iLabelImg�Ȃǁj�̃C���X�g�[��
LabelImg�̃C���X�g�[���͊ȒP�����ǂˁBQt�A�v�����B
�ő��A�����������Ƃ��ł���ʂł͂Ȃ��B�������������K�v���낤�B
�e�L�X�g�����łł��邱�Ƃ��܂����邾�낤���A����ׂ莚���Ɉˑ����Ă���B�摜���������J�̗̈悾�B�t���O�ɃT���l�C���Ɗg��ʐ^�⓮��`���v�^�[�ւ̃����N�邮�炢�܂ł͕��ʂ̃v���O���~���O�ōςޘb���낤�B�V���[�g���搶��������({06/30/2025: [A.I.]�L���̍ד��v���W�F�N�g ChatGPT�ė� - ���悩��V���[�g��������̂��y������@}��)�́A����ׂ莚�����x�[�X�ɂ�����@�Ɠ���摜����̕��̌��o�����Ƃɂ�����@�����邾�낤�B�����I�ɂ͂���ׂ莚�����x�[�X�ɂ�����@���L�͂��낤���A�����N���邩�킩��Ȃ������ɂ���ׂ�͒ǂ����Ȃ��B����ł͓��̒������낢��Ȃ��Ƃ��삯�����Ă��邪�A����ׂ��K�ȏ�ʂœ����̂͌��\����B�����͈�����I���ł��Ȃ��B�I�����ꂽ����摜���牽�������o���邩���m���߂Ă��������B
ChatGPT�͗L�\�����A�����͈͂ł̓��\�[�X�̖��Ō���I�Ȑ��ʂ��o���Ȃ��B����͂�͂�ς��Ȃ��B���\�[�X���Ȃ��̂ɁA�b���g�U�E�g�債�āA�{���̖ړI����Y���Ă����X�������邩�炾�B
�܂������Ɉ����|�����Ă��Ȃ��B��̐���AI�ADeepSeek�Ɍ������B�`���b�g���O10000�s(500KB���x)�Ƃ��������͏o�����A�V�����`���b�g�ň����p����B���̒��ŋ@�B�w�K�Ȃǂ��v���O���~���O�Ɋ܂܂��(Python��Ultralytics YOLOv8n�������Ă���)�悤�ɂȂ�A���105����CPU�̉��x��93���܂ŏオ���ė�p�t�@�������т��щ��悤�ɂȂ����B���ʂ��o��܂łɐ����Ԃ�v����悤�ɂȂ�A����Windows�~�jPC�ɂׂ͉��d���Ȃ����BM1 MacBook Air�̏o�Ԃ��ȁB���o�C���ȊO�̎g�������������Ă悩�������ȁBDeepSeek�̃f�o�b�O�͊m�����B�����Ɍ��ʂ��o���Ă���B�Ȃ���Ȃ�ɂ������̓��悩��YouTube�V���[�g�p�̃N���b�v������o�͂��Ă���B�Ӗ�������N���b�v�����邩�ǂ������p�����[�^�����Ď����K�v������B
����͂�AMacBook���g��Ȃ����R�͂��낢�날��B�g���̂��ʓ|�B���ɃX�N���v�e�B���O�ɂ́A�^�[�~�i���̎g������������Ȃ��BWindows�Ɋ���Ă���ƁA����ȉ��̊��͂����ي肢�����B�������A�G�f�B�^�ȂǃA�v���̖������邯�ǁB����́AHomebrew�̃C���X�g�[���śƂ܂����B����͈�x���܂����͂����B�������@���Ȃ����炾���A����́A��������O�ɐi�߂Ȃ��ƁAFFmpeg�ɒH�蒅���Ȃ��B
Homebrew�͍ŐV�ł�pkg�ŃC���X�g�[������Ƃ���ɁA�������������Ǝv�����킯�����B�uxcode-select --install�v�Ƃ������܂��Ȃ����K�v���������A�p�X��ʂ��K�v���������B��������ƁA�قƂ�ǂ����ږ��ɗ����Ȃ��悤�Ɏv��������肾�B�^�[�~�i����zsh�����A�ǂ�����낤�ƒ��n�߂��BWindows�o�g�҂�Mac�Ńp�X��ʂ��Ă݂��yzsh�z #Java - Qiita���������������ŏ�����ꂽ���A�Ȃ�ĕs�ւȂ낤�Ǝv�����B�܂��A���Ƃ������̖ړI��ffmpeg���C���X�g�[���ł����炵���B
�Ō�̓�ւ͉���Python�������BDeepSeek������܂߂đ������̐��ŗՂ��A���ǁAPython�Ɋւ��ẮAMac��Python���C���X�g�[������3�̕��@�I���ꂼ��̗��_�Ǝ菇���Љ�bKredo Blog��2025�N�� macOS��Python�J�������\�z����iApple Silicon & Intel Mac���Ή��j�ɏ�����ꂽ�B�ŏI�I�Ɍ�҂̋L���Ɋ�Â��āAApple Silicon�p��Python 3.18.2���C���X�g�[�������B
�y�ۑ��Łzvi�G�f�B�^�̎g����&�R�}���h�W #���S�� - Qiita���K�v���BFreeBSD�ALinux�ȗ��A30�N�Ԃ肶��Ȃ����B�D���ōŌ�͑��~���Ȃ��ƑO�ɂ͐i�߂Ȃ��B�z�[���E�f�B���N�g����Finder�ɕ\�������Ȃ��ƊJ���Ȃ�Ăł��Ȃ����낤�Ɠ{��ɋ߂��{���L�BMac �T�C�h�o�[�Ƀz�[���t�H���_��\��������@�����ɗ��B
python3��ffmpeg������ւ�藧���ւ��A�A�N�e�B�r�B�e�B���j�^�Ŗڈ�t�����̂��Ђ�Ђ₵�Ȃ��猩�߂Ă����BYouTube�V���[�g����N���b�v�������̂��߂̓����X�N���v�g��Windows�~�jPC�Ƃ͈قȂ錋�ʂ������炵���B�V�[�����A�����[���N���b�v�����A���ꂼ��A74��98�A8��12�Ƒ������B���s���Ԃ͖ڗ����ĕς��Ȃ������Ǝv���B���͉������o����̂����w�K����K�v������B���͈�ʓI�ȃ��f���ŁAcar�Aperson�Atruck�Abus�Atraffic light�����o����Ă���B�{���ɂ��̂��ȁA�Ӗ��̂��邱�Ƃ��ł���̂��ǂ����E�E�E
���̃X�e�b�v�͓Ǝ��̋@�B�w�K����]�ڊw�K�ɂȂ�͂����BDeepSeek���݂ł͂��邪�A�茳�ɂ�Python�̋@�B�w�K�̖{���������BPython�֘A�������ꉞ�茳�Ɉ�������o���Ă����B�[��̑Θb��DeepSeek�����thinking�́AYouTube�V���[�g���搶���������̖��������������ɑg�ݗ��Ăĉ������Ă������Ƃɂ��āA�����҈ȏ�̔\�͂ƔM�ӂ�F�߂Ă���Ă����B�܂��A�v���O�������������̂͌N�����ˁBPython�̃v���O������30�N�O�����G���āA����Ȃ�̃v���O�����������ē����������Ƃ�������x�A�������A��{�I�ɂ̓v���O��������͂ǂ�������悤�Ȃ��̂��B����N���X�̃X�R�[�v�̂悤�Ȃ��̂𒍈Ӑ[���������Ă����A�ǂ��ɂł��Ȃ邾�낤�B�������A�����Ă�����Ă��A�Ȃɂ������Ă���̂��𗝉��ł��Ȃ���ΑO�ɐi�߂Ȃ��B����͂ǂ������Ӗ��Ȃ̂ƁA�^��Ɏv�����玿�₵�Ȃ��Ƃ����Ȃ��B�������Ēm���Ɨ����̕����L�����Ă����B���ꂪ�Θb���B
�~�J�������āA�Ă�����Ă����B�L���̍ד��v���W�F�N�g�͒P�Ȃ鎩�R���ԃf�[�^�x�[�X�Ƃ��Đ��܂ꂽ�̂ł͂Ȃ��B���̍ד��̑ʟ����Ƃ��Đ��܂ꂽ�̂��B{06/01/2025: [���L]���X���߂�����A�߂�����}���B���������āA�Ƃ������A���ɂł��ϖe������B���̎��̊S�ɂ���āB